






赋能百业:多模态处理技术与大模型架构下的AI解决方案落地实践
AI 语音交互大模型其实有两种主流的做法:
-
All in LLM
-
多个模块组合, ASR+LLM+TTS
实际应用中,这两种方案并不是要对立存在的,像永劫无间这种游戏的场景,用户要的是低延迟,无障碍交流。并且能够触发某些动作技能。这就非常适合使用成熟的 ASR 和 TTS 技术来负责音频的处理,而 LLM 就可以专门做用户意图的理解。
1.数据
要是想训练一个大模型,去思考自己有什么样的数据,数据的获取方法有两种
-
自动化的获取,就像 Aone Copilot 代码补全场景一样,我们从原始的代码中通过某些规则扣出一块,作为模型的预测数据,我们只需要设定好策略就可以得到千万条数据用来训练
-
半自动获取,我们可以借助一些更强大的生成模型比如 ChatGPT,让他代替人工生成一些数据,再经过规则清洗得到最终使用的数据
-
用户使用数据, 类似商品和短视频推荐的数据,都是通过曝光点击行为来做训练的
-
人工标注,这种数据获取方法成本非常高,做这种事情的时候,千万先想好自己的业务诉求和价值
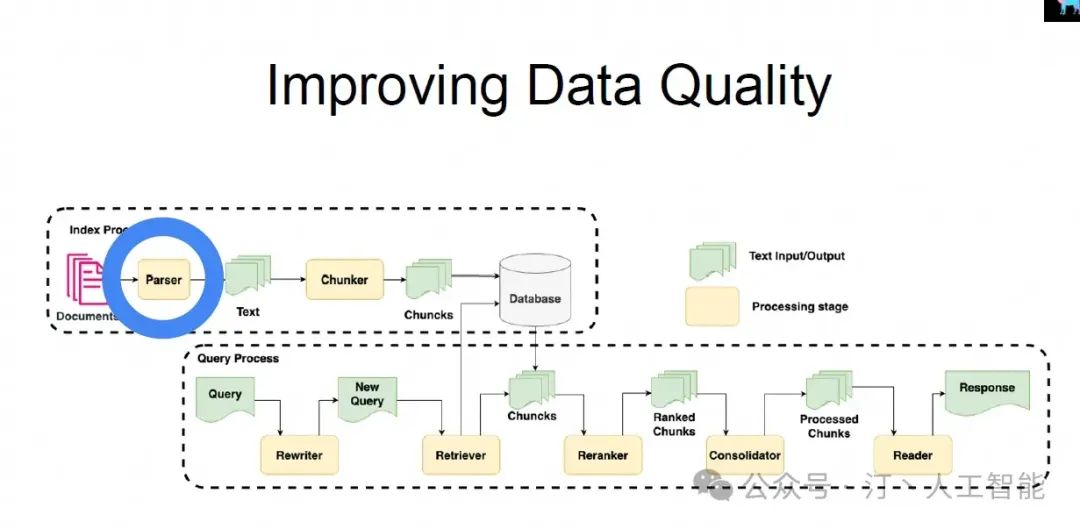
再有,要构建自己的数据闭环。在本次 AICon 中,很多演讲者就演讲了自己怎样构建自己的数据闭环的。这里的闭环指 用户使用 -> 生成的中间数据 -> 专家矫正和人工标注 -> 校正后的数据迭代整个系统或者模型。这对于大模型非常重要,有了数据闭环才能说真正的达到了一个与大模型交互的系统上线的要求。
