






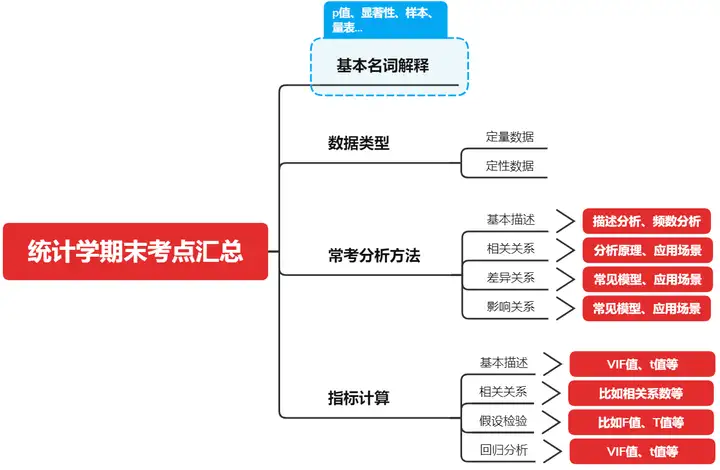
- 基本名词解释
- P值、显著性、显著水平、样本量、三大分布等
20+基本名词详细解释:
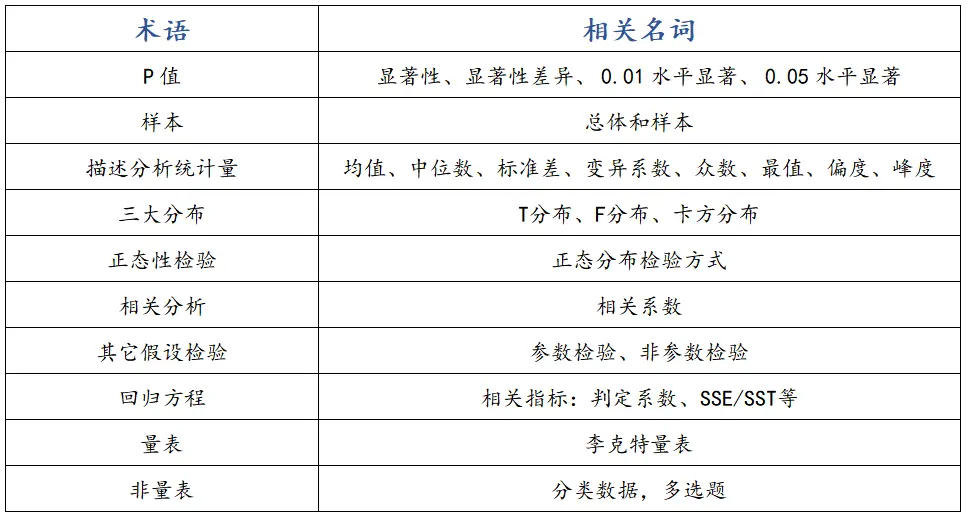
√P值:
相关名词:显著性、显著性差异、0.01水平显著、0.05水平显著。
P值,也称显著性值或者Sig.值,用于描述某件事情发生的概率情况,其取值范围是0~1,不包括0和1,通常情况下,一般有三个判断标准一个是0.01、0.05以及0.1。一般说明:如果p值小于0.01,则说明至少有99%的把握,如果p值小于0.05(且大于或等于0.01),则说明至少有95%的把握,如果p值小于0.1(且大于或等于0.05),则说明至少有90%的把握。
在统计语言表达上,如果p值小于0.01,则称作0.01水平显著,例如,研究人员分析X对Y是否存在影响关系时,如果X对应的p值为0.00(由于小数位精度要求,展示为0.00)PS:展示0.0000,并不是p值为0,而是无限接近于0,则说明X对Y存在影响关系这件事至少有99%的把握,统计语言描述为X在0.01水平上呈现显著性。
√样本:
总体和样本:
- 总体:所有研究对象的集合,是研究者希望研究的全部个体。
- 样本:从总体中选取的一部分研究对象,用于代表和推断总体的特性。
比如:研究全国大学生的生活费,那么全国的所有大学生就构成了“总体”。但是由于只能选择一部分大学生进行调查,这部分被调查的大学生就是“样本”。
√描述分析统计量:
- 均值
均值又称平均数,是最常用的一个数据代表值,均值既可以描述一组数据本身的整体平均情况,也可以用来作为不同组数据比较的一个标准,易受极端值影响。 - 中位数
中位数是一组数据从小到大顺序排列后的中值,它与均值不同的一点在于,中位数不受极端值影响。 - 标准差
标准差是指数据集的离散程度大小(数据波动情况),标准差越小说明数据分布越集中,标准差越大说明数据分布越分散易受极端值影响(方差是标准差的平方)。 - 变异系数
