









感知机的产生
(1)神经元模型
第一个正式的神经元模型是由沃伦·麦卡洛克(Warren Maculloach)和沃尔特·皮茨(Walter Pitts)于1934年提出的。这个模型看起来很像组成计算机的逻辑门。他们曾表明,把二进制输入值加起来,并在和大于一个阈值时输出1,否则输出0的神经元模型,可以模拟基本的或/与/非逻辑函数。这在人工智能的早期时代可不得了——当时的主流思想是,计算机能够做正式的逻辑推理将本质上解决人工智能问题。但是麦克洛克-皮茨神经元做不了的事情就是学习。
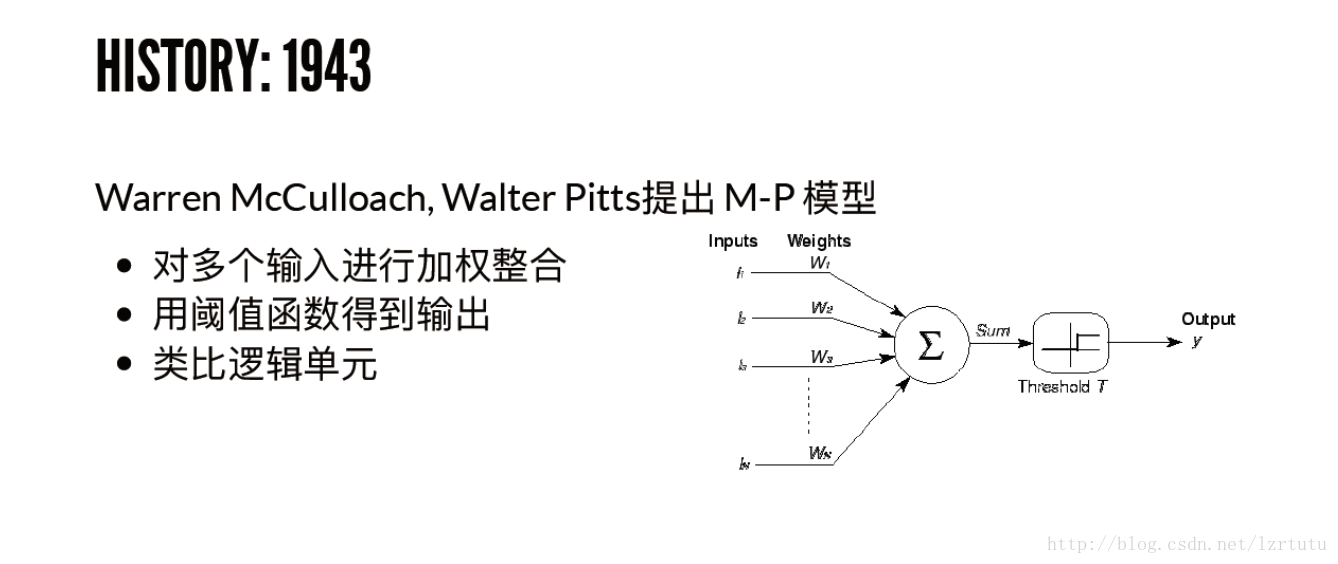
(2)感知机的提出
赫布提出了一个出人意料并影响深远的想法,称知识和学习发生在大脑主要是通过神经元间突触的形成与变化,简要表述为赫布法则:当细胞A的轴突足以接近以激发细胞B,并反复持续地对细胞B放电,一些生长过程或代谢变化将发生在某一个或这两个细胞内,以致A作为对B放电的细胞中的一个,效率增加。
罗森布拉特受到唐纳德·赫布(Donald Hebb) 基础性工作的启发,想出一个让这种人工神经元学习的办法。他称之为感知机。
感知机并没有完全遵循赫布的想法,但通过调输入值的权重,可以有一个非常简单直观的学习方案:给定一个有输入输出实例的训练集,感知机应该「学习」一个函数:对每个例子,若感知机的输出值比实例低太多,则增加它的权重,否则若设比实例高太多,则减少它的权重。更正式一点儿的该算法如下:
1、从感知机有随机的权重和一个训练集开始。
2、对于训练集中一个实例的输入值,计算感知机的输出值。
3、如若感知机的输出值和实例中默认正确的输出值不同:(1)若输出值应该为0但实际为1,减少输入值是1的例子的权重。(2)若输出值应该为1但实际为0,增加输入值是1的例子的权重。
4、对于训练集中下一个例子做同样的事,重复步骤2-4直到感知机不再出错。