2.问答场景多模态
整个 Aone Copilot 的问答,包括研小喵的问答都是采用 markdown 作为输出的富文本载体的,markdown 原生支持图片渲染的,所以我觉得借鉴小红书的方案,可以将图片信息通过 markdown 格式放入文本中。
这里需要注意
-
清洗数据的时候,需要确保文本是能够加载显示的,而不是无效的图片
-
图片本身 ocr 可能提供的信息有限,可以但是可以根据上下文信息,让大模型猜测图片可能的内容,这就有点像 NLP 的传统任务,完形填空,可以猜测的八九不离十
回头再看小红书的方案,他们放弃了图文类图片的对齐数据,若这块采用了图片问答(VQA)的模型描述图片,显然这种模型的运行速度还不能处理小红书海量的数据,所以采用这种根据文字推测图片方案或许也失为一种好的方法。
下面我们就节选本文的一部分内容进行实验
user:
要是想训练一个大模型,去思考自己有什么样的数据,数据的获取方法有两种
1. 自动化的获取,就像Aone Copilot 代码补全场景一样,我们从原始的代码中通过某些规则扣出一块,作为模型的预测数据,我们只需要设定好策略就可以得到千万条数据用来训练
2. 半自动获取,我们可以借助一些更强大的生成模型比如chat-gpt,让他代替人工生成一些数据,再经过规则清洗得到最终使用的数据
3. 用户使用数据, 类似广告推荐的数据,都是通过曝光点击行为来做训练的
4. 人工标注,这种数据获取方法成本非常高,做这种事情的时候,千万先想好自己的业务诉求和价值
