







Tensor Core 基本原理
在英伟达的通用 GPU 架构中,主要存在三种核心类型:CUDA Core、Tensor Core 以及 RT Core。其中,Tensor Core 扮演着极其关键的角色。
Tensor Core 是针对深度学习和 AI 工作负载而设计的专用核心,可以实现混合精度计算并加速矩阵运算,尤其擅长处理半精度(FP16)和全精度(FP32)的矩阵乘法和累加操作。Tensor Core 在加速深度学习训练和推理中发挥着重要作用。
本文内容将通过三个层次逐步深入地探讨卷积与 Tensor Core 之间的关系、Tensor Core 的基础工作原理,以及 Tensor Core 架构的发展历程。同时结合实际代码示例,旨在帮助读者不仅能够理解在框架层面如何利用 Tensor Core 实现训练加速的具体细节,还能对 CUDA 编程有初步的了解。
这一系列内容将为读者揭开 Tensor Core 技术的神秘面纱,提供一个全面且条理清晰的认识。
发展历程
在我们深入探讨之前,先简要回顾一下英伟达 GPU 架构的演变历程。2006 年,英伟达发布 Tesla 架构,从此所有 GPU 都带有 CUDA Core,2017 年在 Volta 架构中首次提出 Tensor Core,2018 年在 Turing 架构中首次提出 RT Core。
在 GPU 中,处理核心通常被称为处理单元或处理器核心,用于执行计算任务。在英伟达的 GPU 架构中,在 Fermi 架构之前,处理核心被称为 Stream Processor(SPs)。这些 SPs 是用于执行并行计算任务的小型处理器,每个 SP 可以执行一个线程的计算任务。
2010 年,在 Fermi 架构中,英伟达对处理核心进行了改进和调整,引入了新的设计和特性,包括更好的线程调度和管理机制,更高效的内存访问模式,以及更多的可编程功能。在 Fermi 架构之后,英伟达将处理核心更名为 CUDA 核心,以强调其与 CUDA(计算统一设备架构)编程模型的紧密集成。
如图所示,在 Fermi 架构中其计算核心由 16 个 SM(Stream Multiprocesser)组成,每个 SM 包含 2 个线程束(Warp),一个 Warp 中包含 16 个 Cuda Core,共 32 个 CUDA Cores。每一个 Cuda Core 由 1 个浮点数单元 FPU 和 1 个逻辑运算单元 ALU 组成。
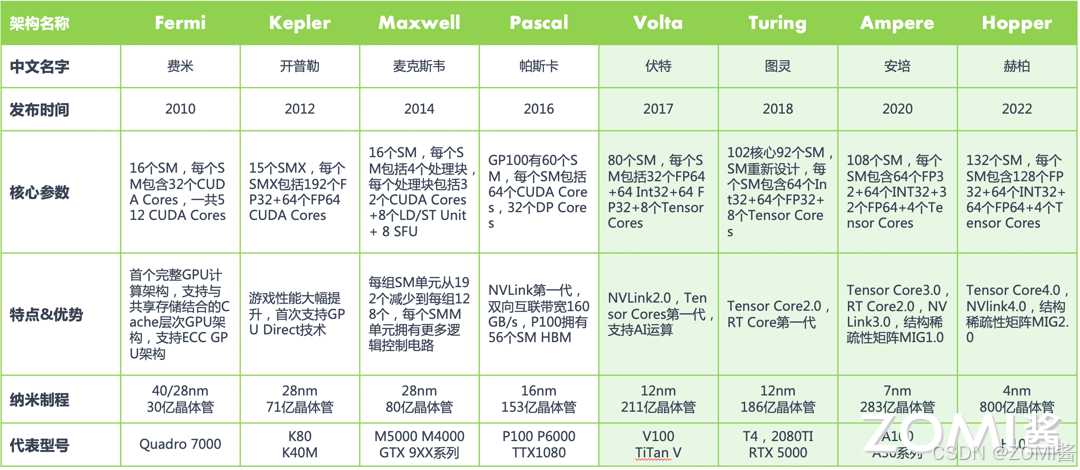
由于 CUDA Core 在显卡里面是并行运算,也就是说大家分工计算。从逻辑上说,CUDA Core 越多,算力也就相应越强。所以说从 Fermi 架构开始,2012 年的 Kepler 架构和 2014 年的 Maxwell 架构,都在这个基础上疯狂加倍增加 Cuda Core。
到了 2016 年的 Pascal 架构,英伟达 GPU 开始往深度学习方向进行演进,NVLink 也是这个时候开始引入的。2017 年提出的 Volta 架构,引入了张量核 Tensor Core 模块,用于执行融合乘法加法,标志着第一代 Tensor Core 核心的诞生。