这个过程很简单,产生了一个简单的结果:一个输入线性函数(加权和),正如线性回归被非线性激活函数「压扁」了一样(对带权重求和设定阈值的行为)。当函数的输出值是一个有限集时(例如逻辑函数,它只有两个输出值True/1 和 False/0),给带权重的和设置阈值是没问题的,所以问题实际上不在于要对任何输入数据集生成一个数值上连续的输出(即回归类问题),而在于对输入数据做好合适的标签(分类问题)。

罗森布拉特用定制硬件的方法实现了感知机的想法(在花哨的编程语言被广泛使用之前),展示出它可以用来学习对20×20像素输入中的简单形状进行正确分类。自此,机器学习问世了——建造了一台可以从已知的输入输出对中得出近似函数的计算机。在这个例子中,它只学习了一个小玩具般的函数,但是从中不难想象出有用的应用,例如将人类乱糟糟的手写字转换为机器可读的文本。
感知机模型的定义
感知机(perceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值。感知机对应于输入空间中将实例划分为正负两类的分离超平面,属于判别模型。感知机学习旨在求出将训练数据进行线性划分的分离超平面,为此导入了基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。感知机学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。感知机是神经网络与支持向量机的基础。
简单说就是个二分类的线性分类模型,感知机学习,就是通过训练数据集,求得感知机模型,即求的模型参数。
由输入空间到输出空间的如下函数称为感知机:
w叫做权值(weight)或权值向量,b叫做偏置(bias)。
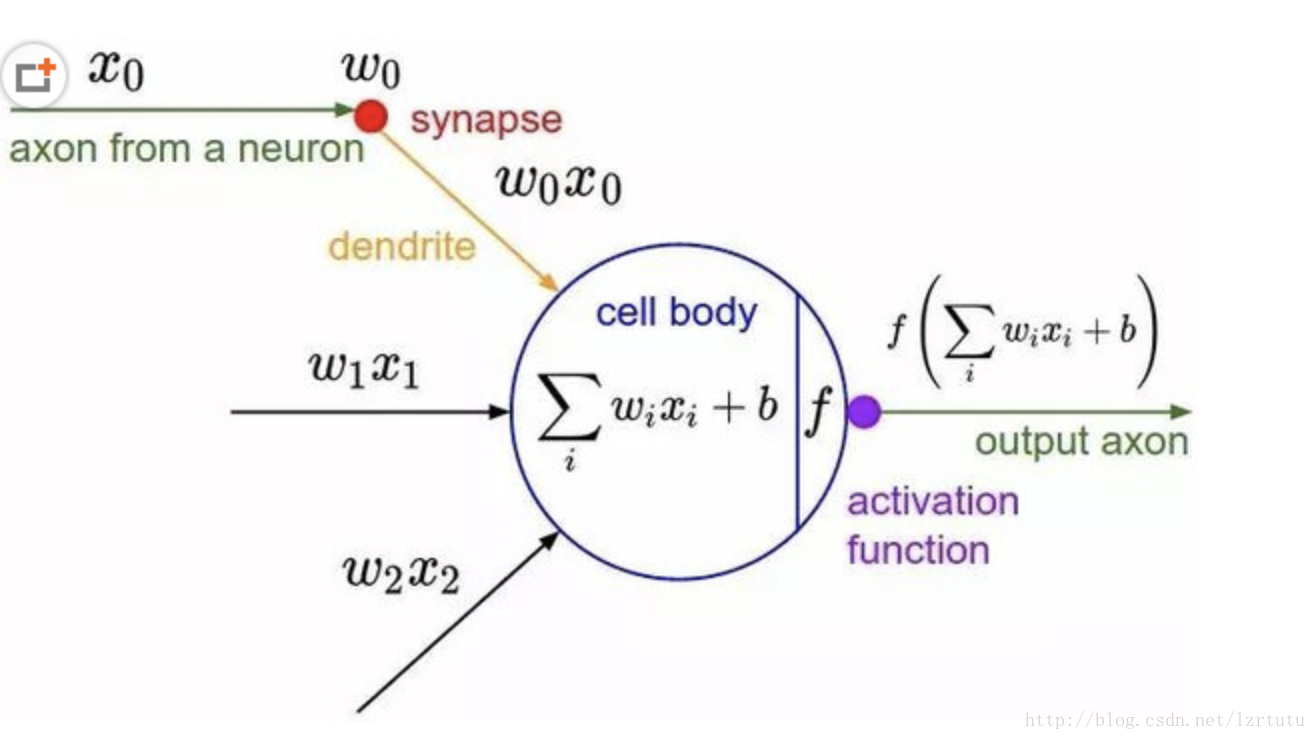
感知机模型的原理:给每一个属性一个权重w,对属性值和权重的乘积求和,将这个值和一个阀值(0/1)进行比较,可以判定比如是否录用这个应聘者。
感知机的几何解释:线性方程.