<image>
再有,要构建自己的数据闭环。在本次AICon中,很多演讲者就演讲了自己怎样构建自己的数据闭环的,这对于大模型非常重要,有了数据闭环才能说真正的达到了一个与大模型交互的系统上线的要求。
以上段落中,<image> 的地方是一张图片,根据上下文推测图片内容,限制在25个字
assistant:
图片内容可能是一个展示数据获取方法和数据闭环构建流程的流程图或示意图。
所以我们就可以可以这样存储待召回的数据
要是想训练一个大模型,去思考自己有什么样的数据,数据的获取方法有两种
1. 自动化的获取,就像Aone Copilot 代码补全场景一样,我们从原始的代码中通过某些规则扣出一块,作为模型的预测数据,我们只需要设定好策略就可以得到千万条数据用来训练
2. 半自动获取,我们可以借助一些更强大的生成模型比如chat-gpt,让他代替人工生成一些数据,再经过规则清洗得到最终使用的数据
3. 用户使用数据, 类似广告推荐的数据,都是通过曝光点击行为来做训练的
4. 人工标注,这种数据获取方法成本非常高,做这种事情的时候,千万先想好自己的业务诉求和价值

再有,要构建自己的数据闭环。在本次AICon中,很多演讲者就演讲了自己怎样构建自己的数据闭环的,这对于大模型非常重要,有了数据闭环才能说真正的达到了一个与大模型交互的系统上线的要求。
后面都是结合此次会议的内容,对技术层面的简述,也有部分有意思东西:
纯从特征融合的角度看,现有架构的多模态的大模型都是属于特征层的模态融合,这种融合方式相对于从数据层融合 (early fusion) 更加容易对齐数据而且可以限制特征空间,想对于各个模态的结果融合(later fusion)又有很大的发挥空间。
下面就举例一些经典的案例来说明其他模态的特征是如何与 transformer 交互的:
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

3.图像Vision Transformer
基于自注意力的架构,尤其是 Transformer,已成为 NLP 中的首选模型。由于 Transformers 的计算效率和可扩展性,训练具有超过 100B 个参数的、前所未有的模型成为了可能。随着模型和数据集的增长,仍未表现出饱和的迹象。
3.1 常见方法
将图像拆分为块 (patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入。图像块 (patches) 的处理方式同 NLP 的标记 (tokens)
当在没有强正则化的中型数据集(如 ImageNet)上进行训练时,这些模型产生的准确率比同等大小的 ResNet 低几个百分点。 但若在更大的数据集 (14M-300M 图像) 上训练,情况就会发生变化。我们发现 大规模训练 胜过 归纳偏置。Vision Transformer (ViT) 在以足够的规模进行预训练并迁移到具有较少数据点的任务时获得了出色结果。
图像块的嵌入 - 图像到 tokens
- Patch Embeddings
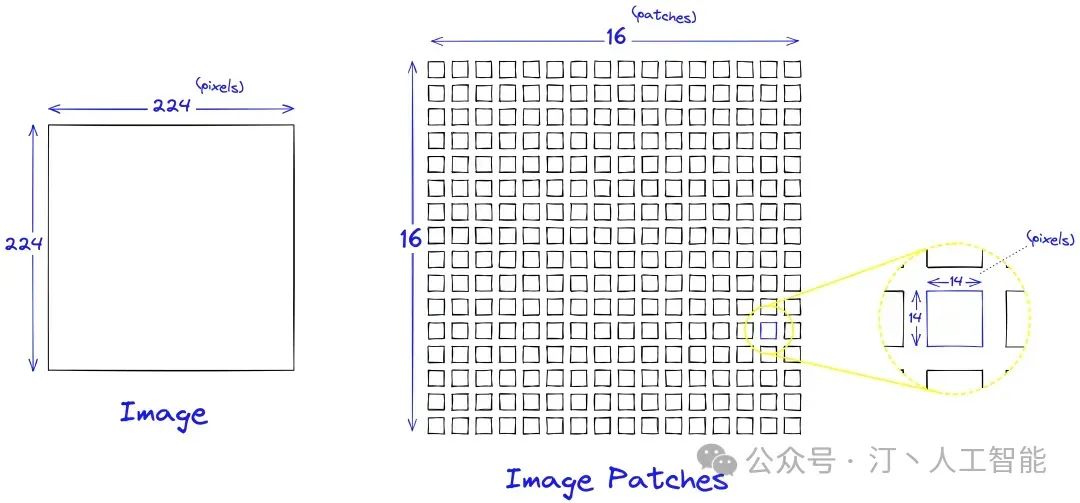
-
Position Embeddings: Position embeddings 加到图像块中是为了保留位置信息的。
-
Classification Token: 为了完成分类任务,除了以上九个图像块,我们还在序列中添加了一个 * 的块 0,叫额外的学习的分类标记 Classification Token。
-
Transformer Encoder: 由多个堆叠的层组成,每层包括多头自注意力机制(MSA)和多层感知机(MLP block)。
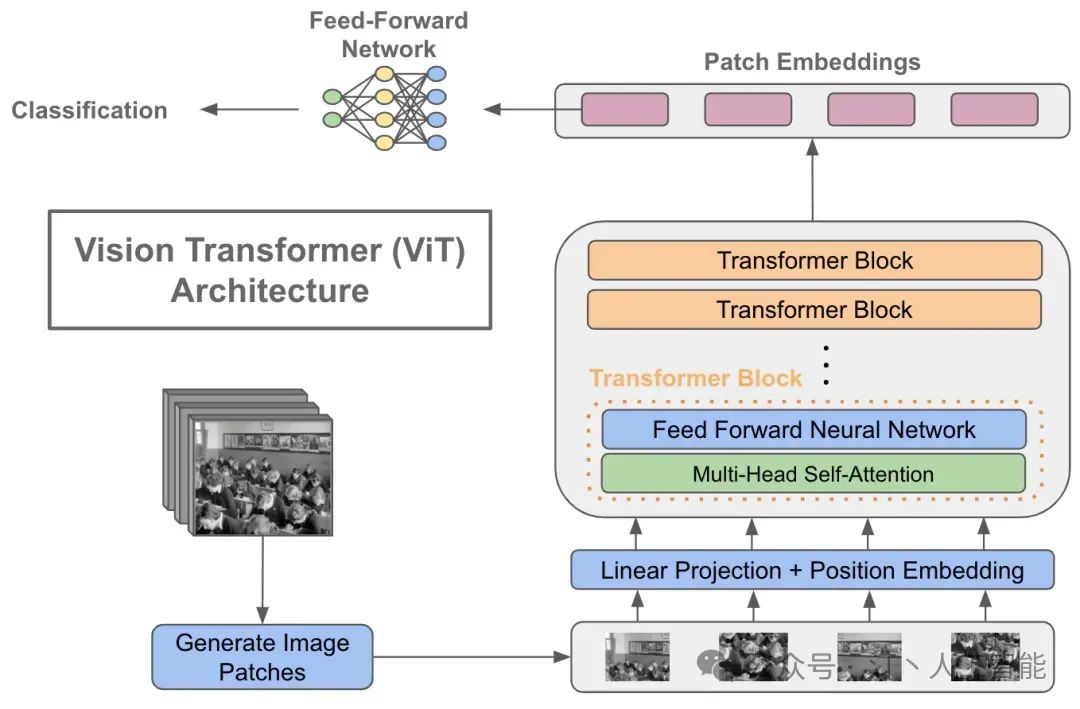
不同于 NLP 任务,NLP 任务的文本都是自回归的。 无论是之前的类似完形填空的 Masked Language Modeling (MLM), 后者预测 next token 等,VIT 还是使用类别预测来做训练的。
但是图像信息其实也有相互关联和冗余,其实也可以通过非监督的 MLM 方式来进行预训练,所以如下就是 BEIT 的工作成果
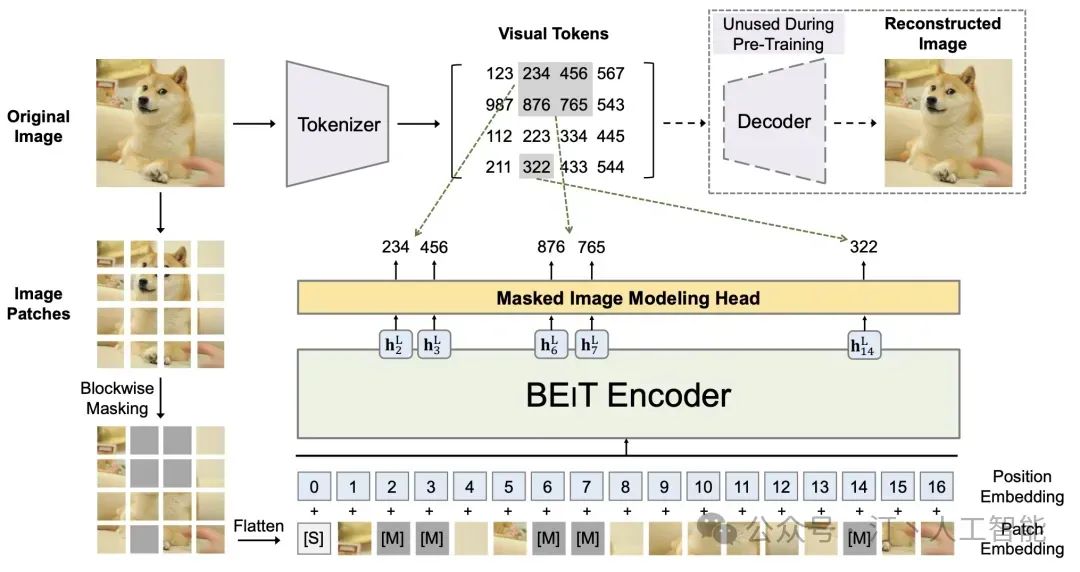
ICLR 2022 微软亚研院的一篇工作 BEIT: BERT Pre-Training of Image Transformers(ICLR 2022)
3.2 图像问答 VQA
