






🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
OpenAI 正式官宣 o3 & o4-mini:迄今最强模型,AI 终于学会“十八般武艺”全家桶了。
之前传闻的 OpenAI 新“推理模型”正式落地,o3 和 o4-mini 来了,官方自称“迄今为止最聪明、最强大”。直接拉高了 ChatGPT 的能力上限。
这次最大的杀手锏:首次实现 Agent 主动调用并组合 ChatGPT 内部所有工具 —— 网页搜索、Python 数据分析、深度视觉理解、甚至图像生成,全都能串起来用。
关键是,这些模型被训练得懂得何时、如何使用工具,能在通常一分钟内,针对复杂问题给出细致、周到的答案,格式还很对路。
这是向更自主的 Agentic ChatGPT 迈出的一大步,能独立帮你干活了。

有啥不一样?
o3 (全能打手): OpenAI 最强的推理模型,在编码、数学、科学、视觉感知等领域全面突破,刷新了 Codeforces, SWE-bench (还不用专门定制脚手架), MMMU 等多个榜单的 SOTA。
特别擅长处理需要多方面分析、答案不明显的复杂查询,视觉分析能力尤其突出 (图像、图表)。
外部专家评估显示,在困难的真实世界任务中,o3 比 o1 少犯 20% 的严重错误,尤其在编程、商业咨询、创意构思方面表现出色。
早期测试者称赞它作为“思考伙伴”的分析严谨性,以及生成和批判性评估新假设的能力 (尤其在生物、数学、工程领域)。
o4-mini (性价比之王): 更小巧的模型,专为速度和成本优化。性能远超其规模和成本应有的水平,特别是在数学、编码和视觉任务上。
在 AIME 2024 和 2025 数学竞赛基准上表现最佳。专家评估也显示,它在非 STEM 任务和数据科学等领域也优于前代 o3-mini。因为效率高,o4-mini 的调用额度比 o3 高得多,适合需要大量推理的高并发场景。
外部专家还评价说,这两款模型指令遵循能力更强,回答更有用、更可验证 (部分归功于网页搜索的引入)。而且,它们对话起来感觉更自然,会参考记忆和之前的对话,让回复更个性化、更贴切。
AIME 竞赛数学: o4-mini (92.7%) > o3 (91.6%) > o3-mini (87.3%) > o1 (74.3%) (不使用工具)
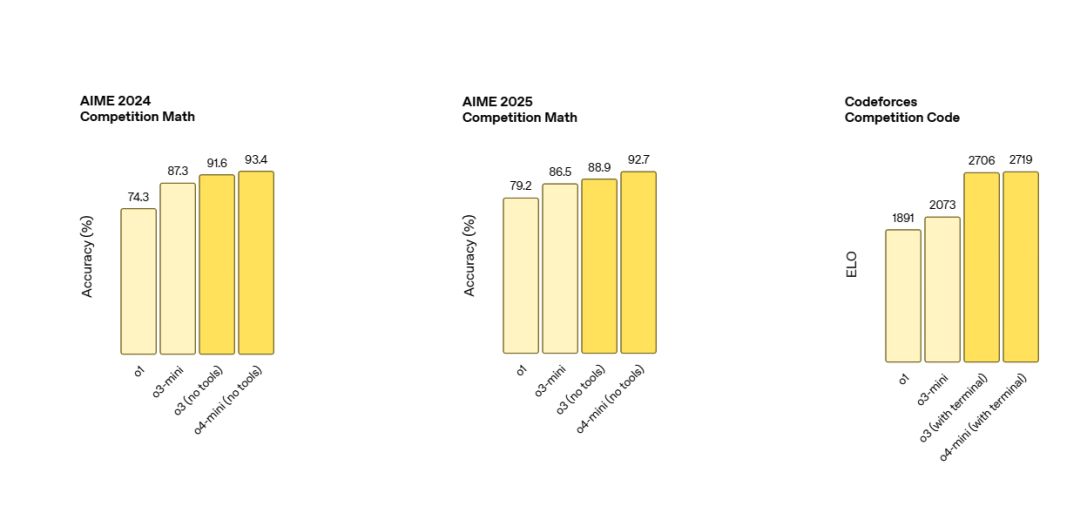
