







AI空间 | 商务合作,点击此处:一键直达🚀
🌟基于 PaddlePaddle的超棒多语言OCR工具包
(实用的超轻量级OCR系统,支持80多种语言识别,提供数据标注和合成工具,支持在服务器、移动、嵌入式和物联网设备之间训练和部署)
二阶段模型训练
文字检测模型训练
这个主要是做目标检测文字 定位 的,后面一个文字识别就是做分类的,我们以训练自己的数据集为例,官方说用于模型训练的文字检测数据格式应如下
" 图像文件名 json.dumps编码的图像标注信息"ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
这里如果我们训练自己的数据集的话,我们可以直接使用官方提供的数据集标注软件PPOCRLabel,标注完的结果就得到以上的格式。
PPOCRLabel操作
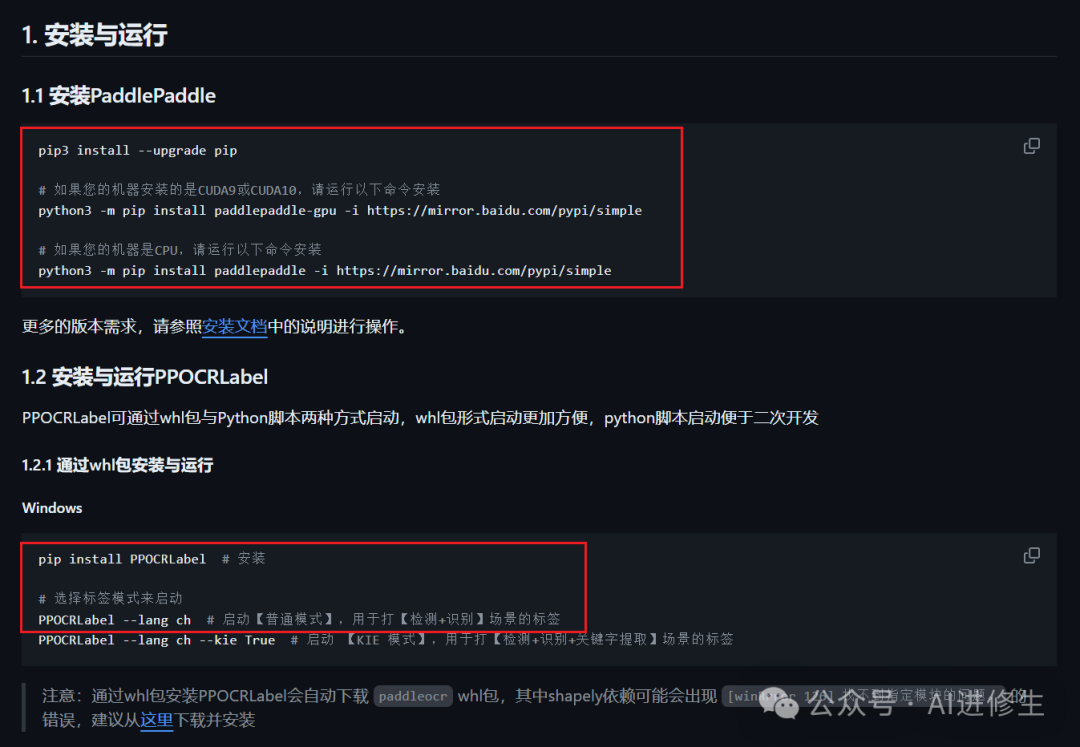
按照这个步骤安装好直接启动就可以了
这个软件操作起来也比较简单,他的官方文档下面也有相关功能按键的描述即可
https://github.com/PaddlePaddle/PaddleOCR/tree/main/PPOCRLabel
最后会导出文本检测和文字识别两个标签文件,每次修改标注完一张图片,点击下一个图片的时候,它会弹出保存窗口。
保存之后,这样他的标签文件才会同步变更,对了,这个软件也支持ai自动的半标注。
除此以外,这里我汇聚了主流的一些标注软件
https://github.com/Ai-trainee?submit=Search&q=label&tab=stars&type=&sort=&direction=&submit=Search
以及robflow平台也有标注工具:
https://www.bilibili.com/video/BV12K421v7SM/