好了,自从第一位大神将图像从纯深度 CNN-DNN 迁移到 tansformer 上,并证明了在大数据集下的优秀表现,图像的任务就逐步放弃了纯 CNN-DNN 的超级深度网络,转而投降与自然语言结合在一起,在 transformer 的加持下攻破了各种图片问答(VQA)的数据集,进而衍生出了更多复杂的玩法
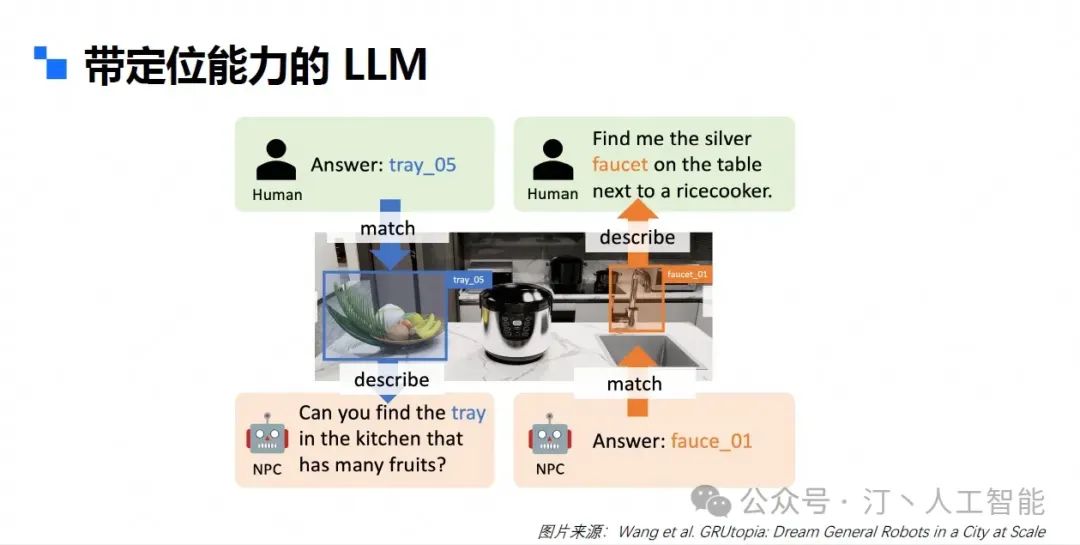
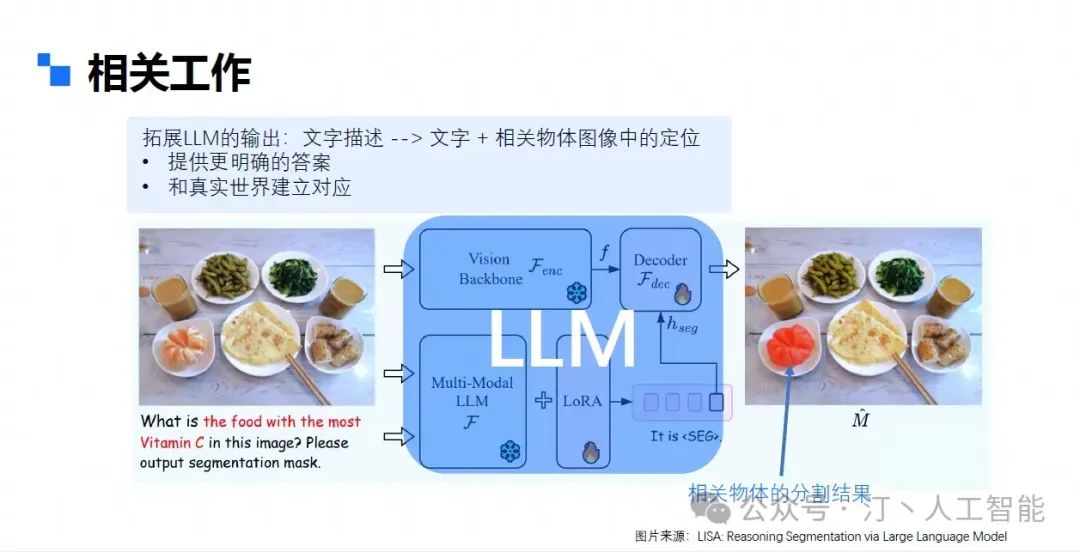
前面都是做图像问答和分割的,至于如何让大模型输出一个图像,现在主流的做法是采用扩散模型的方法来做(不过多展开),但是玩过 midjourney 都知道,用它来做艺术创作确实可以收货不错的灵感,但是要是用它来生成一个具体的带有业务含义的框图,其实比较难。 可以看看本文开头的第一幅图,就是用即梦的网页版本生成的图片,prompt 为 “多模态应用在生活的种种方面,生成一个多模态大模型应用于各个方面的图”,但是可以看见图片的细节,特别是文字,几乎都是不可阅读的。
4.语音
4.1 FunAudioLLM
通义的 FunAudioLLM 的介绍,但是用这个来了解音频大模型的构成,还是不错的一个样例
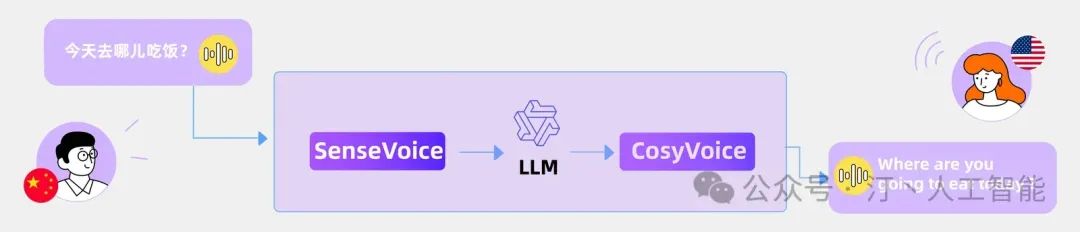
- SenseVoice
可以认为是提取语音的输入特征信息的模块
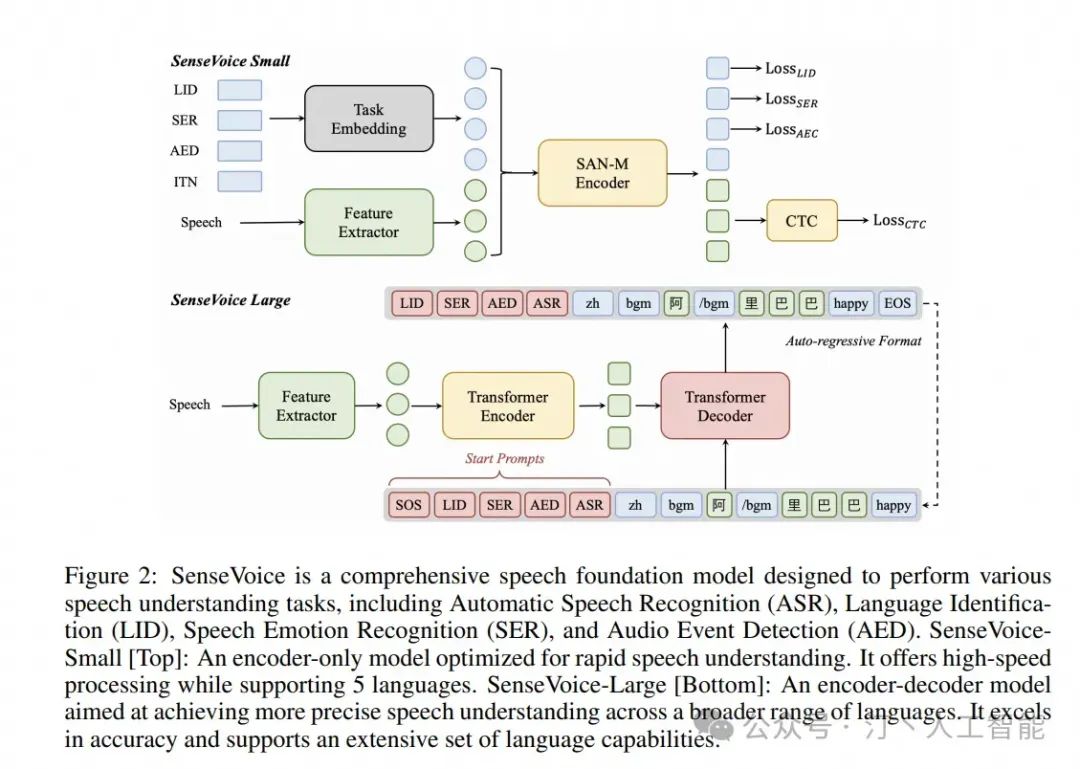
这里需要对输入的 LID,SER,AED,ITN 进一步说明下
