






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Ayoosh Kathuria
编译:ronghuaiyang
与大多数机器学习库一样,TensorFlow是“概念密集型和代码精简型”的。语法并不难学。但是理解它的概念是非常重要的。

与大多数机器学习库一样,TensorFlow是“概念密集型和代码精简型”的。语法并不难学。但是理解它的概念是非常重要的。
Tensor是什么?
根据维基百科,“张量是一个几何对象,它以多线性的方式将几何向量、标量和其他张量映射到一个结果张量。因此,向量和标量本身,通常已经在基础物理和工程应用中使用,被认为是最简单的张量。此外,来自向量空间对偶空间的向量,它提供了几何向量,也包括作为张量。在这种情况下,几何主要是为了强调任何坐标系选择的独立性。”
别担心,事情没那么复杂。当处理一个有多个变量的问题时,将它们以向量或矩阵的形式集合在一起通常是很方便的,这样就更容易对它们进行线性运算。大多数机器学习都是基于这样的矩阵运算——将一组输入值一起处理,得到一组输出值。
例如,在“良好的旧贷款批准问题”中,我们考虑了主体的几个参数(过去贷款的数量、归还时间等),并用适当的权重将它们加起来——得到一个称为信用评级的输出数。这是用简单的矩阵乘法实现的。
这样的矩阵乘法只给出了一种情况的结果。当我们想用数据训练一个神经网络来处理上百万这样的情况时,我们不能把它们一个一个地相乘。这就是使用张量的地方。张量是一种数据结构,它表示矩阵、向量或标量的集合,允许我们同时对所有数据样本进行运算。这给了我们一个巨大的性能改进。
张量不需要有数值。它可以是一个输入值,一个常数,一个变量或者仅仅是对其他张量的数学运算的引用。
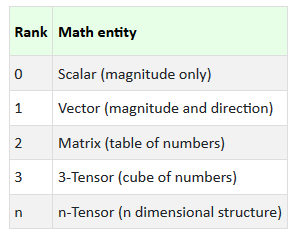
张量可以是三维(矩阵集合)或二维(向量集合)或一维(数字集合),甚至是0维(单个数字)。维数并不构成张量——重要的是对多个实体同时进行运算的概念。
秩
张量的维数,叫做张量的秩。因此我们有几种可能的排列。
常量张量
最简单的张量是一个常值张量。我们可以使用显式值来定义,也可以使用为常用值定义的方法来定义。
t1 = tf.constant(1729) # Constant Tensor with one element with value 1729
t2 = tf.constant([1,8,27,64]) # Constant Tensor of shape 4 with the given values
t3 = tf.zeros([10,20], tf.float32) # Constant Tensor of shape [10,20] - with each element set to 0
t4 = tf.zeros_like(t2) # Constant Tensor of shape and datatype same as t2, with all elements set to 0
t5 = tf.ones([5,6], tf.int32) # Constant Tensor of shape [5,6] with each value set to 1
t6 = tf.ones_like(t3) # Constant Tensor of shape and datatype same as t3, with each element set to 1
t7 = tf.eye(10) # Identity matrix of size 10
t8 = tf.linspace(1.0, 3.0,5) # [1.0, 1.5, 2.0, 2.5, 3.0] - Constant tensor with 5 equally spaced values from 1.0 to 3.0
t9 = tf.range(1.0,3.5, 0.5) # [1.0, 1.5, 2.0, 2.5, 3.0] - Same as Python range. Note that Range excludes last element
t11 = tf.random_normal([4,5], mean = 5.0, stddev = 4, seed=1) # Constant Tensor of shape [4,5] with random values of defined normal distribution
t12 = tf.random_uniform([4,5], maxval = 4.0, seed = 1) # Constant Tensor with random values with defined uniform distribution.注意,这并没有给张量赋常数值。它只创建了一个张量,这个张量可以在需要的时候求值。
变量张量
常量允许我们创建可用于计算的预定义值。但是没有变量的计算是不完整的。训练一个神经网络需要变量,这些变量可以表示在这个过程中要学习的权重。这些变量可以使用类tf.Variable生成。
weights1 = tf.Variable(tf.random_normal([10,10], stddev=1))
weights2 = tf.get_variable("weights2", [4,4], initializer = tf.ones_initializer)
constant = tf.Variable(tf.zeros([10,10]), trainable=False)每一个都生成一个变量张量。但第三种方法与其他方法略有不同。前两个张量可以训练。但是,第三个只是创建了不能改变的变量张量——就像一个常量一样。
做那样的事有什么用?为什么不定义一个常数呢?对于一个10x10的张量,创建一个常数张量更有意义。但是在处理大尺寸时,应该选择变量。这是因为变量得到了更有效的管理。
占位符
常量张量和变量张量在直观上类似于任何编程语言中的常量和变量。这并不需要时间去理解。占位符定义的张量将在代码运行之前获得一个值。在这个意义上,占位符可以与输入参数进行比较。
x = tf.placeholder(tf.int32)这就生成了一个张量x——保证它的值将在代码实际运行之前提供。
延迟执行
从设计上讲,TensorFlow基于延迟执行(尽管我们可以强制执行)。这意味着,在必须处理可用数据之前,它实际上并不处理这些数据。它只是收集我们输入的所有信息。只有当我们最终要求它处理时,它才会处理。
这种延迟性(讽刺的是)大大提高了处理速度。要理解这一点,我们需要理解TensorFlow的节点和图。

