1、定义VAE类、训练create_train_state类
from typing import Tuple, Sequence
from functools import partial
import jax
import jax.numpy as jnp
import numpy as np
import flax
import flax.linen as nn
from flax.training import train_state
import optax
class Encoder(nn.Module):
latent_dim: int
hidden_channels: Sequence[int]
@nn.compact
def __call__(self, X, training):
for channel in self.hidden_channels:
X = nn.Conv(channel, (3, 3), strides=2, padding=1)(X)
X = nn.BatchNorm(use_running_average=not training)(X)
X = jax.nn.relu(X)
X = X.reshape((-1, np.prod(X.shape[-3:])))
mu = nn.Dense(self.latent_dim)(X)
logvar = nn.Dense(self.latent_dim)(X)
return mu, logvar
class Decoder(nn.Module):
output_dim: Tuple[int, int, int]
hidden_channels: Sequence[int]
@nn.compact
def __call__(self, X, training):
H, W, C = self.output_dim
# TODO: relax this restriction
factor = 2 ** len(self.hidden_channels)
assert (
H % factor == W % factor == 0
), f"output_dim must be a multiple of {factor}"
H, W = H // factor, W // factor
X = nn.Dense(H * W * self.hidden_channels[-1])(X)
X = jax.nn.relu(X)
X = X.reshape((-1, H, W, self.hidden_channels[-1]))
for hidden_channel in reversed(self.hidden_channels[:-1]):
X = nn.ConvTranspose(
hidden_channel, (3, 3), strides=(2, 2), padding=((1, 2), (1, 2))
)(X)
X = nn.BatchNorm(use_running_average=not training)(X)
X = jax.nn.relu(X)
X = nn.ConvTranspose(C, (3, 3), strides=(2, 2), padding=((1, 2), (1, 2)))(X)
X = jax.nn.sigmoid(X)
return X
def reparameterize(key, mean, logvar):
std = jnp.exp(0.5 * logvar)
eps = jax.random.normal(key, logvar.shape)
return mean + eps * std
class VAE(nn.Module):
variational: bool
latent_dim: int
output_dim: Tuple[int, int, int]
hidden_channels: Sequence[int]
def setup(self):
self.encoder = Encoder(self.latent_dim, self.hidden_channels)
self.decoder = Decoder(self.output_dim, self.hidden_channels)
def __call__(self, key, X, training):
mean, logvar = self.encoder(X, training)
if self.variational:
Z = reparameterize(key, mean, logvar)
else:
Z = mean
recon = self.decoder(Z, training)
return recon, mean, logvar
def decode(self, Z, training):
return self.decoder(Z, training)
class TrainState(train_state.TrainState):
batch_stats: flax.core.FrozenDict[str, jnp.ndarray]
beta: float
def create_train_state(
key, variational, beta, latent_dim, hidden_channels, learning_rate, specimen
):
vae = VAE(variational, latent_dim, specimen.shape, hidden_channels)
key_dummy = jax.random.PRNGKey(42)
(recon, _, _), variables = vae.init_with_output(key, key_dummy, specimen, True)
assert (
recon.shape[-3:] == specimen.shape
), f"{recon.shape} = recon.shape != specimen.shape = {specimen.shape}"
tx = optax.adam(learning_rate)
state = TrainState.create(
apply_fn=vae.apply,
params=variables["params"],
tx=tx,
batch_stats=variables["batch_stats"],
beta=beta,
)
return state
@jax.vmap
def kl_divergence(mean, logvar):
return -0.5 * jnp.sum(1 + logvar - jnp.square(mean) - jnp.exp(logvar))
@jax.jit
def train_step(state, key, image):
@partial(jax.value_and_grad, has_aux=True)
def loss_fn(params):
variables = {"params": params, "batch_stats": state.batch_stats}
(recon, mean, logvar), new_model_state = state.apply_fn(
variables, key, image, True, mutable=["batch_stats"]
)
'''apply_fn:通常设置为 ``model.apply()``。保留在此数据类中,以方便在训练循环中为 ``train_step()`` 函数提供更短的参数列表。'''
loss = jnp.sum((recon - image) ** 2) + state.beta * jnp.sum(
kl_divergence(mean, logvar)
)
return loss.sum(), new_model_state
(loss, new_model_state), grads = loss_fn(state.params)
state = state.apply_gradients(
grads=grads, batch_stats=new_model_state["batch_stats"]
)
return state, loss
@jax.jit
def test_step(state, key, image):
variables = {"params": state.params, "batch_stats": state.batch_stats}
