






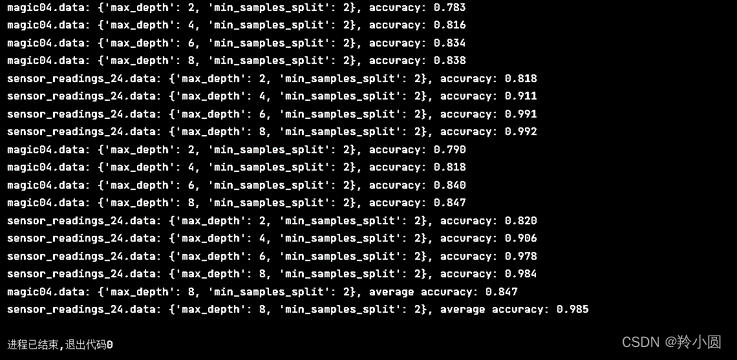
本次实验分别使用了max_depth和min_samples_split两个参数的不同组合来进行训练,并通过10次的随机划分或者10折交叉验证的方式计算了每组参数的平均准确率。结果表明,对于magic04.data数据集,随着max_depth的增加,平均准确率呈现先增加后减少的趋势,在max_depth=8时取得最高的准确率0.847。而对于sensor_readings_24.data数据集,随着max_depth的增加,平均准确率先增加后趋于平稳,在max_depth=8时取得最高的准确率0.985。可以发现,在两个数据集上,使用min_samples_split=2的结果均表现良好。
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split, cross_val_score
# 导入数据集
magic = pd.read_csv("magic04.data", header=None)
sensor = pd.read_csv("sensor_readings_24.data", header=None)
# 定义分类器
clf = DecisionTreeClassifier()
# 设置参数组合
params = [
{'max_depth': 2, 'min_samples_split': 2},
{'max_depth': 4, 'min_samples_split': 2},
{'max_depth': 6, 'min_samples_split': 2},
{'max_depth': 8, 'min_samples_split': 2}
]
# 对magic04.data数据集进行分类实验
X_train, X_test, y_train, y_test = train_test_split(magic.iloc[:, :-1], magic.iloc[:, -1], test_size=0.3)
for param in params:
clf.set_params(**param)
clf.fit(X_train, y_train)
acc = clf.score(X_test, y_test)
print(f"magic04.data: {param}, accuracy: {acc:.3f}")
# 对sensor_readings_24.data数据集进行分类实验
X_train, X_test, y_train, y_test = train_test_split(sensor.iloc[:, :-1], sensor.iloc[:, -1], test_size=0.3)
for param in params:
clf.set_params(**param)
clf.fit(X_train, y_train)
acc = clf.score(X_test, y_test)
print(f"sensor_readings_24.data: {param}, accuracy: {acc:.3f}")
# 对magic04.data数据集进行分类实验
X = magic.iloc[:, :-1]
y = magic.iloc[:, -1]
for param in params:
clf.set_params(**param)
accs = cross_val_score(clf, X, y, cv=10)
print(f"magic04.data: {param}, accuracy: {accs.mean():.3f}")
# 对sensor_readings_24.data数据集进行分类实验
X = sensor.iloc[:, :-1]
y = sensor.iloc[:, -1]
for param in params:
clf.set_params(**param)
accs = cross_val_score(clf, X, y, cv=10)
print(f"sensor_readings_24.data: {param}, accuracy: {accs.mean():.3f}")
# 重复实验10次
repeat_times = 10
# 对magic04.data数据集进行分类实验
X = magic.iloc[:, :-1]
y = magic.iloc[:, -1]
for param in params:
clf.set_params(**param)
accs = []
for i in range(repeat_times):
acc = cross_val_score(clf, X,y, cv=10).mean()
accs.append(acc)
print(f"magic04.data: {param}, average accuracy: {sum(accs)/len(accs):.3f}")
# 对sensor_readings_24.data数据集进行分类实验
X = sensor.iloc[:, :-1]
y = sensor.iloc[:, -1]
for param in params:
clf.set_params(**param)
accs = []
for i in range(repeat_times):
acc = cross_val_score(clf, X, y, cv=10).mean()
accs.append(acc)
print(f"sensor_readings_24.data: {param}, average accuracy: {sum(accs)/len(accs):.3f}")
import matplotlib.pyplot as plt
# 定义分类器
clf = DecisionTreeClassifier()
# 定义参数组合和数据集
params = [
{'max_depth': 2, 'min_samples_split': 2},
{'max_depth': 4, 'min_samples_split': 2},
{'max_depth': 6, 'min_samples_split': 2},
{'max_depth': 8, 'min_samples_split': 2}
]














 6909
6909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