变异系数在分析观察值的差异性和异质性方面具有重要作用,主要用于比较不同组别数据的离散程度(适用于:随机变量的取值有量纲,或者取值大小有相对性的问题)。 - 众数
出现次数最多的变量值(易受极端值影响,适用于分类变量)。 - 最值
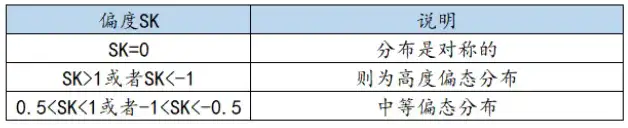
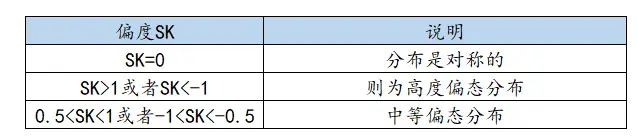
包括最大值和最小值,帮助研究者了解分析项的取值范围,比如可以查看是否有异常值等。 - 偏度
偏度也称偏态它是对数据分布对称性的测度,偏度可以描述数据的分布情况,具体如下:
分位数中四分位数使用比较多,四分位差也称四分间距(IQR),一般是指上四分位数和下四分位数之差,四分位数一般反映了中间50%的数据的离散程度。
数值越小说明中间数据越集中。反之,数值越大说明数据越分散,四分位差在一定程度上说明了中位数对一组数据的代表程度,一般适用于定量变量。
四分位数是将一组数据由小到大排序后,用3个点将全部数据分为4等份,与这3个点位置上相对应的数值称为四分位数,分别记为Q1、Q2、Q3。
√三大分布:
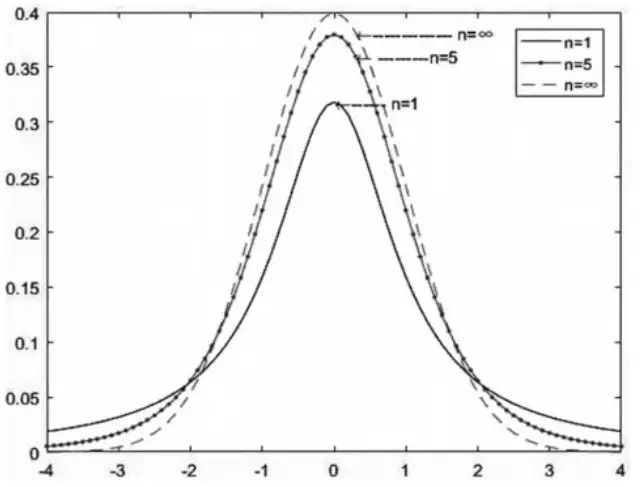
- T分布
t分布主要用于小样本情况下,根据样本数据来估计呈正态分布的总体的均值(适用情况:总体方差未知)
拓展:当样本量较小时,t分布曲线较平坦,两侧尾部较高;当样本量较大时,t分布曲线逐渐逼近正态分布曲线(可看图)。
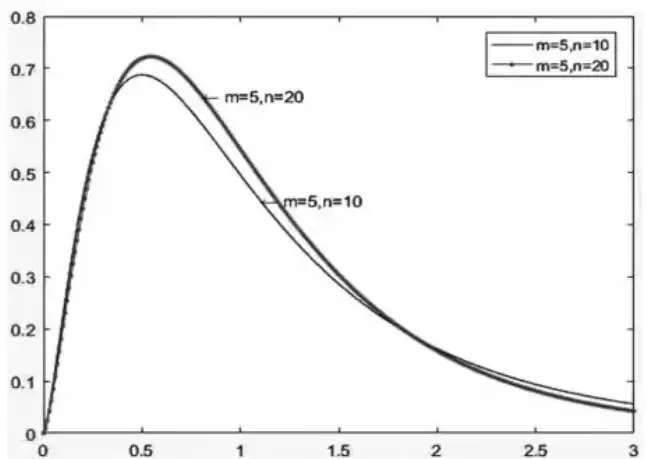
- F分布
F分布是两个独立的卡方分布随机变量的比值分布,它的形状取决于两个自由度k1和k2的大小。
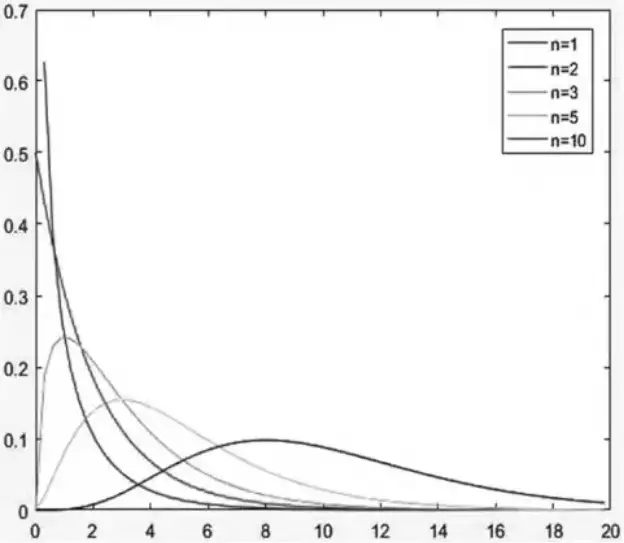
- 卡方分布
卡方分布是由一系列独立的标准正态随机变量的平方和所构成的分布。
√非负性
√可加性
图像:自由度越大,卡方分布越接近正态分布;自由度越小,卡方分布的偏斜程度越大。
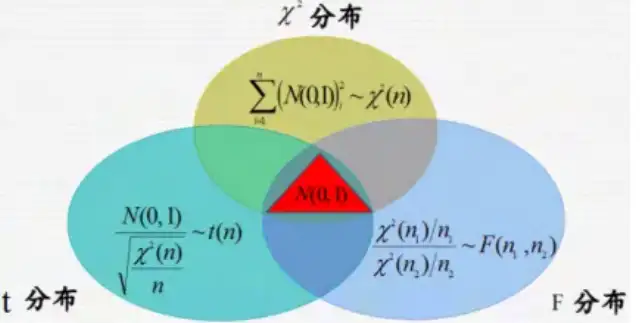
