






闲话略过,直接开始正题。
今天,记录蛋挞学习爬取小说鬼吹灯的全过程。
首先,百度搜索“鬼吹灯”。点开网页,记录一下网址,后面需要使用。
之后,点开上图中的“鬼吹灯”,查看所有章节。接下来,小雷将把这些标题和内容全部爬取下来。

鼠标右键,选择“网页源代码”,我们所需要的章节链接全部存在源代码中。
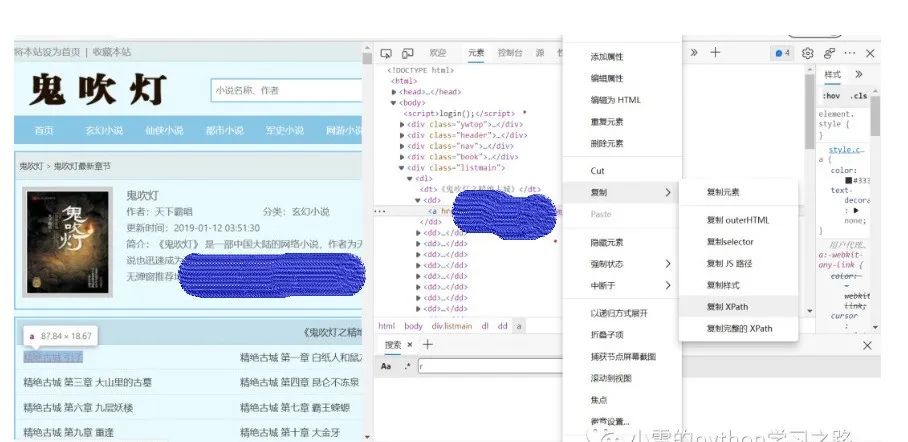
鼠标右键,点击“检查”,弹出如下页面。
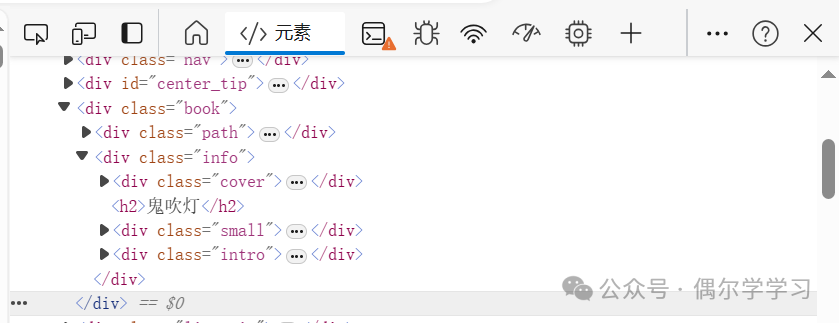
点击下图红色圈出的图标,再点击章节名,可以找到章节对应的文本链接。
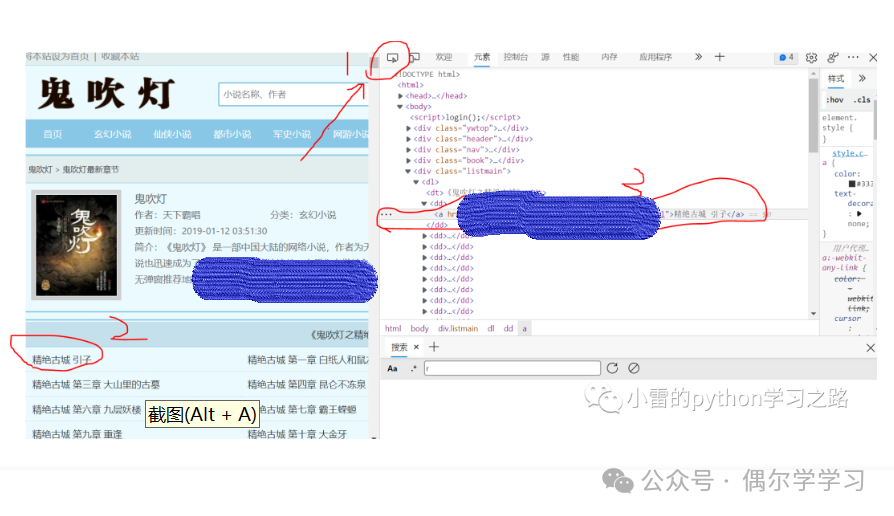
在章节链接处点击鼠标右键,选择"复制",然后选择“xpath”,可以获取章节链接在网页源代码中的位置。
点击章节链接,可以打开相应的章节内容,如下图:

