









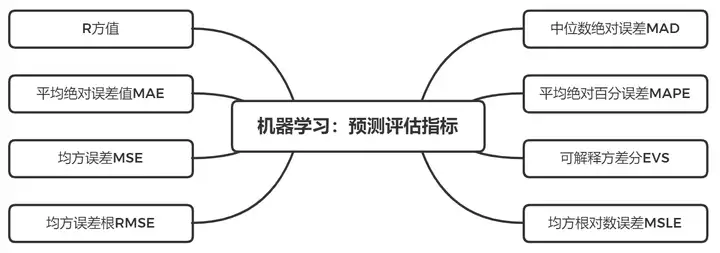
机器学习:8类预测评估指标
R方值、平均值绝对误差值MAE、均方误差MSE、均方误差根EMSE、中位数绝对误差MAD、平均绝对百分误差MAPE、可解释方差分EVS、均方根对数误差MLSE。
一、R方值
1、说明:
R方值,也称为确定系数或拟合优度,是用于量化模型预测与真实数据之间拟合程度的指标。其值范围在0到1之间。
- R方值接近0:表示模型几乎没有解释数据中的变化,即模型的预测与真实值之间几乎没有关系。
- R方值接近1:表示模型解释了数据中的大部分变化,即模型的预测与真实值非常接近。
2、计算:
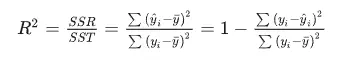
SST:是真实值与其均值之间差异的平方和,反映了数据中的总变化。
SSR:回归平方和,即回归模型可以解释的方差。它表示由自变量变化引起的因变量变化的部分,是可以用回归直线来解释的变差部分。
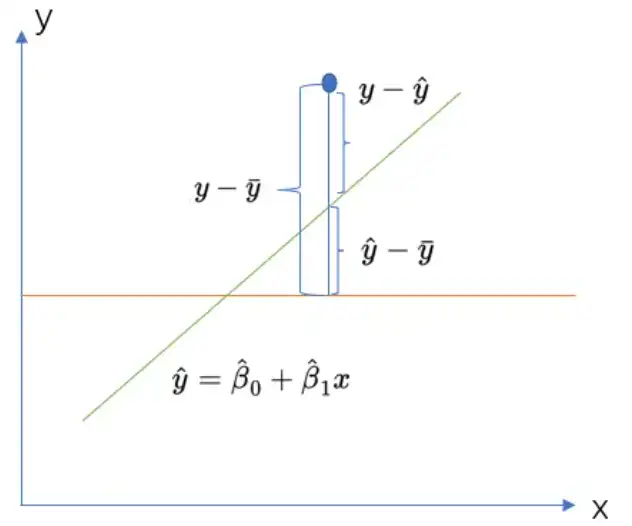
3、解读说明:
- R方值过高:
通常表示模型拟合得很好,能够解释数据中的大部分变化。但需要注意,高R方值并不一定意味着模型具有好的预测能力,特别是在存在过拟合的情况下。 - R方值过低:
可能表示模型拟合得不好,或者数据中的变化主要由随机噪声引起,而非模型能够解释的系统性规律。 - R方值的比较:
在比较不同模型的R方值时,需要注意数据的规模和特征。对于具有不同规模或特征的数据集,即使R方值相同,也可能表示模型具有不同的拟合能力。
二、平均绝对误差值MAE
1、说明:
预测值与实际值之差的绝对值的平均数,取值越小,模型准确度越高。
2、计算:
MAE=1𝑛∑𝑖=1𝑛|𝑦𝑖−𝑦^𝑖|
其中,n为样本个数,为真实值,为预测值。
3、解读说明:
- 直观易懂:
MAE是一个直观且易于理解的指标,因为它以与原始数据相同的单位来衡量误差。 - 对异常值不敏感:
由于MAE取的是绝对误差的平均值,因此它对数据中的异常值或极端值不敏感。这意味着即使数据中存在一些异常值,MAE值也不会受到太大的影响。 - 评估预测精度:
MAE直接反映了模型的预测精度,因为它衡量的是预测值与真实值之间的平均绝对差异。较小的MAE值表示模型具有更高的预测准确性。 - 不受数据集规模影响:
MAE是一个相对稳定的指标,它不受数据集规模的影响。因此,无论是在小数据集还是大数据集上,MAE都可以提供一致的评估结果。
三、均值误差MSE
1、说明:
预测值与实际值之差的平方的平均值。取值越小,模型准确度越高。
2、计算:
MSE=1𝑛∑𝑖=1𝑛(𝑦𝑖−𝑦^𝑖)2
其中,n为样本个数,为真实值,为预测值。
3、解读说明: - 敏感性:
MSE对预测误差的大小非常敏感,即使是较小的误差也会对MSE值产生较大的影响。因此,它能够有效反映模型的预测能力。
- 计算简单:
MSE的计算公式相对简单,易于理解和实现。
- 对离群值敏感:
MSE的一个主要缺点是它对数据中的离群值非常敏感。如果数据集中存在离群值,MSE的值可能会受到显著影响,导致对模型性能的评估不准确。
四、误差根RMSE
1、说明:
为 MSE 的平方根,取值越小,模型准确度越高。
2、计算:
RMSE=1𝑛∑𝑖=1𝑛(𝑦𝑖−𝑦^𝑖)2
其中,n为样本个数,为真实值,为预测值。
3、解释说明:
- 敏感性:
RMSE对预测误差的大小非常敏感,即使是较小的误差也会对RMSE值产生较大的影响。这有助于发现模型中的小偏差。
- 量纲一致性:
RMSE的单位与原始数据的单位相同,因此具有量纲一致性,便于理解和解释。
- 对离群值敏感:
由于RMSE计算中涉及到平方操作,因此它对数据中的离群值非常敏感。如果数据集中存在离群值,RMSE的值可能会受到显著影响。 - 数值范围:
RMSE的取值范围是0到正无穷大。数值越小,表示模型的预测精度越高
五、数绝对误差MAD
说明
有异常值也可以使用。

