







摘要
我们发现并攻克了将BERT-style预训练或者图像mask建模应用到CNN中的两个关键障碍:1) CNN不能处理不规则的、随机的掩码输入图像;2)BERT预训练的单尺度性质与convnet的层次结构不一致
对于第一点,我们将没有被mask掉的像素点视作为3d点云(点云是一种方便的3D表达方式)的稀疏体素;使用sparse CNN进行编码,这是sparse CNN首次引入2d-mask建模;对于第二点,我们开发了一个hierarchical decoder来连接不同尺度的编码特征重建图像。
我们的方法:SparK(Sparse masKed modeling),是通用的:它可以直接应用到任何CNN中,不需要修改主干网络。我们在classical(ResNet)和modern(ConNeXt)都做了实验验证:在三个下游任务中,超过了SOTA的对比学习和基于tranformer的masked-base learning(大约提升1%)。在目标检测和分割任务上更是大幅领先(高达3.5%),证明了模型的迁移学习能力
动机
究竟是什么阻碍了BERT应用于convnet ?
典型的NLP模型,如RNN或Transformer,将文本处理为可变长度的单词序列(定义良好的语义单位),而卷积网络必须从原始像素识别不同大小的对象(如不同尺度的“units”)。这种巨大的差异带来了两个挑战:
1)去除被掩盖的“word”的信息对convnets来说很困难。对于ViT,输入图像被划分为几个不重叠的块。简单地删除屏蔽补丁或用屏蔽令牌替换它们就可以删除信息。这种简易性依赖于Transformer能够处理不规则(可变长度)和非重叠的Patch,因此不能在convnets上实现,因为它们不仅在正则网格上操作,而且在重叠的情况下执行滑动窗口。一个可能的方案是:将所有被mask的像素归零,并将这个“mask”输入convnet。但是,这会导致严重的数据分布偏移(如图1所示)和其他问题(稍后在3.1节和图3中讨论),因此不是理想的解决方案。
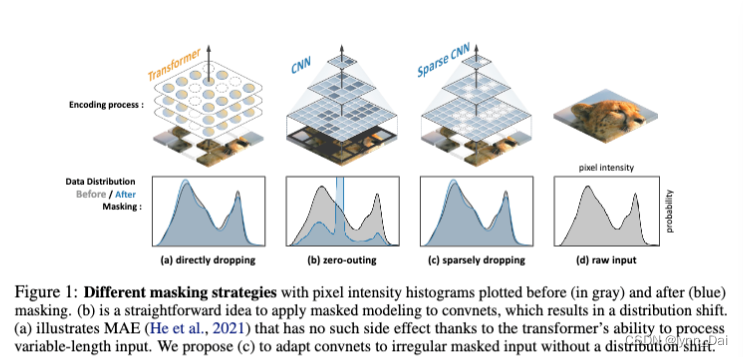
2)单尺度算法无法学习多尺度(分层)特征。 多尺度结构(eg. 如SIFT描述符和金字塔网络)来应对物体尺度的变化。相比之下,NLP的屏蔽建模最初是以单尺度的方式工作的。将其直接应用于convnets将会失去模型层次结构的优势。
贡献点
以patch方式随机mask图像。由于点云的稀疏特性与这些未mask的patch重合,我们将其视为一个平坦的3-D点云,并使用稀疏卷积进行编码。该策略准确地消除了mask部分的信息,同时允许卷积网络轻松地处理不规则的掩码图像。为了解码,我们用mask嵌入填充多尺度特征上的所有空位置,并将它们输入多尺度解码器。这样,我们就可以利用convnet的层次结构的优势。
SparK是一种通用方法,它不限制要预先训练的特定编码器。我们用两个有代表性的convnet家族进行了测试:classic的ResNets和modern的ConvNeXts。所有模型都受益于SparK,在更大的模型上获得了更多的收益,这证明了其良好的缩放能力。
- 第一个BERT-style的预训练方法,可以直接在任何对流网络上使用,无需对主干进行修改,克服了它们无法处理不规则屏蔽输入的问题。
