






1、import libraries
import tensorflow as tf
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, UpSampling2D, Conv2DTranspose
from tensorflow.keras.constraints import max_norm
import matplotlib.pyplot as plt
import numpy as np
import gzip2、下载并查看数据集
! wget -O train-images.gz https://github.com/davidflanagan/notMNIST-to-MNIST/raw/master/train-images-idx3-ubyte.gz
! wget -O test-images.gz https://github.com/davidflanagan/notMNIST-to-MNIST/raw/master/train-images-idx3-ubyte.gz
! wget -O train-labels.gz https://github.com/davidflanagan/notMNIST-to-MNIST/raw/master/train-labels-idx1-ubyte.gz
! wget -O test-labels.gz https://github.com/davidflanagan/notMNIST-to-MNIST/raw/master/t10k-labels-idx1-ubyte.gz# function for extracting images
def image_data(filename, num_images):
with gzip.open(filename) as f:
f.read(16)
buf = f.read(28 * 28 * num_images)
data = np.frombuffer(buf, dtype=np.uint8).astype(np.float32)
data = data.reshape(num_images, 28,28)
return data
# function for extracting labels
def image_labels(filename, num_images):
with gzip.open(filename) as f:
f.read(8)
buf = f.read(1 * num_images)
labels = np.frombuffer(buf, dtype=np.uint8).astype(np.int64)
return labels
# import train and test data
train_data = image_data('train-images.gz', 60000)
test_data = image_data('test-images.gz', 10000)
# import train and test labels
train_labels = image_labels('train-labels.gz', 60000)
test_labels = image_labels('test-labels.gz', 10000)
img_width, img_height = 28, 28
input_shape = (img_width, img_height, 1)
batch_size = 120
no_epochs = 50
validation_splits = 0.2
max_norm_value = 2.0
noise_factor = 0.5
label_dict = {i: a for i,a in zip(range(10), 'ABCDEFGHIJ')}
digits = [[train_data[idx], train_labels[idx]] for idx in
np.random.randint(len(train_data), size=50)]
plt.figure(figsize=(15,10))
for i in range(50):
plt.subplot(5, 10, i+1%10)
plt.imshow(digits[i][0])
plt.title(label_dict[digits[i][1]], fontsize=18)
plt.xticks([])
plt.yticks([])
plt.show()输出:
3、创建噪声图像
train_data = train_data.reshape(-1, 28,28, 1)
test_data = test_data.reshape(-1, 28,28, 1)
train_data = train_data / np.max(train_data)
test_data = test_data / np.max(test_data)
noise_train = train_data + noise_factor * np.random.normal(0,1,train_data.shape)
noise_test = test_data + noise_factor * np.random.normal(0, 1, test_data.shape)
fig, ax = plt.subplots(1,10)
fig.set_size_inches(20, 4)
for i in range(10):
curr_img = np.reshape(train_data[i], (28,28))
curr_lbl = train_labels[i]
ax[i].imshow(curr_img)
ax[i].set_xticks([])
ax[i].set_yticks([])
plt.show()
fig, ax = plt.subplots(1,10)
fig.set_size_inches(20, 4)
for i in range(10):
curr_img = np.reshape(noise_train[i], (28,28))
curr_lbl = train_labels[i]
ax[i].imshow(curr_img)
ax[i].set_xticks([])
ax[i].set_yticks([])
plt.show()输出:
4、定义两个自动编码器
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3),
activation='relu',
kernel_initializer='he_uniform',
padding='same',
input_shape=input_shape))
model.add(MaxPooling2D((2, 2),
padding='same'))
model.add(Conv2D(64, (3, 3),
activation='relu',
kernel_initializer='he_uniform',
padding='same'))
model.add(MaxPooling2D((2, 2),
padding='same'))
model.add(Conv2D(128, (3, 3),
activation='relu',
kernel_initializer='he_uniform',
padding='same'))
model.add(Conv2D(128, (3, 3),
activation='relu',
kernel_initializer='he_uniform',
padding='same'))
model.add(UpSampling2D((2, 2),
interpolation='bilinear'))
model.add(Conv2D(64, (3, 3),
activation='relu',
kernel_initializer='he_uniform',
padding='same'))
model.add(UpSampling2D((2, 2),
interpolation='bilinear'))
model.add(Conv2D(1, (3, 3),
activation='sigmoid',
padding='same'))
model.summary()
# model layers for autoencoder
model2 = Sequential()
model2.add(Conv2D(64, kernel_size=(3,3),
kernel_constraint=max_norm(max_norm_value),
activation = 'relu',
kernel_initializer= 'he_uniform',
input_shape = input_shape))
model2.add(Conv2D(32, kernel_size=(3,3),
kernel_constraint=max_norm(max_norm_value),
activation='relu',
kernel_initializer='he_uniform'))
model2.add(Conv2DTranspose(32,
kernel_size=(3,3),
kernel_constraint=max_norm(max_norm_value),
activation='relu',
kernel_initializer='he_uniform'))
model2.add(Conv2DTranspose(64, kernel_size=(3,3),
kernel_constraint= max_norm(max_norm_value),
activation='relu',
kernel_initializer= 'he_uniform'))
model2.add(Conv2D(1, kernel_size=(3,3),
kernel_constraint=max_norm(max_norm_value),
activation='sigmoid',
padding = 'same'))
model2.summary()5、训练
model2.compile(optimizer='adam',
loss = 'binary_crossentropy')
model2.fit(noise_train,
train_data,
validation_split= validation_splits,
epochs=no_epochs,
batch_size=batch_size)注意model1用的是无参数的上采样,model2用的是转置卷积

6、去噪展示
fig_samples = noise_test[:10]
fig_original = test_data[:10]
fig_denoise = model2.predict(fig_samples)
for i in range(0, 10):
noisy_img = noise_test[i]
original_img = test_data[i]
denoise_img = fig_denoise[i]
fig, axes = plt.subplots(1, 3)
fig.set_size_inches(6, 2.8)
axes[0].imshow(noisy_img.reshape(28, 28))
axes[0].set_xticks([])
axes[0].set_yticks([])
axes[0].set_title('Noisy')
axes[1].imshow(original_img.reshape(28, 28))
axes[1].set_xticks([])
axes[1].set_yticks([])
axes[1].set_title('Original')
axes[2].imshow(denoise_img.reshape(28, 28))
axes[2].set_xticks([])
axes[2].set_yticks([])
axes[2].set_title('Denoised')
plt.show()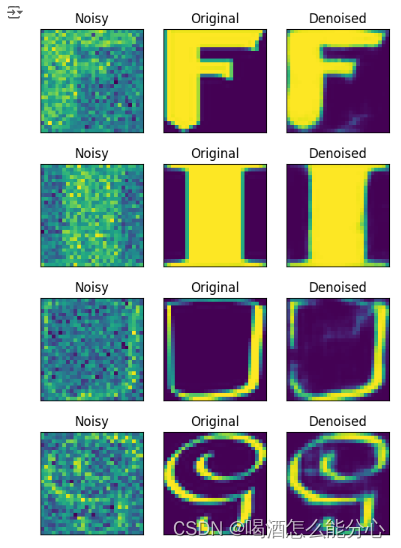















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