三个分布的Venn图:
√正态性检验:
正态性检验方法:
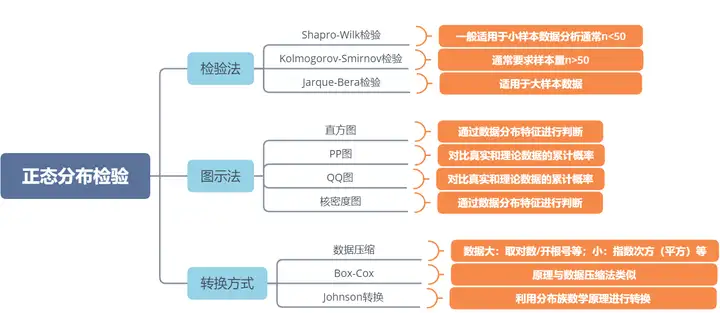
在实际数据分析过程中,理论上的正态分布很难存在,首先使用图示法进行探索,如果数据基本满足正态分布,也可以考虑使用部分替换方法,如方差分析时要求因变量 Y 满足正态分布,如果因变量 Y 不满足正态分布,则改用非参数检验方法即可。
√相关分析:
- Pearson相关系数
pearson 法则是一种经典的相关系数计算方法,主要用于表征线性相关性,假设2个变量服 从正态分布且标准差不为0,他的值介于-1到1之间,pearson相关系数的绝对值越接近于1,表明 2个变量的相关程度越高,即这2个变量越相似(需要满足正态分布)。 - Spearman相关系数
Spearman 相关性分析是对两组变量的等级大小作相关性分析,从而得到一个自变量与因变量之间的关系和自变量对因变量的影响强弱(不需要满足正态分布)。
√假设检验:
- 参数检验
T检验
研究定性数据和定量数据之间的差异性,定性数据特指两组,比如性别:男和女。
方差分析
研究定性数据和定量数据之间的差异性,定性数据特指两组以上,比如学历:专科、本科、硕士。
Z检验
Z检验假设适用于总体的标准差已知,但在实际中,我们往往不知道总体的标准差,只能根据样本数据来估计,这时可以考虑t检验等。 - 非参数检验
Mann-Whitney U检验
与t检验适用情况一致,但是不要求数据满足正态分布,检验效能低于t检验。
Kruskal-Wallis H检验
与方差分析适用情况一致,但是不要求数据满足正态分布,检验效能低于方差分析。
√回归方程
一般适用于研究影响关系,通过数据构建模型,得到对应变量之间的影响关系。常用的有线性回归和logistic回归,因变量为定量变量适合线性回归,定性变量适合logistic回归。
√量表:
量表答项类似于“非常同意”、“同意”、“不一定”、“不同意”、“非常不同意”等。大多数统计方法均只能针对量表,比如信度分析,效度分析,探索性因子分析等。