Codeforces 竞赛编程: o4-mini (ELO 2719) ≈ o3 (ELO 2706) >> o3-mini (2073) > o1 (1891) (带终端)
GPQA Diamond (博士级科学问题): o3 (83.3%) > o4-mini (81.4%) > o1 (78.0%) > o3-mini (77.0%) (不使用工具)
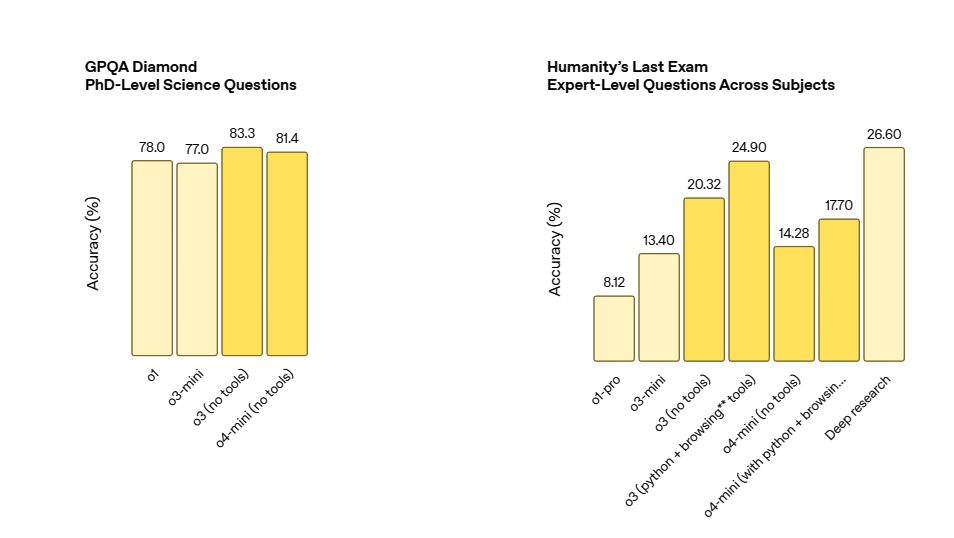
Humanity’s Last Exam (跨学科专家级问题): o3 (带工具 24.9%) > o3 (无工具 20.3%) > o4-mini (带工具 17.7%) > o4-mini (无工具 14.28%)
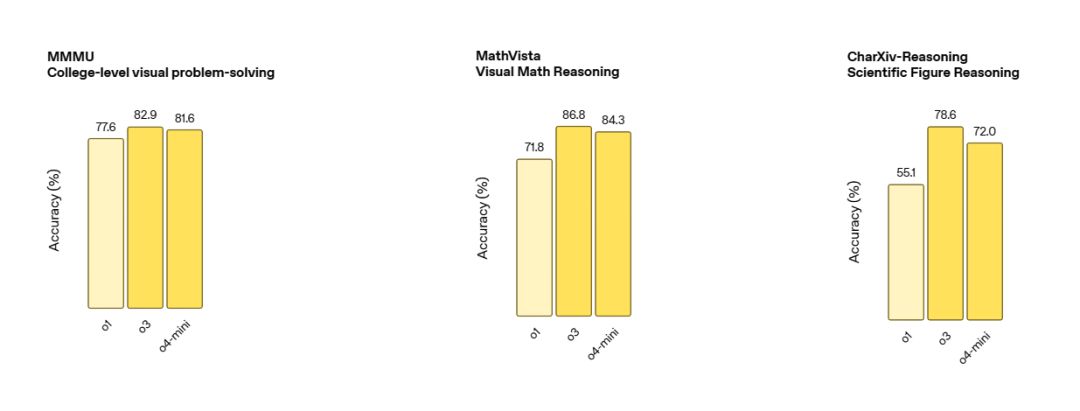
MMMU (大学级视觉解题): o3 (82.9%) > o4-mini (81.6%) > o1 (77.6%)
MathVista (视觉数学推理): o3 (86.8%) > o4-mini (84.3%) > o1 (71.8%)
SWE-Bench Verified (软件工程): o3 (69.1%) ≈ o4-mini (68.1%) >> o3-mini (49.3%) ≈ o1 (48.9%)
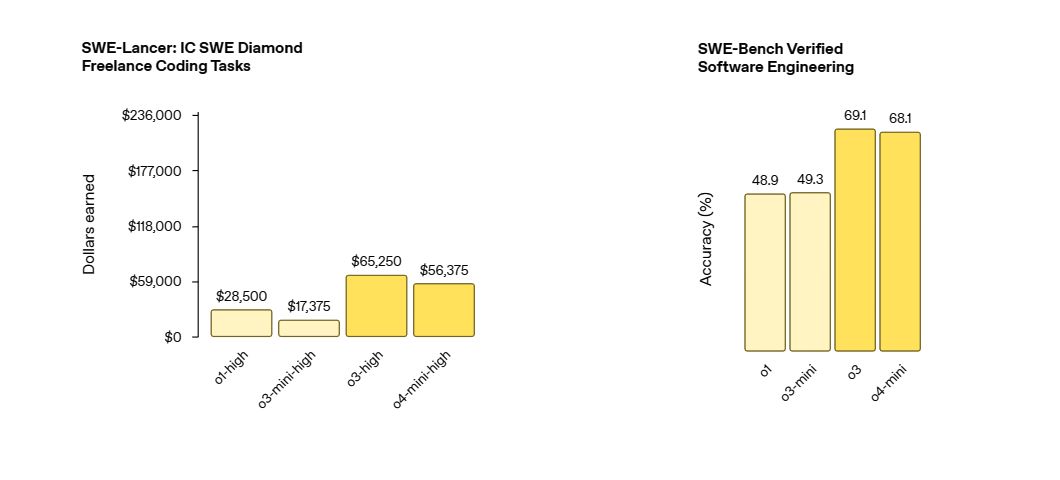
BrowseComp (Agentic 网页浏览): o3 (带工具 49.7%) >> o4-mini (带工具 28.3%) (这里 o3 优势明显)
(注意:所有模型都是在高“推理努力”设置下评估的,类似 ChatGPT 里的 'o4-mini-high' 版本)
模型能力提升的背后:继续死磕强化学习 (RL)
OpenAI 发现,大规模强化学习和 GPT 预训练一样,遵循“砸更多计算 = 性能更好”的规律。通过在 RL 上投入更多训练计算和推理时间,模型的性能持续提升。
即使在与 o1 相同的延迟和成本下,o3 在 ChatGPT 中表现也更好;如果让它思考更久,性能还会继续爬升。
工具使用也是通过 RL 训练的——不光教模型怎么用工具,更教它们判断何时该用。这让它们在开放式场景下 (尤其涉及视觉推理和多步骤工作流) 更强。
医学大佬狂欢 OpenAI o3:接近天才水平,永不幻觉,将彻底改变科学和医学。
医学教授 Derya Unutmaz 博士极度看好。

他的评价:
智力水平堪比天才: “我感觉 o3 的智能水平达到或接近天才级别!”
