







K-means聚类算法介绍与利用python实现的代码示例
更新时间:2017年11月13日 09:50:05 作者:ahu-lichang ![]() 我要评论
我要评论
scrolling="no" src="https://pos.baidu.com/s?hei=60&wid=700&di=u3431600<u=https%3A%2F%2Fwww.jb51.net%2Farticle%2F128055.htm&ant=0&ps=835x397&chi=1&cfv=0&tcn=1536370111&pis=-1x-1&cja=false&psr=1920x1080&dc=3&dai=2&tpr=1536370111217&exps=111000&prot=2&dtm=HTML_POST&ccd=24&pcs=1845x959&cpl=1&cec=GBK&col=en-US&ti=K-means%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%88%A9%E7%94%A8python%E5%AE%9E%E7%8E%B0%E7%9A%84%E4%BB%A3%E7%A0%81%E7%A4%BA%E4%BE%8B_python_%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&tlm=1536370111&dri=0&par=1855x1056<r=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D_5fOqfxgc-BQWSLqDG_EtY1vQjpDa5qcsT02MB7ia2qWuGXO-_2GQ6JPyzk81KR9fhBmtvs-jTkOlIrom2DF3_%26wd%3D%26eqid%3D92456a910003d575000000045b932597&cmi=2&cce=true&cdo=-1&drs=1&pss=1845x9471&ari=2&dis=0" width="700" height="60">
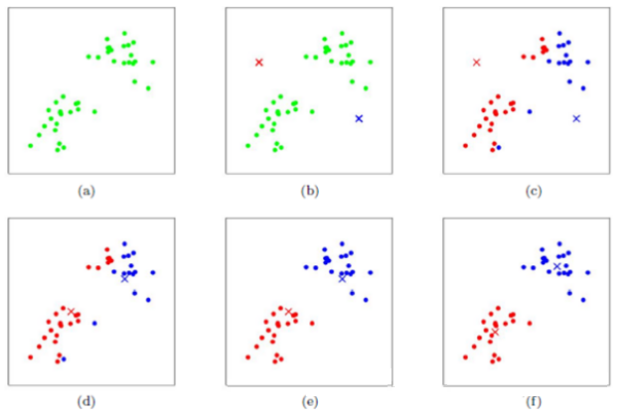
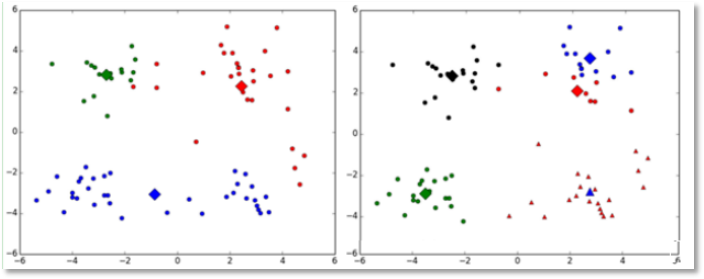
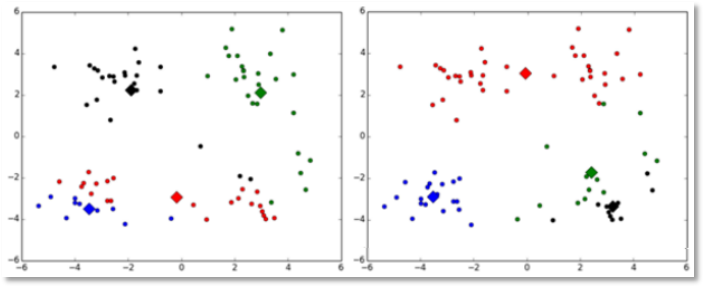
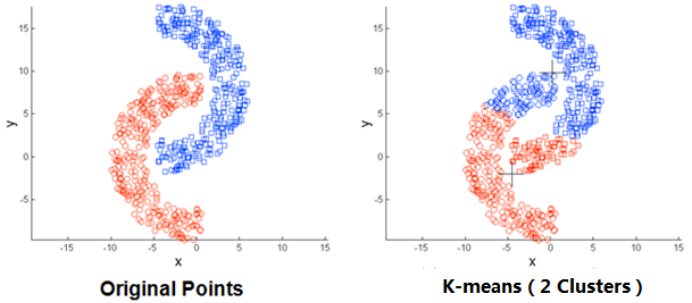
<div class="art_desc mt10"><div id="art_demo">K-means聚类算法(事先数据并没有类别之分!所有的数据都是一样的)是我们大家应该都听过的一种算法,下面这篇文章主要给大家介绍了关于K-means聚类算法的基础知识与利用python如何实现该算法的相关资料,需要的朋友可以参考借鉴,下面来一起看看吧。</div></div>
<div class="lbd clearfix"><a href="http://www.php.cn/course.html?ad51" target="_blank"><img src="//files.jb51.net/image/phpcn.png" width="690" height="99"></a>


























 5139
5139












 到【灌水乐园】发言
到【灌水乐园】发言









最新评论