量表的尺度形式有多种,常见是五级量表,即五个答项,另外还会有七级量表,九级量表或者四级量表等。
√非量表:
不是量表题的题项,比如人口统计学、多选题、填空题、排序题等。
- 数据类型
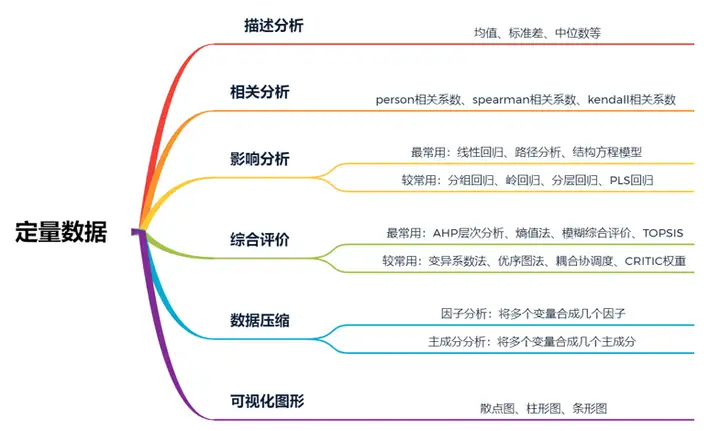
- 定量数据
数值型数据,可以比较数字大小,比如身高。
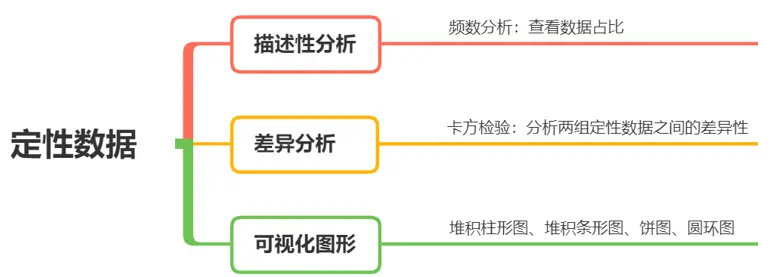
- 定性数据
非数值型数据,不可以比较数字大小,比如是否购买。
- 常考分析方法
- 基本描述
一般用于描述数据分析,常考计算,比如均值、中位数、分位数、变异系数等。定性数据也可以进行频数分析。 - 相关关系
常用于描述两个变量的相关性(需要为定量数据)。 - 差异关系
常用于描述不同组别之间的数据是否有差异(定量和定性)。常考的分析方法有方差分析、t检验、卡方检验、U检验和KW检验。 - 影响关系
用于分析两个或多个变量之间的关系,特别是当一个变量(称为“因变量”或“响应变量”)被视为另一个变量(或多个变量)的函数时。可用于预测和解释变量之间的关系。
- 指标计算
- 基本描述
腰围测定值为:71.0,73.5,81.0,72.5,76.5,75.5,76.0,69.0,76.5,72.5,79.5,74.0,66.0,69.0,73.0(计算背景)。
均值
均值,他是一组数据相加后除以数据个数得到的结果,均值是集中趋势的最主要测度值,它主要适用于定量数据而不适用于定类数据。其计算公式如下:
所以案例的均值为:
中位数
中位数是一组数据排序后处于中间位置上的变量值,想要得到15名大学生腰围的中位数,就需要先将数据排序,找到中间位置上的数值,经排序后中位数为73.5。
最大值
最大值一般就是指一组数据中最大的值。这里为81.0。由于只有15个数据,所以结论比较直观,如果分析的数据过多一般可能需要借助数据分析工具进行查看更方便。
最小值
最小值一般就是指一组数据中最大的值。这里为66.0。由于只有15个数据,所以结论比较直观,如果分析的数据过多一般可能需要借助数据分析工具进行查看更方便。
四分位差