“永不幻觉”: 这是个非常大胆的断言,当被问及如何验证时,他表示这是基于他大量高难度复杂问题的测试经验。
Agent 能力强悍: 新的 Agent 工具能轻松处理多步骤任务,推理和精度惊人,还能按需生成复杂、深刻、基于科学的假设。
医学问答堪比顶级专家: 扔给 o3 挑战性的临床或医学问题,回答精准、全面、有理有据、非常专业,就像直接跟该领域的顶级专家对话。
明确优于 Gemini 2.5 Pro: 他认为在这些方面,o3 明显比当前的 SOTA 模型 Gemini 2.5 Pro 更强、更智能。
“Total game-changer”: 毫不犹豫地断言,这对科学、医学乃至其他许多领域都是“彻底的游戏规则改变者”。
对于o4-mini-high:
虽然比 o3 略显“谦虚”、细节少点,但在很多方面也很出色,有时甚至更“优雅”,甚至有点“情绪化”(他表示很难描述,会提供例子)。
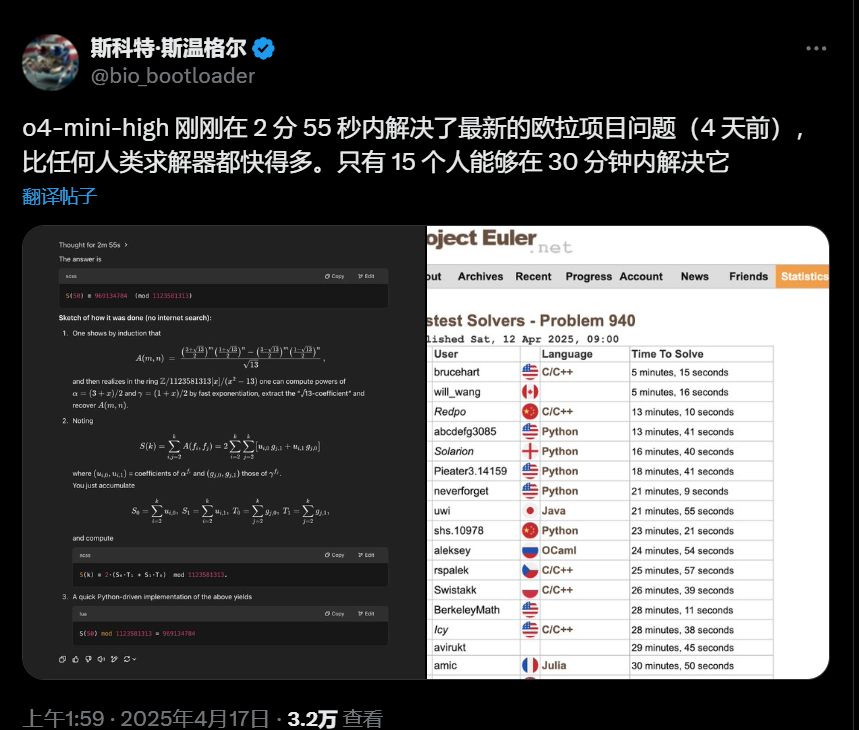
▼ o4-mini-high解决另外一个艰难问题。
社区反应 & 延伸讨论:
o3 vs o1 Pro? 有人直接问 o3 是否比之前的 o1 Pro 更好,Derya 教授斩钉截铁地回答:“是!”
对医学界的颠覆? 有人评论说,那些主要依赖知识和智力的医学领域 (如初级保健、非介入性专科) 几年内将彻底改变,Derya 教授也表示同意。
“永不幻觉”引发质疑: 这个说法过于绝对,引来了不少质疑,希望看到更硬核的证据。
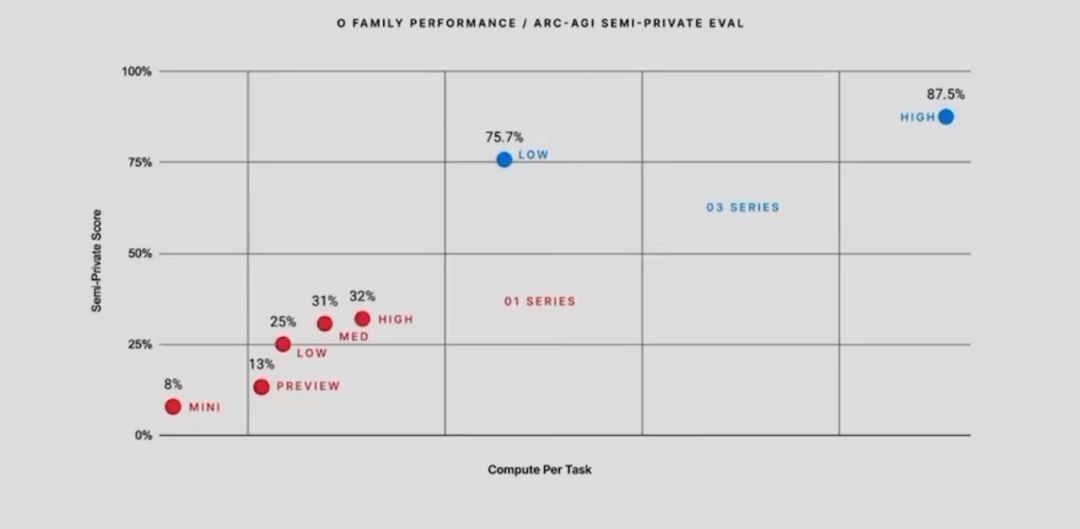 提醒: 目前推出的 o3 在 ARC-AGI 上的得分已超过 87.5% 人类的表
现为 8
5%;;AI 已经“解决”数学了?大佬断言 OpenAI o4 完成壮举,影响远超想象:
提醒: 目前推出的 o3 在 ARC-AGI 上的得分已超过 87.5% 人类的表
现为 8
5%;;AI 已经“解决”数学了?大佬断言 OpenAI o4 完成壮举,影响远超想象:
AI 领域知名 KOL David Shapiro 断言:AI 已经 解决了 数学。就是 OpenAI 用 o4 干的。
 他强调,不是“接近解决”,不是“有竞争力”,是 *解决*。这事儿的影响,比所有人意识到的都要大。
为啥这么说?逻辑链条是这样的:
AI 发展规律: 通常 AI 搞定一个问题 70-80% 的时候,就说明快要完全泛化了。但从 80% 到 99% 这最后一公里往往极其困难。
OpenAI 的惊人速度: 从去年 9 月 o1/o3 发布到现在,才 8 个月,OpenAI 就跨越了这“最后一公里”。这研发速度太吓人了。
