boss直聘招聘数据爬取及可视化分析2.0 一、需求介绍 二、完整代码 2.1 爬虫代码 2.2 数据可视化模块 一、需求介绍 笔者在前两篇介绍boss直聘招聘数据爬取和可视化分析的博客的基础上,对代码和功能进行了完善。在数据爬取的模块,代码更加简洁易懂,且性能更加稳定;在数据可视化模块,分析角度更加多维,先来看一下可视化图表吧! 二、完整代码 2.1 爬虫代码 im








 超级会员免费看
超级会员免费看
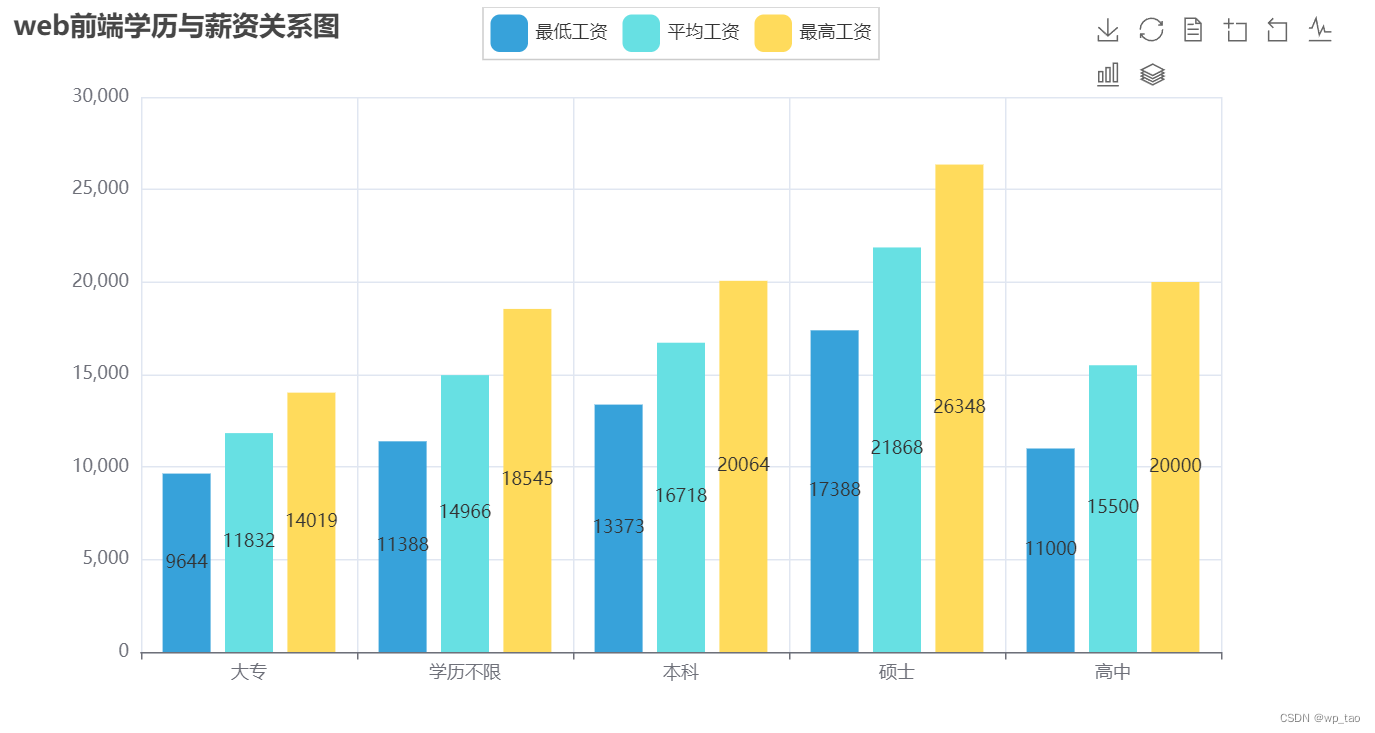
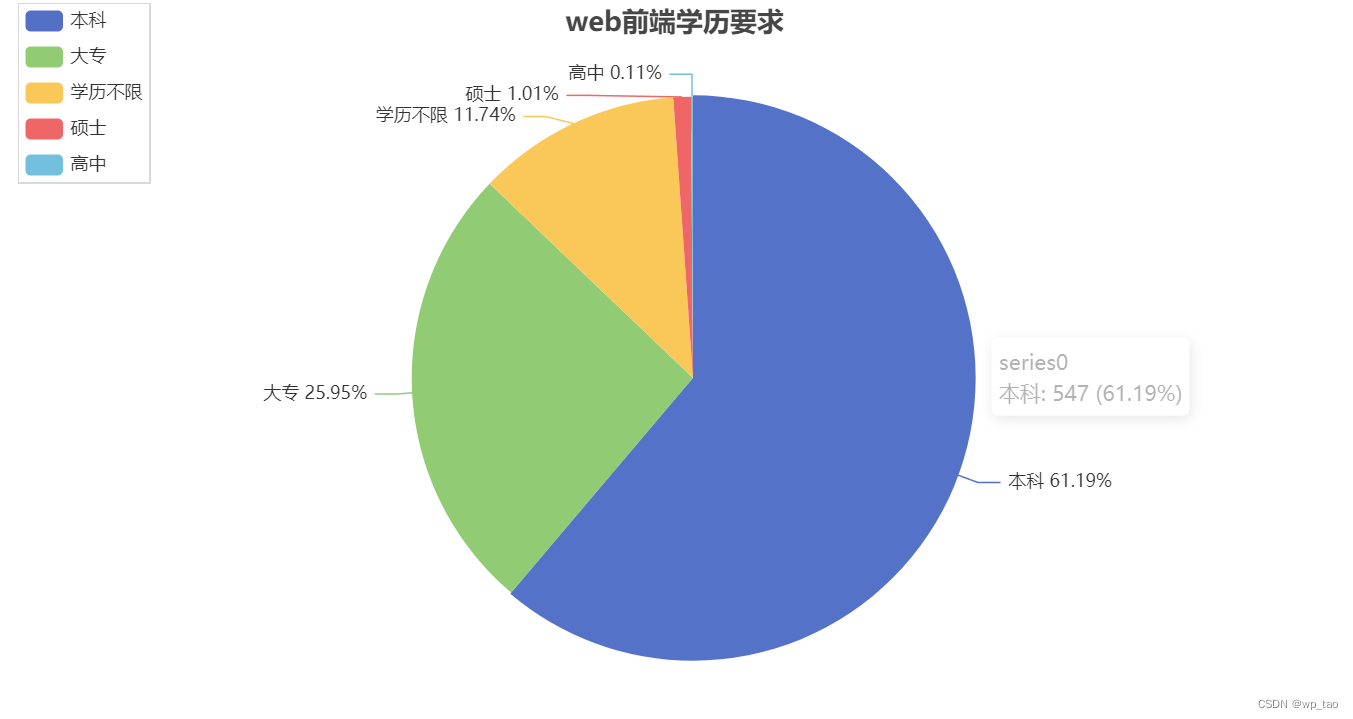
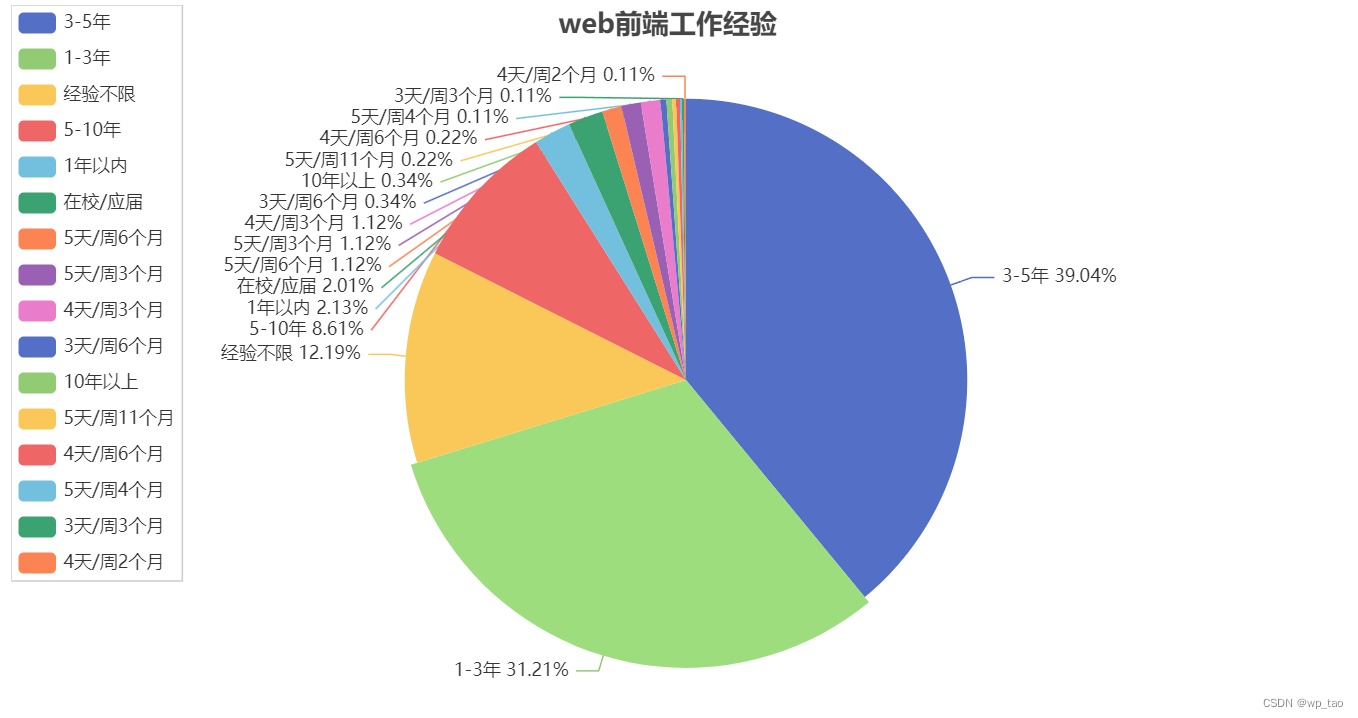
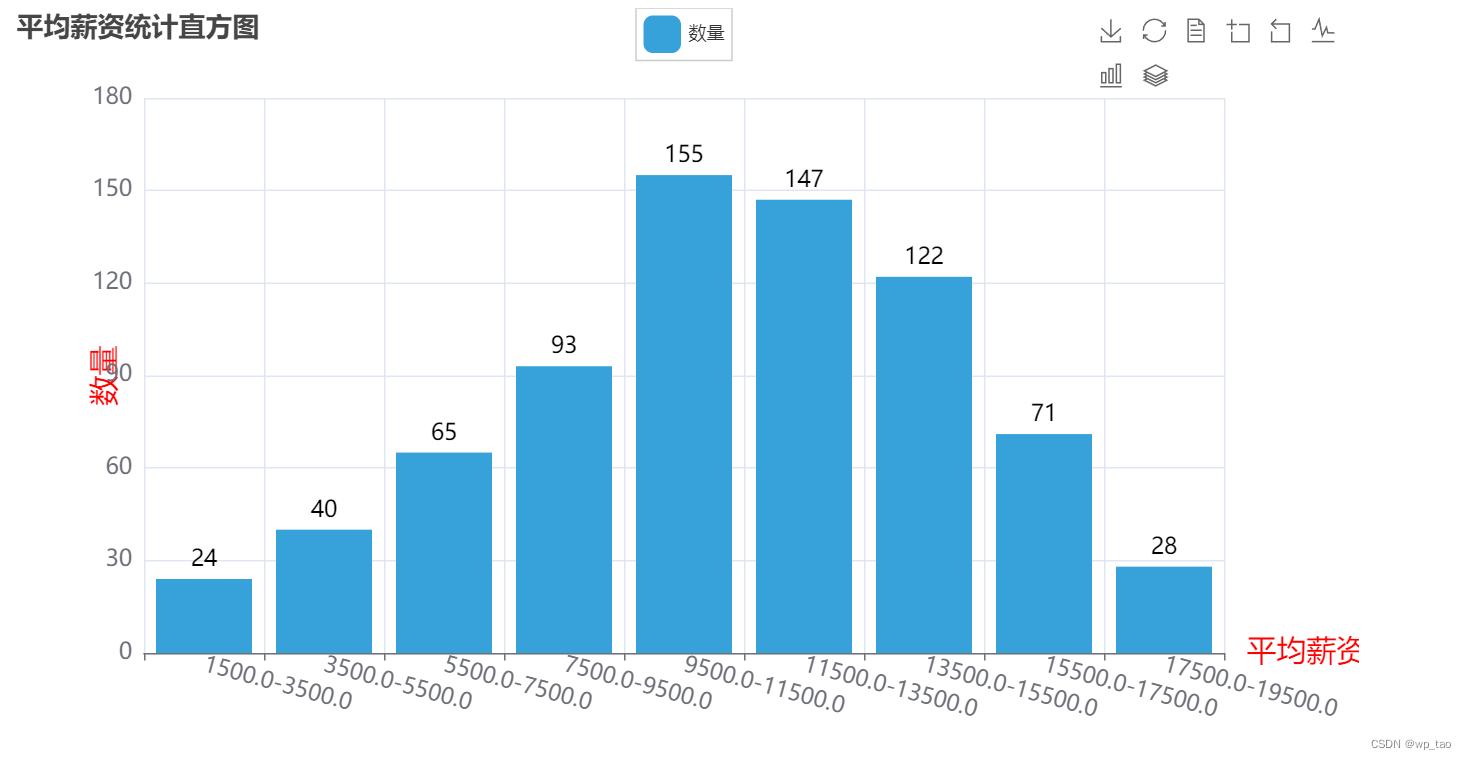

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 1782
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
1782
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