四分位差也称四分间距(IQR),一般是指上四分位数和下四分位数之差,四分位数一般反映了中间50%的数据的离散程度,数值越小说明中间数据越集中,反之,数值越大说明数据越分散,四分位差在一定程度上说明了中位数对一组数据的代表程度,一般适用于定量变量。四分位数是将一组数据由小到大排序后,用3个点将全部数据分为4等份,与这3个点位置上相对应的数值称为四分位数,分别记为Q1、Q2、Q3。分别为71和76.5,所以四分位差为5.5。
方差
方差是各变量值与平均数离差平方的平均数,方差能够很好的反映数据的离散程度,也是应用最广的离散测度值。其计算公式如下:
所以案例的方差为:
标准差
标准差就是就是方差的平方根值,所以案例中的标准差为4.012。
变异系数
变异系数也叫离散系数,它是一组数据的标准差与其相应的平均数之比,变异系数是测度数据离散程度的统计量,主要用于比较不同样本数据的离散程度,变异系数大,说明离散程度大,变异系数小,说明数据的离散程度也小。其计算公式如下:

所以案例的变异系数为:
虽然集中趋势和离散程度是数据分布的两个重要特征,但要全面了解数据分布的特点,还需要知道数据分布的形状是否对称,偏斜程度等等,其中偏度和峰度就是对数据分布形状的测度。
偏度
偏度也称偏态它是对数据分布对称性的测度,偏度可以描述数据的分布情况,具体如下:
偏态系数的计算方法有很多,通常采用的公式如下:
案例的偏度如下:
峰度
峰度是对数据分布平峰或者尖峰程度的测度,测度峰态的统计量是峰态系数,当峰度大于0则为尖峰分布,当峰度小于0此时为扁平分布,其通常采用的计算公式如下:
案例的峰度如下:
最后峰度为-0.089。
- 相关系数
- Pearson相关系数
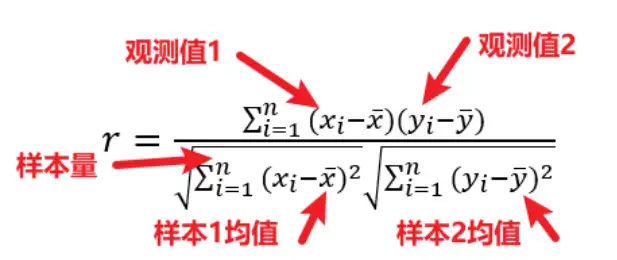
- Spearman相关系数
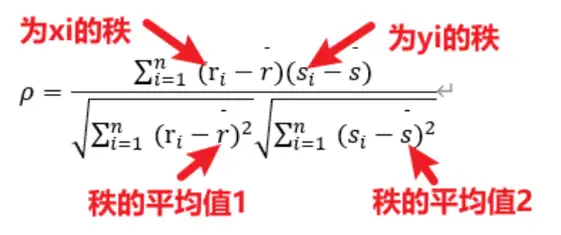
- 假设检验
- T值
t统计量计算
- 方差齐时:
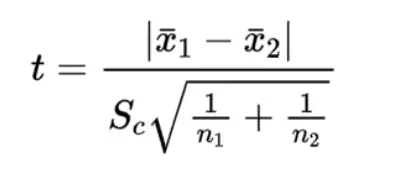
