









一、论文
Deformable ConvNets v2: More Deformable, Better Results
https://arxiv.org/abs/1811.11168
The code for DCNv2 will be released.
二、论文笔记
1、背景
a)、基于第一版的问题, 使用可变形卷积发现网络确实学会了适应物体的形状然后去关注不同形状物所覆盖的区域,但是关注的物体区域不是很准确,一般会超出物体区域的一部分。
b)、错误的候选框可能会利用到框外的特征,比如一个框可能因为利用了一些外部包含物体的特征区域,然后被给出,但是被给出的这个框是没有完整覆盖物体的,属于错误的框,可变性卷积也存在这个问题(可能的原因是因为分类分支和回归分支,共享了一些卷积层,而对于分类任务,是需要更大的感受野,所以可能会利用到框外的特征,所以会有些提议是让分类分支和回归分支共享更少的层,或者综合考虑Faster R-CNN and R-CNN的分类结果,来获得更好的回归结果,因为R-CNN完全是基于剪切的出来的物体框训练出来的)
2、创新点
前两个创新点也是和“影响网络最终预测结果的数据只是某一区域的像素值,这里体现两个点,一个数位置,一个是激活值(像素)”的观点一致的。
a)、堆叠更多的可变性卷积,给更多的卷积层配备可变性卷积(在conv3, conv4, and conv5中的所有3 x 3卷积中都放入可变形卷积,共12层)(v1中deformable convolution也只在res5的三层3×3卷积层做替换) 在v1论文中使用PASCAL VOC数据集,所以难以观察到这部分提升。
b)、可变形卷积模块中的调制机制,其中不仅需要学习偏移,而且偏移还要被学习的特征振幅调制。该调节机制是在feature map的每一个位置都要学习一个系数(0-1)所以该系数有使得原来的特征值缩小的功能,最极端的例子是某个位置在物体范围外,对物体检测无帮助,则可以将它置0。这样一种机制算是在可变性卷积自动选择卷积区域后的卷积结果的基础上在做一次选择。
分别是
deformable convolution
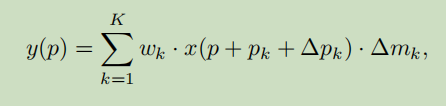
deformable RoIpooling
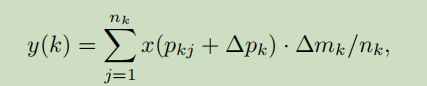
c)、定义了一个a feature mimic loss,去聚焦物体特征区域,仅仅对正样本框使用,因为考虑到负样本框可能需要更多的上下文信息
添加了一个类似R-CNN 的网络分支,这个分支的输入就是根据RPN结果在原图上截取出来的物体区域,然后进行训练,有正常的自己的分类函数((C+1)-way),然后把这个分支输出的特征和Faster R-CNN输出的特征做一个cos距离,迫使该距离为1,也就是迫使输出的特征相同,想当于是加了一个聚焦框内特征运算的监督,两个分支的参数共享,只在训练的时候用R-CNN分支,推断时只用Faster RCNN

更多详细内容请参考:https://blog.csdn.net/u014380165/article/details/88072737















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