ASR:通俗来说,就是语音转文字,其实是研究了很久的一项较为成熟的技术,在中国还能比较好的支持部分方言,主流的服务与说话的延迟差不多 1s 左右
SER:语音情感识别,我之前专门做过这个方向,差不多输出平静,高兴,悲伤,愤怒这 4 个标签 能够表征人物的语言情感
LID: 识别人说的是哪种语言,中文,英文,日文等等
AED:语音事件检测,比如哭声,掌声,鼾声等等。 很多家用摄像头就带这个功能,可以检测孩子哭声并及时报警。
除此之外,其实语音还有很多丰富的功能,比如男女,年龄范围等等。
- CosyVoice
可以认为是重建语音的模块
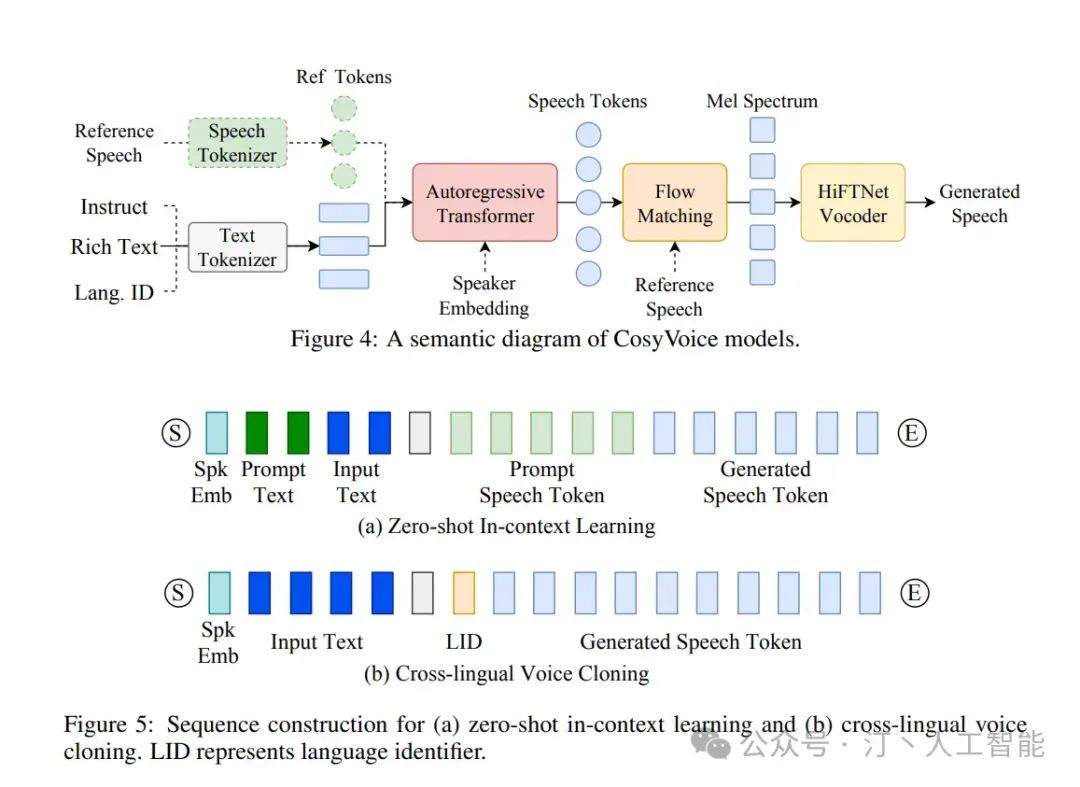
-
自然语音生成:能够生成自然流畅、逼真的语音。
-
多语言支持:支持中文、英文、日语、粤语和韩语。
-
音色和情感控制:通过少量原始音频生成模拟音色,包括韵律和情感细节。
-
细粒度控制:支持以富文本或自然语言精细控制生成语音的情感和韵律
4.2 音频多模态大模型方案
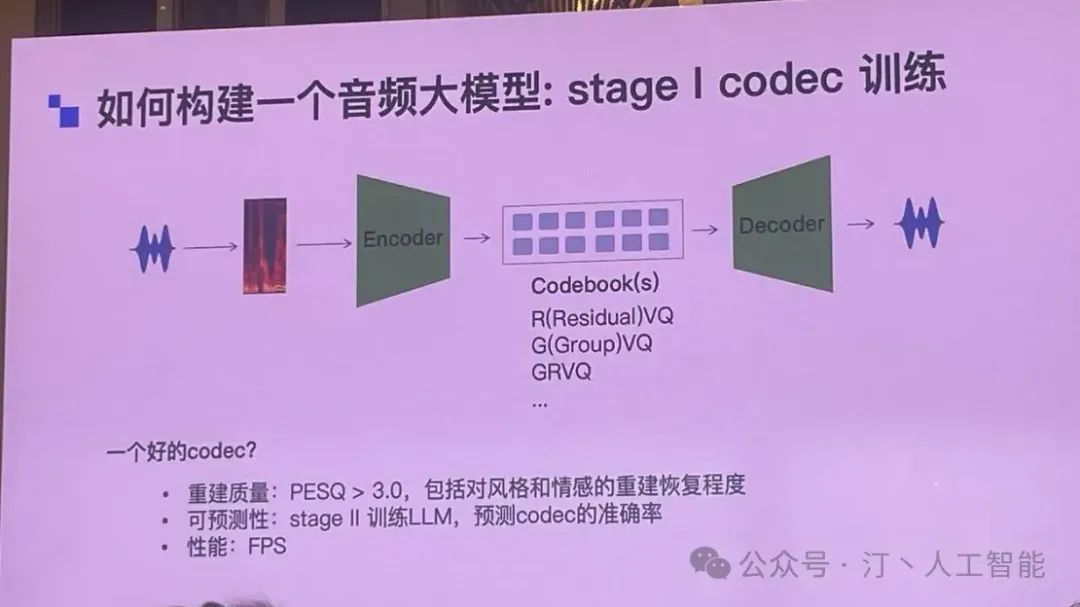
首先解决如何将声音变为数字编码以及在还原声音的过程,图中声音和 Encoder 之间的图片是声音的频谱图,虽然图这么画,但是实际上并不一定用的就是频谱图本身,按照经验可能是频率的特征,加上其他特征。
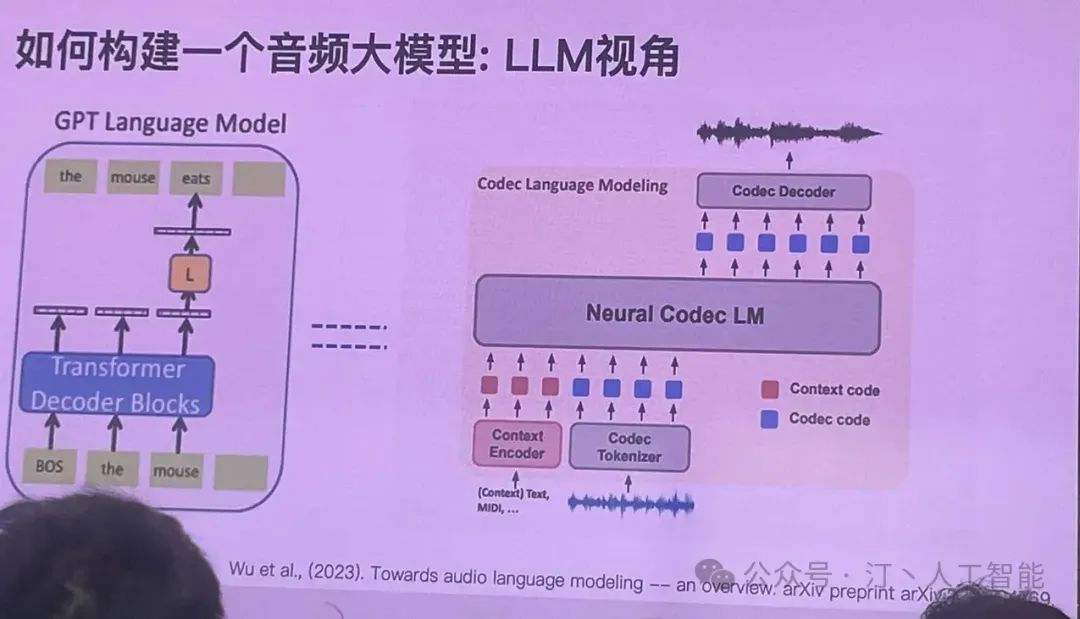
有了特征,那就大力出奇迹,all in llm。