我们已经有了自己的数据集就可以执行一下他提供的数据及划分脚本
cd ./PPOCRLabel # Change the directory to the PPOCRLabel folderpython gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../train_data
当我们数据集都准备完的时候,我们可以回到开头来进行文本检测模型的训练:
我们参照这里选择模型即可
https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/models_list.md

直接把配置文件和训练模型下载下来(分为中文、英文和多语言模型,选择相应的场景模型即可)。
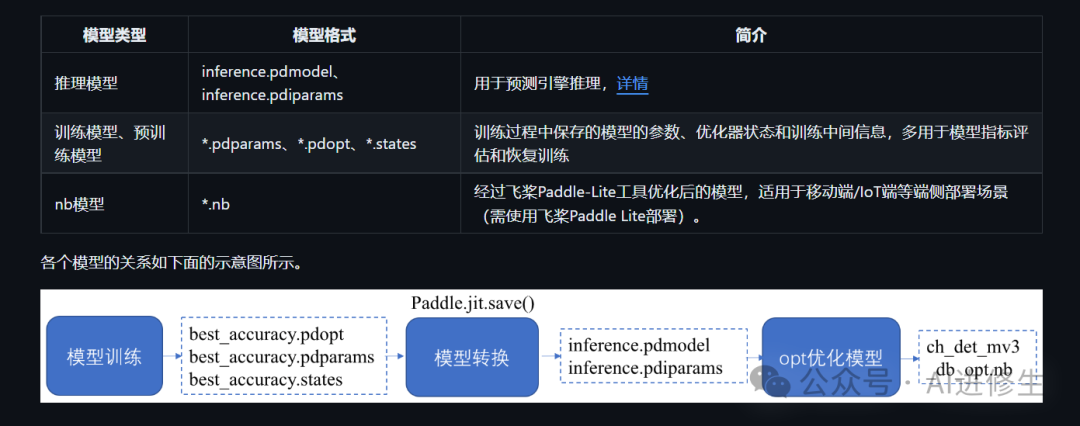
下载地址中其中还有一个推理模型,这里要说的是它的模型构成其实分为三个类型,
你可以对比这张图表了解,也就是说训练和推理的模型后缀格式是不一样的。
然后启动训练脚本即可
# 单机单卡训练 mv3_db 模型
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
启动之前注意修改一下配置文件,包括数据集的路径,模型的路径,还有训练参数等等(det_mv3_db.yml)
训练结束之后需要将模型转化为推理模型
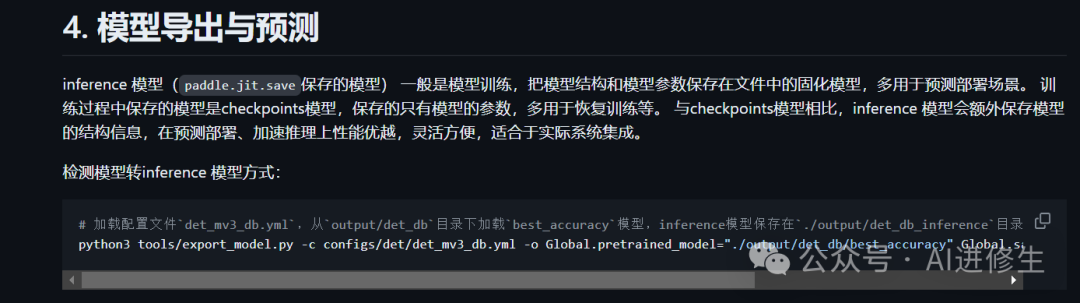
如果做完以上步骤,那么文本检测模型就训练完毕(更多的具体细节可以参考官方文档)
文字识别模型训练
数据集格式
" 图像文件名 图像标注信息 "train_data/rec/train/word_001.jpg 简单可依赖train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单...