超越 Benchmark 的意义: 这不只是刷榜。这意味着每个人的口袋里、每个团队里,都塞进了一个世界级的数学家。
数学是万物基石: 这玩意的直接后果很明显——任何需要数学的领域,这个半自主的 AI 系统都能搞定,或者只需要一点点指导。
他举了个朋友搞计算流体力学 (CFD) 的例子,以前用推理模型还得专家指导,现在可能直接被 o4 "核平 (nuke)"。
二阶及后续影响难以估量:
加速 AI 自身研究: AI 研究本身就依赖数学和代码,而 o4 恰好在这两方面都强到逆天。加上它更强的自主性 (需要更少人类指导、监督和纠错),能处理更大更长的问题,AI 发展将自我加速。
颠覆所有数学密集型领域: 生物化学、机器人、航天、密码学、核物理、区块链…… 全都要被改写。
工具简单到离谱: 更牛逼的是,o4 搞定这些,主要就靠一个工具:Python。不是一堆复杂工具,不是 MatLab,不是超算。
未来已来: 这意味着你的智能手机很快就会变成数学、编程、语言学…… 等等等等领域的天才。后续的三阶、四阶、五阶影响,怎么高估都不过分。
科幻照进现实: 钢铁侠在厨房里搞定时间旅行?这就是 o4 再迭代一两代就能达到的 AI 数学水平。曲速引擎如果可行,这些机器会帮我们搞定它。
他强调,不是“接近解决”,不是“有竞争力”,是 *解决*。这事儿的影响,比所有人意识到的都要大。
为啥这么说?逻辑链条是这样的:
AI 发展规律: 通常 AI 搞定一个问题 70-80% 的时候,就说明快要完全泛化了。但从 80% 到 99% 这最后一公里往往极其困难。
OpenAI 的惊人速度: 从去年 9 月 o1/o3 发布到现在,才 8 个月,OpenAI 就跨越了这“最后一公里”。这研发速度太吓人了。
超越 Benchmark 的意义: 这不只是刷榜。这意味着每个人的口袋里、每个团队里,都塞进了一个世界级的数学家。
数学是万物基石: 这玩意的直接后果很明显——任何需要数学的领域,这个半自主的 AI 系统都能搞定,或者只需要一点点指导。
他举了个朋友搞计算流体力学 (CFD) 的例子,以前用推理模型还得专家指导,现在可能直接被 o4 "核平 (nuke)"。
二阶及后续影响难以估量:
加速 AI 自身研究: AI 研究本身就依赖数学和代码,而 o4 恰好在这两方面都强到逆天。加上它更强的自主性 (需要更少人类指导、监督和纠错),能处理更大更长的问题,AI 发展将自我加速。
颠覆所有数学密集型领域: 生物化学、机器人、航天、密码学、核物理、区块链…… 全都要被改写。
工具简单到离谱: 更牛逼的是,o4 搞定这些,主要就靠一个工具:Python。不是一堆复杂工具,不是 MatLab,不是超算。
未来已来: 这意味着你的智能手机很快就会变成数学、编程、语言学…… 等等等等领域的天才。后续的三阶、四阶、五阶影响,怎么高估都不过分。