- 为CNN设计生成式预训练的见解,例如,首次使用Sparse - CNN进行掩模图像建模,以及BERT-style预训练的层次设计
- convnet在下游任务中的性能飞跃(高达3.5分),表明有希望将transformer的pretrain-finetune范式的成功扩展到convnet。
方法
SparK框架旨在通过分层mask图像建模对convnets编码器进行预训练——mask图像的一部分并学习恢复它。
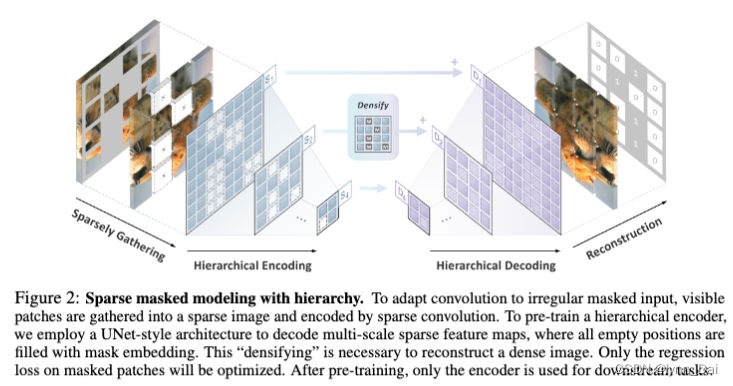
为了使卷积适应不规则的mask输入,将可见patch收集到sparse图像中,并通过sparse conv进行编码。为了预训练分层编码器,我们使用UNet-style的架构来解码多尺度sparse特征图,其中所有空位置都用掩码嵌入来填充。这种“densifying”是重建致密图像所必需的。只有mask patch上的回归损失才会得到优化。经过预训练后,只有编码器用于下游任务。
Sparsely gathering unmasked pathes
mask图像建模算法的关键是如何从这些mask patch中消除像素信息。
直接移除mask patch或者用mask token替代消除信息的缺陷:
1)mask区域的计算是冗余的;
2)它会干扰像素值的数据分布;
3)在对zero-outing mask图像应用若干卷积后,mask图上的pattern会消失
针对问题3)给出解决方法:
我们提出将所有未mask的patch稀疏地聚集到一个稀疏图像中,然后使用sparse conv对其进行编码。这一策略:1)确保没有信息泄露;2)可以直接应用于任何convnet,无需修改主干;3)是有效的,因为稀疏卷积只在可见的地方计算;4)解决了前面提到的“像素分布移位”和“mask pattern消失”问题。如图3所示,稀疏卷积将跳过稀疏特征图上的所有掩码位置,只在未掩码点进行计算。这有助于防止mask pattern的形状随着卷积而改变,从而确保在所有卷积层中具有一致的掩模效果和比例。另一个事实是,当进行微调时,所有稀疏的卷积层都可以自然地简化为普通的dense层。这是正确的,因为dense图像实际上是稀疏图像的特殊情况,没有“holes”。
PS:“稀疏卷积”,我们指的是只在核中心覆盖非空元素时计算的submanifold sparse convolution。
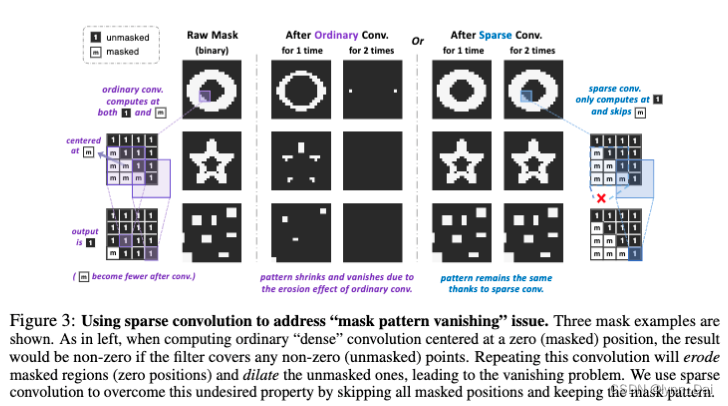
使用sparse conv解决“mask pattern消失”问题。展示了三个掩模示例。如左图所示,当计算普通的“dense”卷积时,如果滤波器覆盖了任何非零(未掩码)点,结果将是非零。重复这种卷积将侵蚀被掩盖的区域(零位置)并扩张未被掩盖的区域,导致消失问题。我们使用sparse conv通过跳过所有掩码位置并保持mask pattern来克服这种性质。
HIERARCHICAL ENCODING AND DECODING
层次编码
解码器遵循UNet的设计














 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