其中n1、n2分别为两个样本的观测数目,分母是两个样本之差的标准误,其中的Sc是合并方差,其计算为:
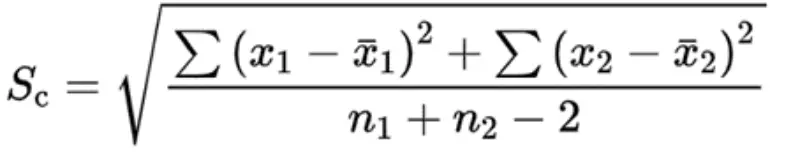
(2)方差不齐时:
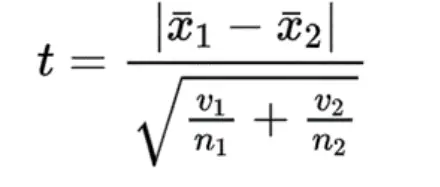
V1、V2分别为样本的方差。
- F值(自由度、均方)
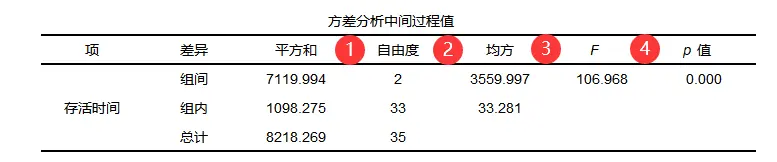
01自由度
组间自由度df1=组别数-1=3-1=2;组内自由度df2=样本量-组别数量=12*2-3=33;
02均方
组间均方=组间平方和/组间自由度df1=7119.994/2=3559.997;
组内均方=组内平方和/组内自由度df2=1098.275/33=33.281;
03 F值
F值=组间均方/组内均方=3559.997/33.281=106.968;
04 p值
F值为统计量,p值结合F值和自由度计算得到。
- 卡方值
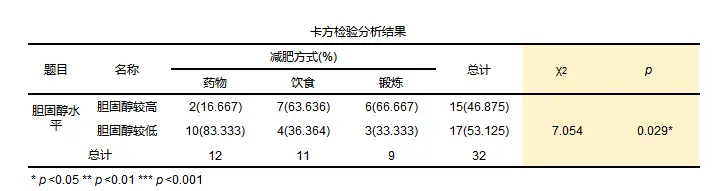
其中A代表某个类别的观察频数,E代表基于H0计算出的期望频数,Ai为i水平的观察频数,Ei为i水平的期望频数,n为总频数,pi为i水平的期望频率。当n比较大时,χ2统计量近似服从k-1个自由度的卡方分布。
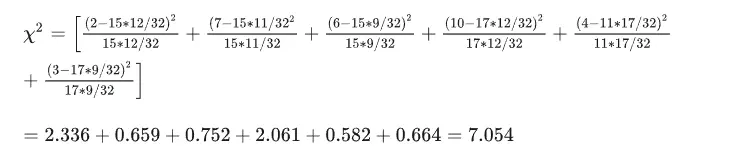
- 回归分析
R方、调整后的R方
R方计算的解读
2= / =∑( ^ − ¯)2∑( − ¯)2=1−∑( − ^ )2∑( − ¯)2
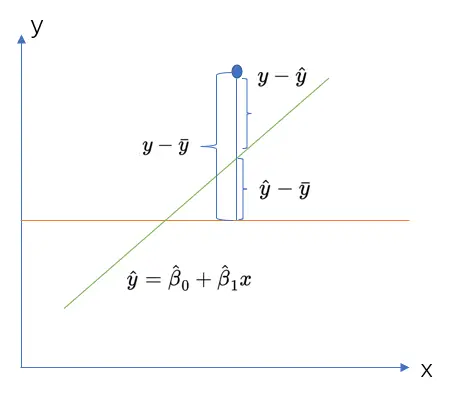

调整后的R方:
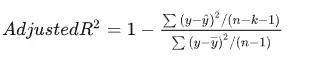
VIF值:
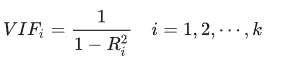

















 7230
7230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