鼠标右键,点击“网页源代码”,查看章节内容和标题在代码中的位置。章节内容在代码中的位置,其查找方法和上文章节链接位置的查找方法一致。
接下来开始正式写代码。
首先,按上文分析获取所有章节的链接。
import requests #导入请求网页的requests模块
from bs4 import BeautifulSoup #处理网页的模块
from lxml import etree #处理网页的模块
import os #建立文件夹的模块
import time #时间模块
url1 = '网页网址' #主网址
headers = {
'User-Agent': '网页中复制,粘贴于此'
} #请求头,反反爬初级
response = requests.get(url1, headers=headers) #请求网页内容
response.encoding = response.apparent_encoding #用当前的编码方式编码
#print(response.text)
html = etree.HTML(response.text) #对请求的网页内容进行处理,方式一
soup = BeautifulSoup(response.text, 'html.parser') #对请求的网页内容进行处理,方式二
#print(soup)
for i in range(4, 24): #最大值24
filename = html.xpath('/html/body/div[{}]/dl/dt/text()'.format(i))[0] #获取书名,用于建立文件夹
print(filename)
#titles.append(title)
path = '存储路径' + '\\' + filename #文件保存地址
os.makedirs(path) #在给定的地址建立文件
urls = html.xpath('/html/body/div[{}]/dl/dd/a/@href'.format(i)) #获取所有章节链接
titles = html.xpath('/html/body/div[{}]/dl/dd/a/text()'.format(i)) #获取每一章节名
i = i + 1
之后,逐一爬取文章的内容,并写入这一章节名下,形成txt文件。
a=0
for url, title in zip(urls,titles): #利用zip函数逐一匹配章节名和链接
#print(url,title)
time.sleep(5) #休息5s后,再请求网页
res = requests.get(url) #请求章节内容,这里没有请求头,但也可以,所以偷懒了
res.encoding = res.apparent_encoding #利用当前编码方式编码
html1 = etree.HTML(res.text) #对网页进行处理
soup = BeautifulSoup(res.text, 'html.parser') #对网页进行处理
a = a + 1
title1 = str(a) + title
print(title1)
#print(soup)
text= soup.select('#content')[0].get_text() #BeautifulSoup方式处理的网页,提取出的文本格式更棒
# text = html1.xpath('//*[@id="content"]')[0]
text = text.replace(" ", "\r\n") #将网页中的换行符替换成python中的换行符
text = text.replace("目标广告1", "") #将文本中插入的广告替换成空
text = text.replace("目标广告2", "") #将文本中插入的广告替换成空
text = text.replace("目标广告3", "") #将文本中插入的广告替换成空
text = text.replace("目标广告4", "") #将文本中插入的广告替换成空
text = text.replace(url, "") #将文本中插入的广告替换成空
#print(text)/html/body/div[21]/dl/dt
with open(path + "\\" +title1, 'w', encoding= 'utf-8') as f: #将文本内容写入本地建立的文件夹下章节名下
f.write(text)
最后,将代码拼接成完整的小说爬取代码。
import requests
from bs4 import BeautifulSoup
from lxml import etree
import os
import time
url1 = '网页网址'
headers = {
'User-Agent': '网页中复制,粘贴于此'
}
response = requests.get(url1, headers=headers) #请求网页内容
response.encoding = response.apparent_encoding #用当前的编码方式编码
#print(response.text)
html = etree.HTML(response.text) #对请求的网页内容进行处理,方式一
soup = BeautifulSoup(response.text, 'html.parser') #对请求的网页内容进行处理,方式二
#print(soup)
for i in range(4, 24): #最大值24
filename = html.xpath('/html/body/div[{}]/dl/dt/text()'.format(i))[0]
print(filename)
#titles.append(title)
path = 'C:\\Users\\15089\\Desktop\\guichuideng' + '\\' + filename
os.makedirs(path)
urls = html.xpath('/html/body/div[{}]/dl/dd/a/@href'.format(i))
titles = html.xpath('/html/body/div[{}]/dl/dd/a/text()'.format(i))
i = i + 1
a=0
for url, title in zip(urls,titles):
#print(url,title)
time.sleep(5)
res = requests.get(url)
res.encoding = res.apparent_encoding
html1 = etree.HTML(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
a = a + 1
title1 = str(a) + title
print(title1)
#print(soup)
text= soup.select('#content')[0].get_text()
# text = html1.xpath('//*[@id="content"]')[0]
text = text.replace(" ", "\r\n")
text = text.replace("目标广告1", "")
text = text.replace("目标广告2", "")
text = text.replace("目标广告3", "")
text = text.replace("目标广告4", "")
text = text.replace(url, "")
#print(text)/html/body/div[21]/dl/dt
with open(path + "\\" +title1, 'w', encoding= 'utf-8') as f:
f.write(text)
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
















 1981
1981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