[1]李文颖.基于深度学习的金融市场波动率预测研究及应用[D].东华大学,2023.DOI:10.27012/d.cnki.gdhuu.2023.000710.
六、平均绝对百分误差MAPE
1、说明:
预测值与实际值之差的绝对值与实际值之比的平均数,以百分比表示。取值越小,模型准确度越高。
2、判断标准:
MAPE取值范围是0到正无穷大。
在这个范围内,MAPE值越小,表示预测模型越准确,预测值与实际值之间的误差越小。
MAPE值小于10%:通常认为这是一个比较好的预测模型,预测精度较高。
MAPE值在10%-20%之间:预测精度仍然可以接受,但可能需要进行一些优化以提高准确性。
MAPE值大于20%:这表示预测效果不太理想,可能需要重新评估模型或寻找更好的预测方法。
七、可解释方差得分EVS
1、说明:
可解释方差得分(EVS)是衡量回归模型预测结果与实际结果之间方差相似度的一个指标。它反映了模型捕捉到的数据变异性的程度,即模型预测值的变化与实际值变化之间的相似度。
2、计算:
EVS = 1 - (ESS / TSS)
ESS:回归平方和、TSS总体平方和。
3、判断标准:
可释方差得分的取值范围为[0,1],当EVS为1时,表示模型完美预测了数据;当EVS为0时,表示模型无法解释数据方差。
在实际应用中,EVS通常用于比较不同模型的表现,取值越接近1,表示模型解释的数据方差越多,表现越好。
八、均方根对数误差MSLE
1、说明和计算:
计算的是预测值与实际值之间的对数差的平方的平均值,再取平方根。
2、判断标准:
- 敏感性:
MSLE对于预测值与实际值之间的比例误差非常敏感。当预测值与实际值相差很大时,即使它们的绝对值差异可能不大,MSLE也会给出一个较大的值,从而惩罚模型。 - 对数据的分布敏感:
由于MSLE涉及到对数运算,因此它对数据的分布非常敏感。如果数据中存在大量的极端值或离群点,那么MSLE可能会给出不稳定的结果。

















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