这是教科书上关于神经网络的观点。我们可以看到,我们有几个输入X~1~ - X~n~。这些构成了网络的第一层。第二层(隐藏层)是每个层与权值矩阵的点积,然后是激活函数,如sigmoid或relu。
第三层只是一个值,它是其权矩阵与第二层输出的点积。
节点
对于TensorFlow,每个实体都是一个节点。第一层有n+1个节点(n个输入和1个常量)。第二层有k+1个节点,第三层有1个节点。每个节点都由一个张量表示。
图
我们可以看到一些节点有一个常量值(例如偏差1),其中一些节点有变量值,比如权重矩阵——我们从随机初始化开始,并在整个过程中对其进行调优。我们有一些节点,它们的值只是基于其他节点上的一些计算,这些是相互依赖的节点,在我们得到之前节点的值之前,我们不能得到它们的值。
在这个网络中,我们在中间层有k个节点,在依赖于其他节点的最后一层有1个节点——我们有k+1个依赖节点和k个需要调优的变量。
编译
当我们创建单独的张量时,我们只是创建单独的节点并分配定义关系——这些关系还没有实现。定义完成后,我们启动compile()方法,该方法标识连接节点的图。
这是整个过程中的一个重要步骤。如果我们有循环依赖关系或任何其他原因可能破坏图形,此时就会识别出错误。
回话
TensorFlow计算总是在“会话”中执行。会话本质上是一个具有自己状态的环境。Session不是一个线程,但是如果我们有两个独立的计算需要一起运行——而不互相影响,我们可以使用Session。
sess1.run(A)
sess2.run(B)
sess1.run(C)
sess2.run(D)这里,A和C将在会话1下运行,并将看到一个环境,B和D将在会话2中运行,并将看到另一个环境。
一旦定义了节点并编译了图,就可以运行命令来获取图中特定节点的值。当我们这样做时,TensorFlow会回头检查此请求节点所需的所有节点。只有这些节点按适当的顺序计算。因此,只有在需要时才计算图中的节点,只有在需要的时候。
这对处理速度有很大的影响,也是TensorFlow的一个主要优势。
简单的代码的例子
要理解TensorFlow,理解常量、变量、占位符和会话的核心概念非常重要。现在让我们来做一个例子,它可以同时显示所有这些概念。
当然,我们首先导入TensorFlow模块
import tensorflow as tf现在,我们来定义几个张量。这里,t1和t2是常量,t3是占位符,t4是变量。
t1 = tf.ones([4,5])
t2 = tf.random_uniform([5,4], maxval = 4.0, seed = 2)
t3 = tf.placeholder(tf.float32)
t4 = tf.get_variable("t4", [4,4], initializer = tf.ones_initializer)这里,我们把t1定义为一个大小为4x5的常数张量,所有的值都设为1。t2是一个大小为5x4的常数张量,具有随机值。
t3是一个维度为0的占位符——一个带有float32的数字。
同时,我们定义了一个形状为4x4的变量t4。初始化器设置为ones_initializer。这意味着,每当我们初始化变量时,它的值将被设置为1。注意,只有在初始化变量时才会发生这种情况—而不是现在。
接下来,我们可以定义张量表达式
exp = tf.assign(t4, tf.matmul(t1,t2) * t3 + t4)这段代码取t1和t2的点积,与标量t3相乘,然后将其添加到t4。然后将这个结果分配给t4。因此,t4的值在每次执行该表达式时都会发生变化。注意,t3是一个占位符,所以当我们想要处理这个表达式时,必须提供t3的值。
同样,这段代码只定义了表达式。它不是立即执行的。
一切就绪后,我们现在就可以获得会话并开始处理张量了
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("Initialized variables\n##############################################")
print(t4.eval())
sess.run(exp, feed_dict = {t3:1})
print("\nAfter First Run\n##############################################")
print(t4.eval())
sess.run(exp, feed_dict = {t3:1})
print("\nAfter Second Run\n##############################################")
print(t4.eval())
sess.run(exp, feed_dict = {t3:1})
print("\nAfter Third Run\n##############################################")
print(t4.eval())这里,我们实际运行代码。我们从启动会话开始。我们必须初始化变量。到目前为止,t4只是声明,没有初始化。这里,我们初始化它。执行初始化代码。在本例中,它恰好是“tf.ones_initializer”。t4一开始是4x4张量,所有值都设为1。
接下来,我们运行表达式和feeddict。记住表达式有一个占位符t3。它不会计算,除非我们给它一个t3的值。这个值通过feeddict传递。每次运行更新t4并为其分配一个新值。
上面的代码生成如下输出:
Initialized variables
##############################################
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
After First Run
##############################################
[[11.483105 10.39291 11.380319 9.601738]
[11.483105 10.39291 11.380319 9.601738]
[11.483105 10.39291 11.380319 9.601738]
[11.483105 10.39291 11.380319 9.601738]]
After Second Run
##############################################
[[20.483215 16.11417 19.363663 15.015686]
[20.483215 16.11417 19.363663 15.015686]
[20.483215 16.11417 19.363663 15.015686]
[20.483215 16.11417 19.363663 15.015686]]
After Third Run
##############################################
[[32.022038 26.227888 28.65984 23.72137 ]
[32.022038 26.227888 28.65984 23.72137 ]
[32.022038 26.227888 28.65984 23.72137 ]
[32.022038 26.227888 28.65984 23.72137 ]]注意,t4在初始化之前没有值,只有在表达式在有效会话中运行时才更改其值。可以对表达式求三次值,以断言输出与我们期望的相同。
 —
END—
—
END—
英文原文:https://towardsdatascience.com/tensorflow-the-core-concepts-1776ea1732fa

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()















 3856
3856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