与文本检测模型训练类似,只需要参考官方文档即可
https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/recognition.md
PP-OCR 推理部署
PP-OCR模型已打通多种场景部署方案,点击链接获取具体的使用教程。
-
• Python 推理
-
• C++ 推理
-
• Serving 服务化部署(Python/C++)
-
• Paddle-Lite 端侧部署(ARM CPU/OpenCL ARM GPU)
-
• Paddle.js 部署
-
• Jetson 推理
-
• Paddle2ONNX 推理
https://github.com/PaddlePaddle/PaddleOCR/blob/main/deploy/README_ch.md
最后我们可以按照顺序学习这个项目(他的教程内容很多,可以先按照上面动手,先把模型跑出来,然后慢慢把整个项目文档看完)

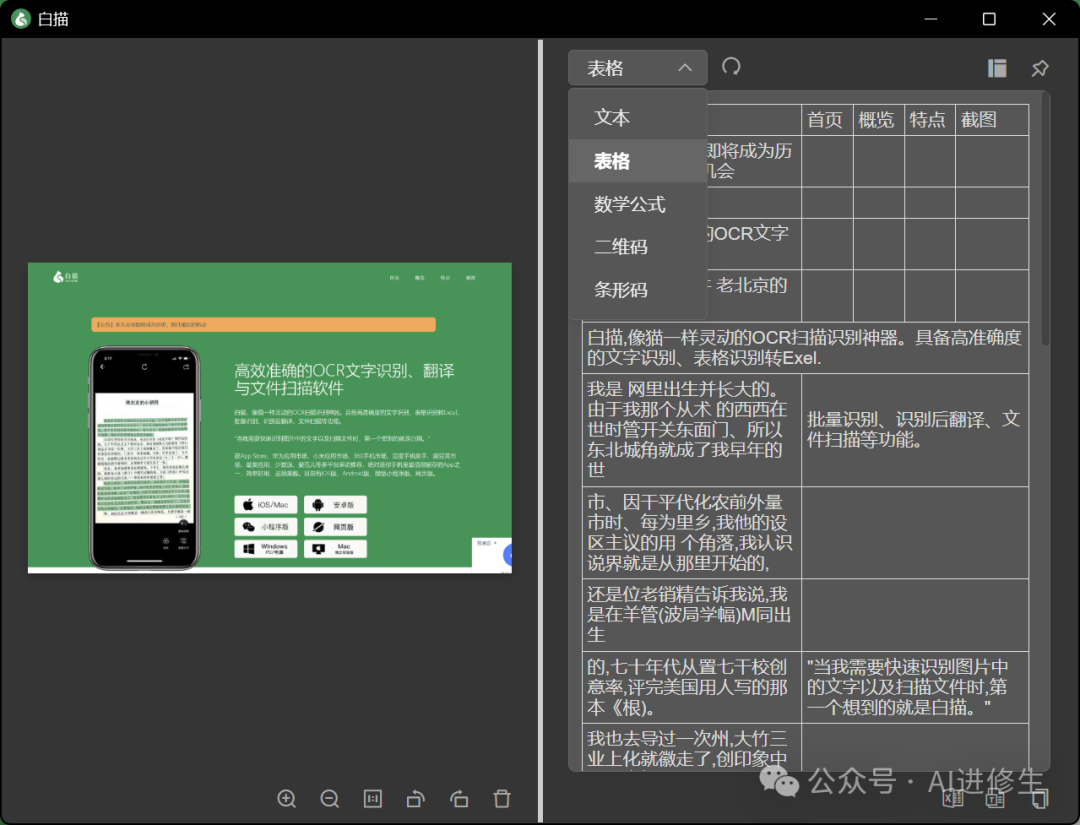
说点题外话,在电脑本地使用的ocr软件,我觉得这个白描OCR应该是挺无敌的存在,准确率高,然后速度还很快,平时进行办公会用到识别复制粘贴之类的,一个快捷键,就能准确提取,效率这方面没得说,,白描目前还处于终身买断制。
https://baimiao.uzero.cn/
PaddleOCR使用常见的170个问题汇总:
https://mp.weixin.qq.com/s/UqCudUz4wbQSOPKBHHjp0whttps://github.com/PaddlePaddle/PaddleOCR/tree/main?tab=readme-ov-file
— 完 —
** 点这里 👇 关注我,记得标星哦~ **
**
**
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~



















 4172
4172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