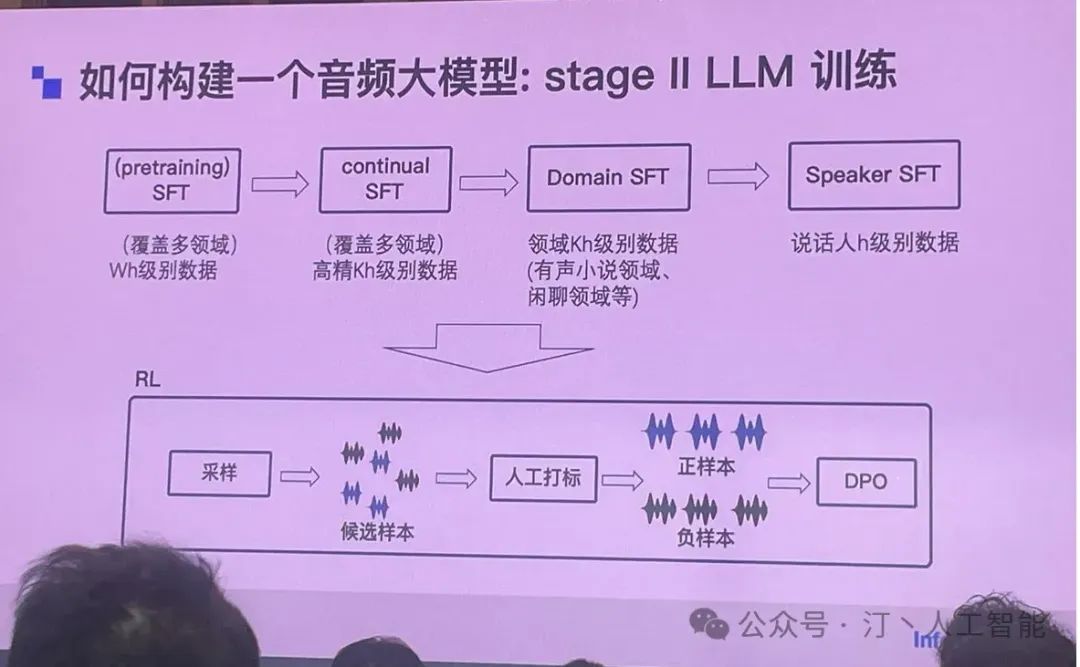
训练过程也跟 NLP 大模型训练非常像,从大量数据到少量优质领域数据。
4.3 多模块整合方案
大致归纳如下

下面是永劫无间游戏场景做的一个 AI 队友的方案,LLM 负责自然语言输出,角色 TTS 做出效果和回应

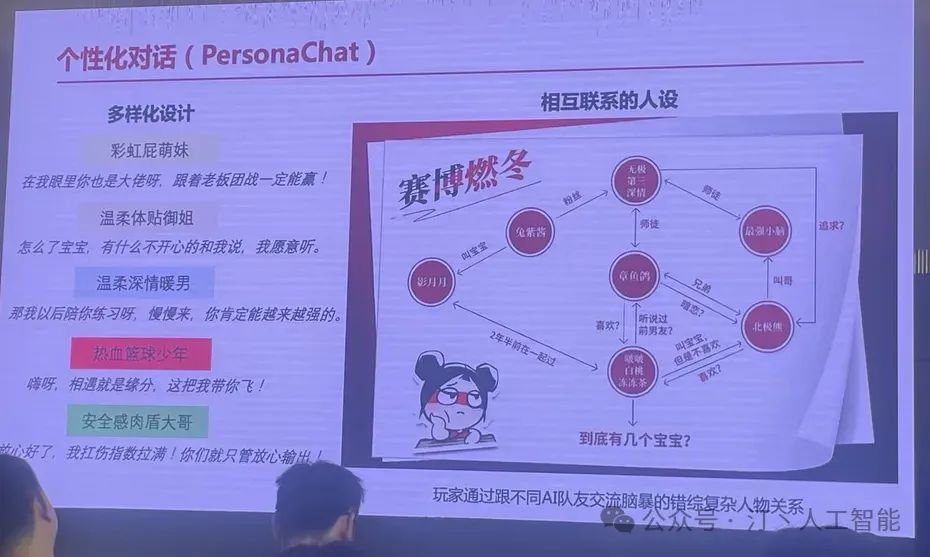
这种方案的好处是,每个模块都相对比较成熟,每个模块的质量可以得到保证,整个系统可以相比较千亿的模型相比较做的轻量级,系统的时延反馈可以做的好,体验顺畅。
5 小结
现在以 transformer 架构的模型,虽然表现出了很强的泛化能力,并且越大的模型,越大规模的数据训练,越能激发更多的创造能力,也经常会让人眼前一亮。但是对固定的业务来说,垂域的小模型是一个非常好的方案,他让业务能够快速的迭代。
但是现在的模型还是太过程式化了,对特殊 token 的理解还是非常敏感,若训练和使用不匹配,经常会出现
-
输入轮次过多的遗忘问题
-
输出重复停不下来的问题
-
应该放到user的内容放到system导致输出不达预期的问题
而人类的思考方式,完全没有以上提及的问题。这种问题的出现或许来源于 transformer 本身,也有可能来自训练过程,总之还要解决的问题还有很多,但是 AI 辅助业务提效的时代已经到来。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}