自从 Volta 架构搭载了首代 Tensor Core 以来,英伟达在每一次的架构升级中都不断对 Tensor Core 进行优化和更新,每一轮的更新都带来了新的变化和提升。接下来,我们将逐步深入介绍其原理和这些演进过程。
卷积计算
卷积运算是深度学习和神经网络中常用的一种操作,用于从输入数据中提取特征。卷积操作通常用于处理图像数据,但也可以应用于其他类型的数据,如语音、文本等。在深度学习中,卷积运算通常与激活函数(如 ReLU)、池化层等结合使用,构成卷积神经网络(CNN),用于提取并学习数据中的特征,从而实现图像识别、分类、分割等任务。Tensor Core 则是英伟达推出的一种专为加速深度学习中的矩阵计算而设计的硬件加速器,要理解卷积与 Tensor Core 之间的关系,我们需要先了解卷积运算的本质。
CNN vs GEMM
在深度学习中,卷积运算通常指的是利用一个小的、可学习的过滤器(或称为卷积核)在输入数据(如图像)上滑动,并在每个位置计算过滤器与其覆盖区域的元素逐点相乘后的总和,这个过程可以捕捉到局部特征。对于多通道输入,卷积运算会对每个通道执行此操作,并将结果累加起来得到最终的输出。当应用于图像处理时,这种机制使得卷积网络能够有效地识别图像中的边缘、纹理等特征。
卷积神经网络 CNN 一般包含许多卷积层,这些层通过卷积运算提取输入数据的特征。在算法层面上,卷积运算的加速通常涉及到一个关键步骤——数据重排,即执行 Im2Col 操作。
Im2Col 操作的目的是将卷积运算转换为矩阵乘法,这样做有几个显著的好处。首先,它允许利用已有的高效矩阵乘法算法(如 GEMM,General Matrix Multiply)来加速卷积计算。其次,这种转换可以减少重复的内存访问,因为在传统的卷积运算中,同一个输入元素可能会被多个卷积核重复使用。
Im2Col 是计算机视觉领域中将图片转换成矩阵的矩阵列(Column)的计算过程。由于二维卷积的计算比较复杂不易优化,因此在 AI 框架早期,Caffe 使用 Im2Col 方法将三维张量转换为二维矩阵,从而充分利用已经优化好的 GEMM 库来为各个平台加速卷积计算。最后,再将矩阵乘得到的二维矩阵结果使用 Col2Im 将转换为三维矩阵输出。
Img2col 算法主要包含两个步骤,首先使用 Im2Col 将输入矩阵展开一个大矩阵,矩阵每一列表示卷积核需要的一个输入数据,其次使用上面转换的矩阵进行 Matmul 运算,得到的数据就是最终卷积计算的结果。
卷积默认采用数据排布方式为 NHWC,输入维度为 4 维 (N, IH, IW, IC),卷积核维度为(OC, KH, KW , IC),输出维度为(N, OH, OW , OC)。
Im2Col 算法计算卷积的过程,具体简化过程如下:

- 将输入由 N × I H × I W × I C N×IH×IW×IC N×IH×IW×IC 根据卷积计算特性展开成 ( O H × O W ) × ( N × K H × K W × I C ) (OH×OW)×(N×KH×KW×IC) (OH×OW)×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