线性分类器的几何表示:直线、平面、超平面。
对应于特征空间Rn中的一个超平面S,其中w是超平面的法向量[注],b是超平面的截距。这个超平面将特征空间划分为两个部分,位于两部分的点分别被分为正、负两类。因此,超平面S称为分离超平面(separating hyperplanes)。
比如在二维平面里,分界是一条直线的情形下,y=wTx,那么分界线对应的y取值都是0,此时对于这条线来说,w就是分界线的法向量。
感知机是如何学习的
PLA算法详细的表述见网址:http://blog.csdn.net/hulingyu1106/article/details/51212632
感知机算法(PLA)的代码实现
import numpy as np
x = np.array([[3,3],[4,3],[1,1]])#创建数据集,共3个实例
y = np.array([1,1,-1]) #创建标签
history = [] #存储迭代学习过程中的w,b值,便于可视化绘图
gramMatrix = x.dot(x.T) #计算Gram矩阵,后面需要多次用到
print ("gramMatrix = ",gramMatrix)
alpha = np.zeros(len(x)) #初始化alpha为零向量
b = 0 #b为回归直线截距
learnRate = 1 #初始化为0;learnRate为学习率,设为1
k = 0; i = 0 #k用来计算迭代次数;i用来判定何时退出while循环
while 1:
if y[i] * (np.sum(alpha * y * gramMatrix[i])+ b)<=0: #误分条件:若某一数据点被错误分类
alpha[i] = alpha[i] + learnRate #更新 alpha 值
b = b + learnRate * y[i] #更新 b 值
i = 0 #i 赋值为0,再遍历一次所有的数据集
k = k + 1 #k + 1 即迭代次数加1
history.append([(alpha * y.T).dot(x), b]) #存储w,b
print ("iteration counter =",k)
print ("alpha = ",alpha)
print ("b = ", b)
continue
else: #若某一数据点被正确分类
i = i + 1
print ("i = ",i)
if i >= x.shape[0]: #退出while循环条件,即 i >= 3,所有数据点都能正确分类
print ("iteration finish")
break #break 退出wile循环
w = (alpha*y.T).dot(x) #计算得到权值 w
print ("w = ", w)
print ("b = ", b)
print ("history w,b = ",history)
可视化
import matplotlib.pyplot as plt
from matplotlib import animation
fig = plt.figure()
ax = plt.axes()
line, = ax.plot([], [], 'g', lw=2)
label = ax.text([], [], '')
def init():
global x,y,line,label
plt.axis([-6, 6, -6, 6])
plt.scatter(x[0:2,0],x[0:2,1],c ="r",label = "postive",s = 60) #画正样本点
plt.scatter(x[2,0],x[2,1],c = "y",label = "negtive",s =60) #画负样本点
plt.grid(True)
plt.xlabel('X1')
plt.ylabel('X2')
plt.title('myPerceptron')
return line, label #返回值为line,label对象,表示这两个对象有动画效果
def animate(i): #形参 i 表示帧数,即 animation.FuncAnimation 函数形参列表中的frames属性
global history, ax, line, label
w = history[i][0]
b = history[i][1]
if w[1] == 0: return line, label
x1 = -6.0 #点(x1,y1)和点(x2,y2)确定分类超平面
y1 = -(b + w[0] * x1) / w[1]
x2 = 6.0
y2 = -(b + w[0] * x2) / w[1]
line.set_data([x1, x2], [y1, y2])#画出分类超平面
x1 = 0.0
y1 = -(b + w[0] * x1) / w[1]
label.set_text(str( history[i][0]) + ' ' + str(b)) #在点 (0,y1) 上绘制文本便签
label.set_position([x1, y1])
return line, label
anim = animation.FuncAnimation(fig, animate,init_func=init, frames=len(history), interval=1000, repeat=True,blit=True)
plt.legend(fancybox = True)
plt.show()
参考地址:
http://blog.csdn.net/hulingyu1106/article/details/51212632
https://www.sohu.com/a/143544399_717210
http://www.knowsky.com/943203.html
http://blog.csdn.net/webchengxuyuan/article/details/61427825
http://www.chaoqi.net/renwu/2016/0307/4207.html
http://www.chaoqi.net/renwu/2016/0307/4207.html
https://www.cnblogs.com/xpvincent/archive/2013/02/15/2912836.html
About TuTu
嘟嘟嘟,今天志辉哥哥貌似毕业了。Congratlate。















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