recon, mean, logvar = state.apply_fn(variables, key, image, False)
return recon, mean, logvar
@jax.jit
def decode(state, Z):
variables = {"params": state.params, "batch_stats": state.batch_stats}
decoded = state.apply_fn(variables, Z, False, method=VAE.decode)
return decoded
2、训练
from torch import Generator
from torch.utils.data import DataLoader
import torchvision.transforms as T
import torchvision.datasets as datasets
#from torchvision.datasets import fashionMNIST
ckpt_dir = "/content/drive/MyDrive/Colab_Notebooks/checkpoint"
batch_size = 256
latent_dim = 20
hidden_channels = (32, 64, 128, 256, 512)
lr = 1e-3
specimen = jnp.empty((32, 32, 1))
variational = True
beta = 1
target_epoch = 30
name = "VAE"
transform = T.Compose([T.Resize((32, 32)), T.ToTensor()])
fashion_mnist_train = datasets.FashionMNIST("/tmp/torchvision", train=True, download=True, transform=transform)
generator = Generator().manual_seed(42)
loader = DataLoader(fashion_mnist_train, batch_size, shuffle=True, generator=generator)
key = jax.random.PRNGKey(42)
'''给定一个整数种子,创建一个伪随机数生成器 (PRNG) 密钥。
生成的密钥带有默认的 PRNG 实现,由可选的 ``impl`` 参数或 ``jax_default_prng_impl`` 配置标志确定。
参数:
seed:用作密钥值的 64 位或 32 位整数。
impl:指定 PRNG 实现的可选字符串(例如 ``'threefry2x32'``)
返回:
PRNG 密钥,可由随机函数以及 ``split``
和 ``fold_in`` 使用。
key:PRNG 密钥(来自 ``key``、``split``、``fold_in``)。num:可选,一个正整数(或整数元组),表示要生成的键的数量(或形状)。默认为2'''
state = create_train_state(key, variational, beta, latent_dim, hidden_channels, lr, specimen)
for epoch in range(target_epoch):
loss_train = 0
for X, _ in loader:
image = jnp.array(X).reshape((-1, *specimen.shape))
key, key_Z = jax.random.split(key)
state, loss = train_step(state, key_Z, image)
loss_train += loss
print(f"Epoch {epoch + 1}: train loss {loss_train}")
3、生成
import torch
fashion_mnist_test = datasets.FashionMNIST("/tmp/torchvision", train=False, download=True, transform=transform)
loader_test = DataLoader(fashion_mnist_test, batch_size, shuffle=True, generator=torch.Generator().manual_seed(42))
X, y = next(iter(loader_test))
image = jnp.array(X).reshape((-1, *specimen.shape)) / 255.0
recons = {
"original": image,
}
key = jax.random.PRNGKey(42)
key, *key_Z = jax.random.split(key, 5)
recon, _, _ = test_step(state, key_Z[0], image)
recons.update({"recon": recon})
(1)展示原图
import matplotlib.pyplot as plt
fig, axes = plt.subplots(5, 6, constrained_layout=True, figsize=plt.figaspect(0.6))
# Use plt.imshow() to display the image
for i in range(5):
for j in range(6):
axes[i, j].imshow(recons['original'][i * 6 + j], aspect=255 / 255)
axes[i, j].axis("off")
#plt.imshow(recon[0], aspect=218 / 178)
#plt.axis("off")
fig.suptitle("Original")
fig.show()

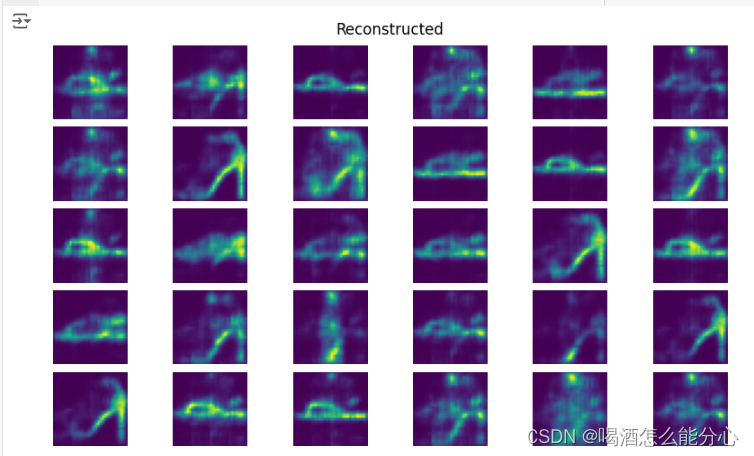
(2)展示看不清的重建图
import matplotlib.pyplot as plt
fig, axes = plt.subplots(5, 6, constrained_layout=True, figsize=plt.figaspect(0.6))
# Use plt.imshow() to display the image
for i in range(5):
for j in range(6):
axes[i, j].imshow(recons['recon'][i * 6 + j], aspect=255 / 255)
axes[i, j].axis("off")
#plt.imshow(recon[0], aspect=218 / 178)
#plt.axis("off")
fig.suptitle("Reconstructed")
fig.show()
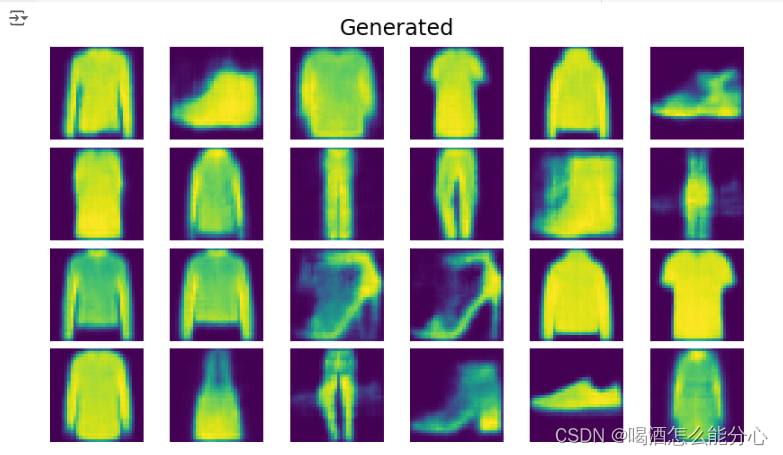
(3)展示decoder后生成的图片
key = jax.random.PRNGKey(42)
key, *key_Z = jax.random.split(key, 5)
generated_images = {}
Z = jax.random.normal(key_Z[0], (24, latent_dim))
generated_image = decode(state, Z)
#generated_images[name] = generated_image
fig, axes = plt.subplots(4, 6, constrained_layout=True, figsize=plt.figaspect(0.6))
for row in range(4):
for col in range(6):
axes[row, col].imshow(generated_image[6*row+col], aspect=255 / 255)
axes[row, col].axis("off")
fig.suptitle("Generated", fontsize="xx-large")
fig.show()






















 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