科幻照进现实: 钢铁侠在厨房里搞定时间旅行?这就是 o4 再迭代一两代就能达到的 AI 数学水平。曲速引擎如果可行,这些机器会帮我们搞定它。
这次升级的重头戏:带着图思考
模型首次能把图像直接整合进思考链。它们不光是“看”图,更能“带着图一起思考”。用户可以扔白板照片、教科书图表、手绘草图,模型都能解读,就算图片模糊、颠倒、质量差也行。模型还能在推理过程中动态处理图像 (旋转、缩放等)。
这有啥用?简单说,就是能帮你解决更棘手的图像问题:
分析更透彻、准确、靠谱。
无缝融合高级推理和各种工具 (网页搜索、图像处理)。
自动处理不完美的图片, 提取关键信息。
比如,你可以直接扔张经济学题目的照片,让它给你分步解释;或者截个代码构建失败的图,让它快速分析根本原因。
这种新能力让视觉和文本推理无缝结合,直接体现在了多模态基准测试的 SOTA 成绩上,算是向通用多模态推理迈出了一大步。
“带着图思考”实战演示 (o3 出马):
看图说话,感受一下:
读手写笔记: 就算图片是倒过来的,也能识别出内容 (“4th February – finish roadmap.”)。

解物理难题: 搞定复杂的 QED (量子电动力学) 费曼图问题,给出详细的 Møller 散射振幅计算过程。

识别路牌文字: 从有点模糊的图片中准确读出路牌信息 (“Ochsner URGENT CARE.”)。

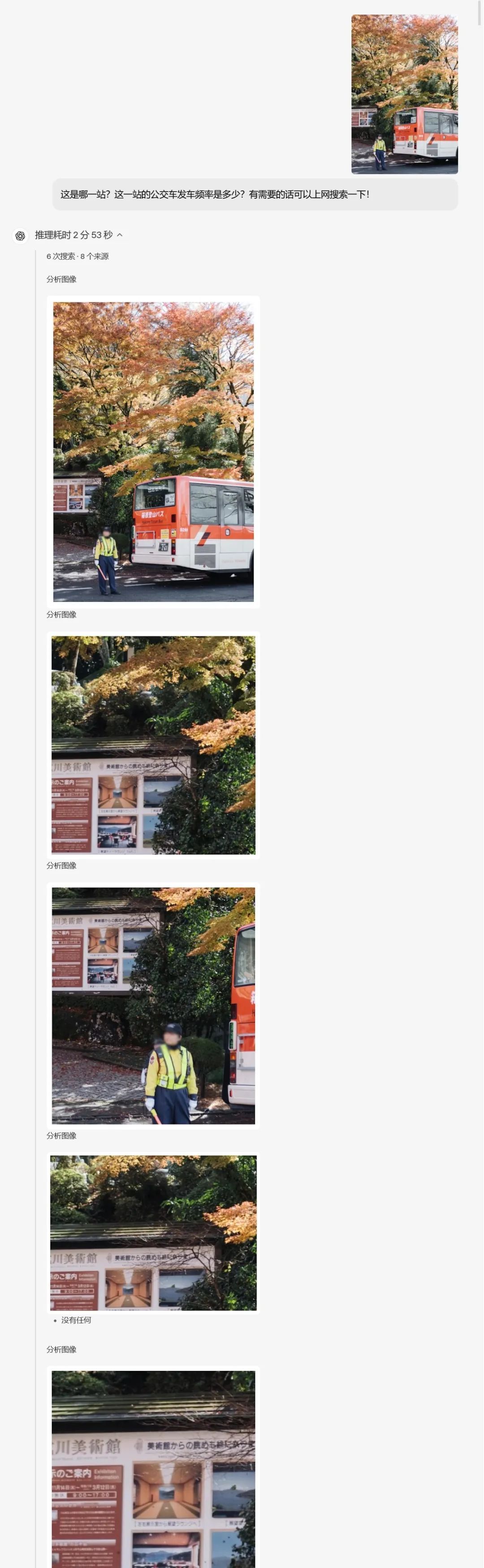
查公交信息: 根据站牌照片,结合网络搜索,确定是日本箱根的“成川美术馆前”站,并给出大致的发车频率 (白天约 15-20 分钟一班)。
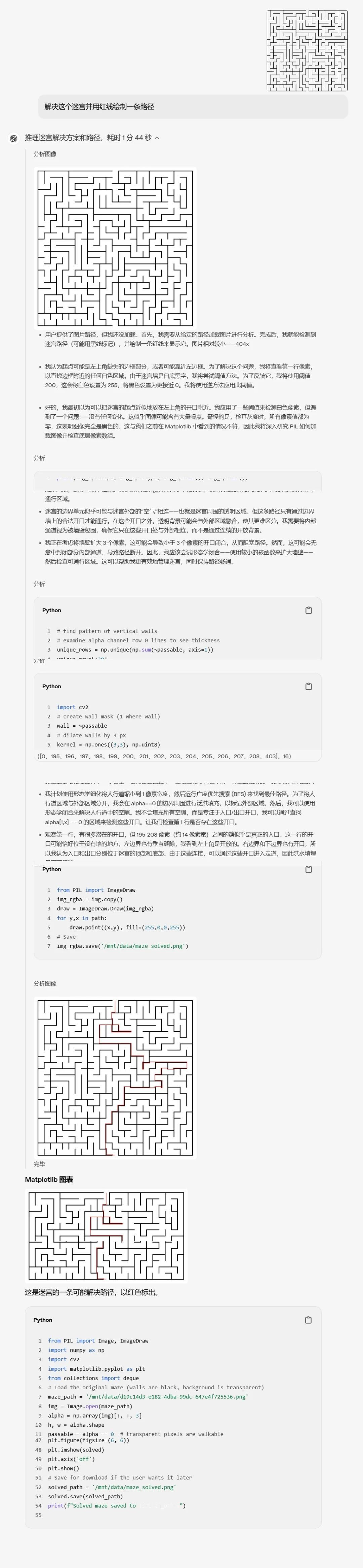
走迷宫: 分析迷宫图片 (黑色线条,透明背景),找出通路,并用红线标出解法。
推断活动日期: 根据 MIT 毕业典礼照片中的细节 (如学位帽颜色),结合搜索,推断出是工程学院 & 计算学院的高级学位典礼,日期是 5 月 29 日。

识别电影取景地: 通过窗外的海景和室内独特的红色栏杆,判断出是法国里维埃拉的 Kérylos 希腊别墅,并列出一系列在此取景拍摄的电影和电视剧 (如《绅士与淑女》、《动物园帮》、《好贼》等)。

解数字谜题: 破解那个经典的“手动挡”数字逻辑题 (135/24?),指出缺失的是 R (倒挡),而不是 6。

Benchmark 成绩直接起飞:
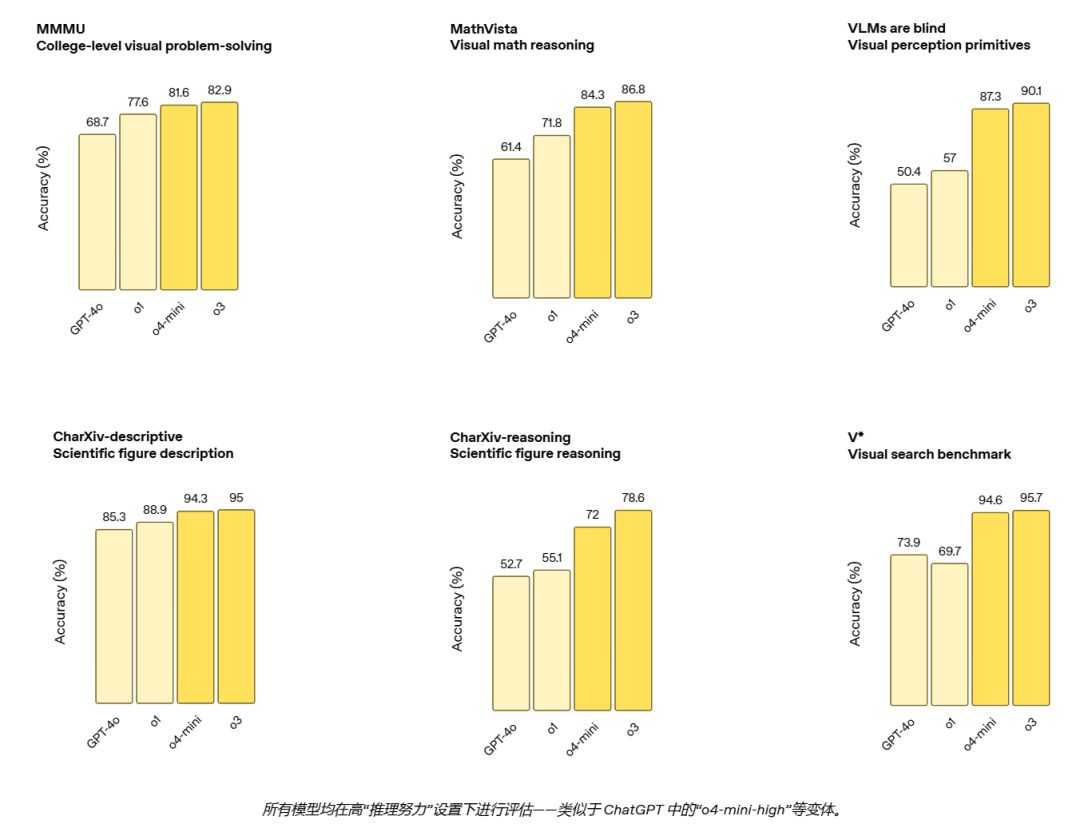
跟之前的模型 (GPT-4o, o1) 比,o3 和 o4-mini 在各种多模态任务上提升显著:
