







集成方法在函数模型上等价于一个多层神经网络,两种常见的集成方法为Adaboost模型和RandomTrees模型。其中随机森林可被视为前馈神经网络,而Adaboost模型则等价于一个反馈型多层神经网络。
一.引入
对于Adaboost,可以说是久闻大名,据说在Deep Learning出来之前,SVM和Adaboost是效果最好的 两个算法,而Adaboost是提升树(boosting tree),所谓“ 提升树 ” 就是把“弱学习算法”提升(boost)为“强学习算法”(语自《统计学习方法》),而其中最具代表性的也就是Adaboost了,貌似Adaboost的结构还和Neural Network有几分神似,我倒没有深究过,不知道是不是有什么干货。
二.过程
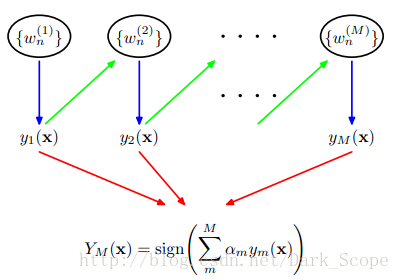
这就是Adaboost的结构,最后的分类器YM是由数个弱分类器(weak classifier)组合而成的,相当于最后m个弱分类器来投票决定分类,而且每个弱分类器的“话语权”α不一样。
这里阐述下算法的具体过程:
1.初始化所有训练样例的权重为1 / N,其中N是样例数
2.for m=1,……M:
a).训练弱分类器ym(),使其最小化权重误差函数(weighted error function):
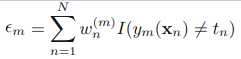
b)接下来计算该弱分类器的话语权α:
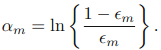
c)更新权重:
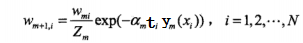
其中Zm:
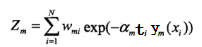
是规范化因子,使所有w的和为1。(这里公式稍微有点乱)
3.得到最后的分类器:
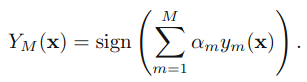
三.原理
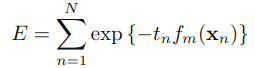
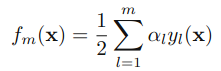
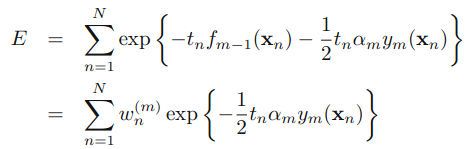
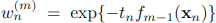 ,可以被看做一个常量,因为它里面没有αm和ym:
,可以被看做一个常量,因为它里面没有αm和ym:
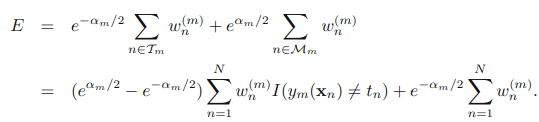
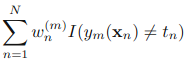
四.实现
C++:http://blog.csdn.net/u012319493/article/details/53103192python:
集成算法 实例:
http://blog.csdn.net/mlljava1111/article/details/50765517
adaboost python 实例:
http://blog.csdn.net/u014114990/article/details/51178899
https://github.com/justdark/dml/tree/master/dml















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