MMMU (大学水平视觉解题): o3 82.9% (o1 77.6%)
MathVista (视觉数学推理): o3 86.8% (o1 71.8%)
VLMs are Blind (视觉基础感知): o3 90.1% (o1 57%)
CharXiv-descriptive (科学图表描述): o3 95% (o1 88.9%)
CharXiv-reasoning (科学图表推理): o3 78.6% (o1 55.1%)
V* (视觉搜索基准): o3 95.7% (o1 69.7%) —— 基本算把这个 benchmark 给“通关”了。
 一些实际测试:
一些实际测试:
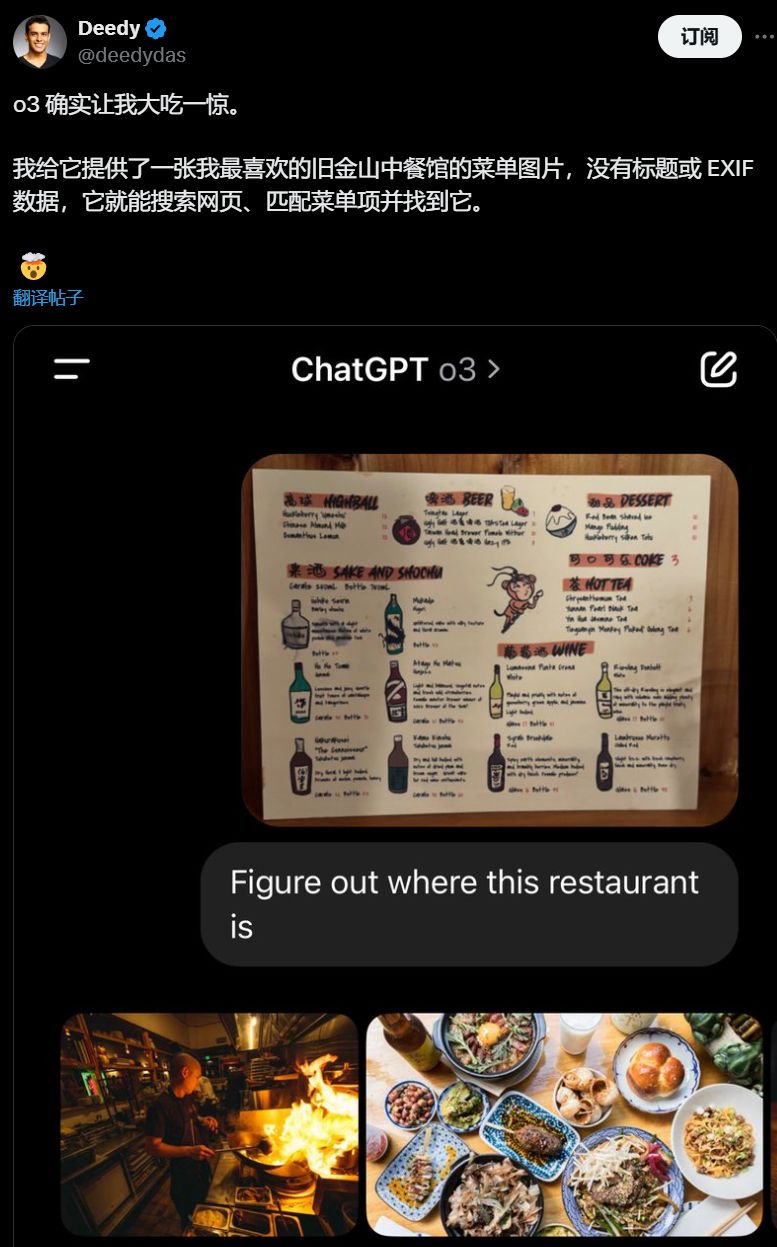
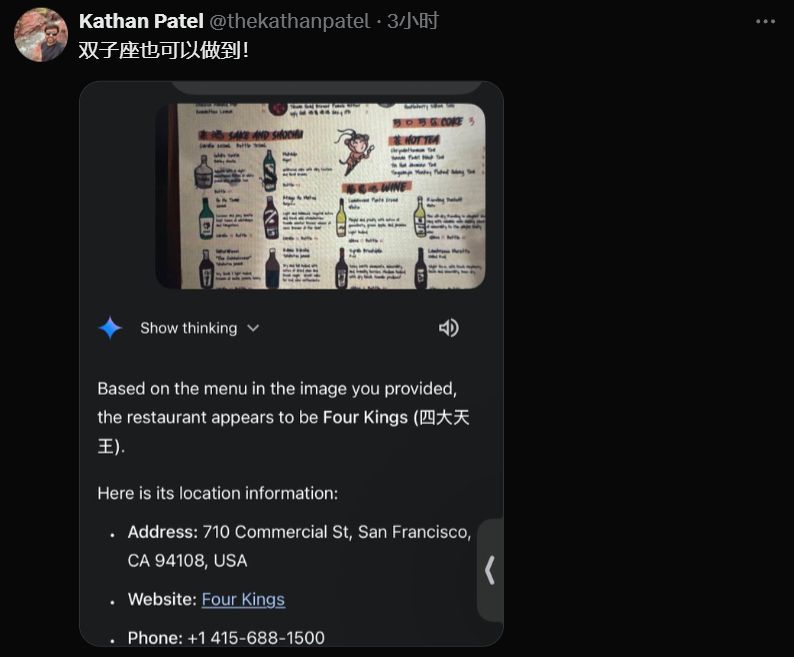
o3 这次真的秀到了,看图找餐馆,绝了。
Deedy Das 直接被惊到 ("blew my mind"):他喂给 o3 一张菜单照片,没店名没地址,o3 竟然上网搜菜名,直接找到了是旧金山哪家店。
底下评论也挺热闹:
有人说:“Gemini 也能干这个。” (@thekathanpatel)
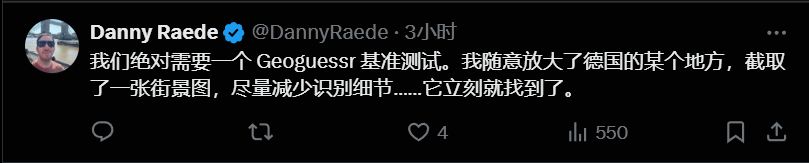
有人脑洞大开:“得搞个 Geoguessr 测试,看 AI 猜地名多准。” (@DannyRaede)
当然,还不是完美:
目前“带着图思考”还有些局限:
思考链有时太长、太啰嗦: 模型可能会执行多余的工具调用或图像处理步骤。
偶尔还是会看错图: 基础的感知错误依然存在,可能导致最终答案错误。
稳定性有待提高: 对于同一个问题,多次尝试可能会走不同的视觉推理路径,导致结果不一致。
但总的来说,o3 和 o4-mini 在视觉推理上是重大进步,向着更强的多模态推理迈了一大步。OpenAI 还在持续优化,让它们思考更简洁、更靠谱。期待看到这些新能力如何改变我们的工作。
怎么用上新模型?
ChatGPT 用户: Plus, Pro, Team 今天就能用 o3, o4-mini, o4-mini-high (替换旧模型)。Enterprise, Edu 下周。免费用户可以在提问前选 'Think' 来试用 o4-mini。速率限制不变。o3-pro 几周后发布 (带完整工具支持),目前 Pro 用户仍可访问 o1-pro。
开发者: 今天就能通过 Chat Completions API 和 Responses API 调用 o3/o4-mini (部分需验证组织)。Responses API 支持推理摘要、保留函数调用 token 等功能,后续会内置网页搜索、文件搜索、代码解释器。
根据社区反馈,实际限制可能如下: 使用 ChatGPT Plus、团队或企业帐户,您每周可以使用 o3 访问 50 条消息,每天可以使用 o4-mini 访问 150 条消息,每天可以使用 o4-mini-high 访问 50 条消息。
走向 Agentic 工具使用
o3 和 o4-mini 能完全访问 ChatGPT 内的工具,也能通过 API 调用你自定义的工具。模型被训练来思考如何解决问题,选择何时、如何使用工具,快速生成详细周到的答案。
比如你问:“加州今年夏天的能源使用量跟去年比怎么样?” 模型可以自己去搜公共数据,写 Python 代码建个预测模型,生成图表,再解释预测背后的关键因素,把多个工具调用串起来。它们还能根据遇到的信息灵活调整策略,比如多次搜索网页,看到结果不满意就换个关键词再搜。
“工具调用看来是下一代 AI 系统的标配了。”

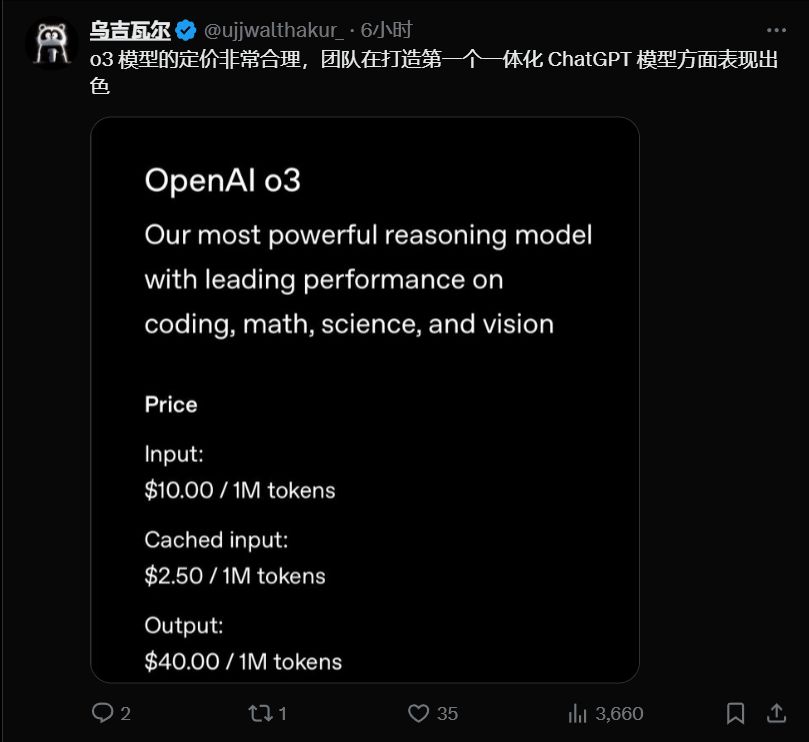
有人觉得 o3 定价“非常合理”,称赞这是“第一个 all-in-one 的 ChatGPT 模型”。
安全这块也升级了。
OpenAI 重建了安全训练数据,增加了生物风险、恶意软件生成、越狱等领域的拒绝提示。o3/o4-mini 在内部拒绝基准上表现强劲。
同时开发了系统级防护措施来标记危险提示,比如用一个推理 LLM 监控器来执行人类编写的安全规范,在生物风险方面成功标记了约 99% 的红队测试对话。
根据最新的《准备框架》,o3/o4-mini 在生物化学、网络安全、AI 自我改进这三个领域的能力评估都低于“高”风险阈值。
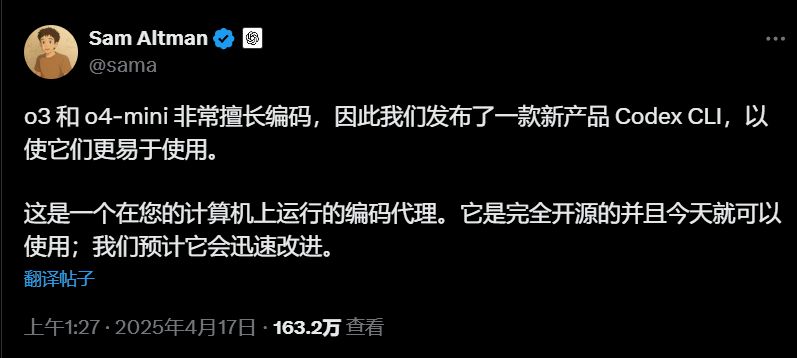
顺手还发了个新玩具:Codex CLI
一个轻量级的编码 Agent,直接在你的命令行里跑。它充分利用 o3/o4-mini 的推理能力 (后续会支持 GPT-4.1 等更多 API 模型),可以直接处理本地代码,甚至能结合截图或草图进行多模态推理。
Sam Altman 亲自下场带货:Codex CLI 来了,把 o3/o4-mini 塞进你的命令行。OpenAI CEO Sam Altman 亲自发推,宣布推出一个新产品:Codex CLI。
Codex CLI 完全开源 (github.com/openai/codex)。OpenAI 还启动了 100 万美元的资助计划,支持使用 Codex CLI 和 OpenAI 模型的项目 (以 API Credits 形式发放,每次 2.5 万美元)。
本地运行的编码 Agent: 直接在你电脑的命令行 (terminal) 里跑。
专为 o3/o4-mini 打造: 因为这两款新模型在编码上“超级棒 (super good)”,所以搞了这个工具让大家更容易用。
完全开源: 代码今天就放出来了 (GitHub 链接),摆明了要让社区一起快速迭代改进。
简单说,就是 OpenAI 把他们的 AI 编程能力,打包成了一个你可以直接在命令行里调用的工具。
社区反应 & 初步评测:
看好方向: 有人认为这是“设备端编码 Agent”的重要一步,也是基础设施方面的大动作。
开始动手: 有人已经计划用 Codex CLI + o3 来复活老项目,做成强大的 XR 数学工具。
下一步棋怎么走?
OpenAI 的方向很明确:融合 O 系列的专业推理能力和 GPT 系列的自然对话、工具使用能力。 未来的模型将支持无缝自然的对话,同时具备主动的工具使用和高级问题解决能力。
总而言之,o3 和 o4-mini 的发布,标志着 OpenAI 在模型智能和 Agent 能力上的又一次重要迭代,特别是赋予了 AI 灵活组合使用多种工具和“带着图像思考”的能力。这让 ChatGPT 向着更强大、更自主的 AI 助手迈进了一大步。
与此同时,你的ChatGPT面板。。。



以及谷歌的一个新模型。4月22号可能要来了,还有Openai 今天的模型你可以去Cursor、Windsurf等IDE中使用了。
 以上。
One More Thing
以上。
One More Thing
MCP相关实践:
MCP是什么: Cline的MCP商店来了。 MCP怎么配置、报错解决:
MCP实践:Cursor + MCP:效率狂飙!一键克隆网站、自动调试错误,社区:每个人都在谈论MCP!
Blender + MCP 从入门到实践:安装、配置、插件、渲染与快捷键一文搞定!
手把手教你配置BrowserTools MCP,Windows 和 Mac全流程,关键命令别忽略。
太简单了!Cline官方定义MCP开发流程,聊天式开发,让MCP搭建不再复杂。
本号知识星球(汇集了ALL订阅频道合集和其他):

星球里可获取更多AI实践:
 🌟 知音难求,自我修
炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
参考链接:
🌟 知音难求,自我修
炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
参考链接:[1] https://openai.com/index/introducing-o3-and-o4-mini/
点这里👇关注我,记得标星哦~


















 2133
2133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











