







自编码器介绍
自编码器可以用自身的高阶特征编码自己,实际上是一种神经网络,输入输出一致,借助了稀疏编码的思想,用稀疏的一些高阶特征重新组合来重构自己。
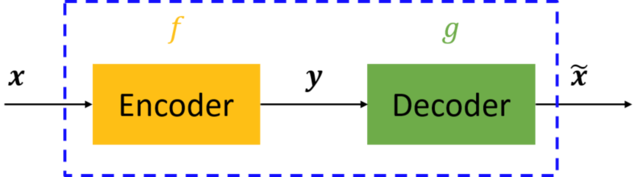
图中,虚线蓝色框内就是一个自编码器的基本模型,它由编码器(Encoder)和解码器(Decoder)两部分组成,本质上两者都是对输入信号做某种变换。编码器将输入信号x变换成编码信号y,而解码器是将编码信号y转换成输出信号,即y=f(x)=g(y)=g(f(x))。
而整个自编码器的目的就是,让最终的输出信号尽可能的复现输入x。但是,这里问题就来了——如果f和g都是恒等映射,那不有就恒等式=x了?确实如此,但这样的变化没有任何意义。因此,我们需要对中间的信号y(也叫做“编码”)做一定的约束,这样系统往往能学出很有趣的编码变换f和编码y。而这个约束,一般使编码y的数据复杂程度远小于x,并且能对原始x的数据信号做接近全部的保留。
这里强调一点,对于自编码器,我们往往并不关心输出的是什么(反正只是复现输入),我们真正关心的是中间层的编码,或者说是从输入到编码的映射f。可以这么想,在我们强迫编码y和输入x不同的情况下,系统还能够去复原原始信号x,那么说明编码y已经承载了原始数据的所有信息,但以一种不同的形式!这就是特征提取啊,而且是自动学出来的!其实,自动学习原始数据的特征表达也是神经网络和深度学习的核心目的之一。
2.自编码器加入限制的问题
如果限制中间隐含层节点的数量,可视作一个降维的过程,则不可能复制所有的节点出来,只能学习数据中最重要的特征复原,将可能不太相关的内容去除掉。如果再给权重加上一个L1的正则,则可以根据惩罚系数控制隐含节点的稀疏程度,惩罚系数越大,学到的特征数量越少。
(关于L1正则化的补充)
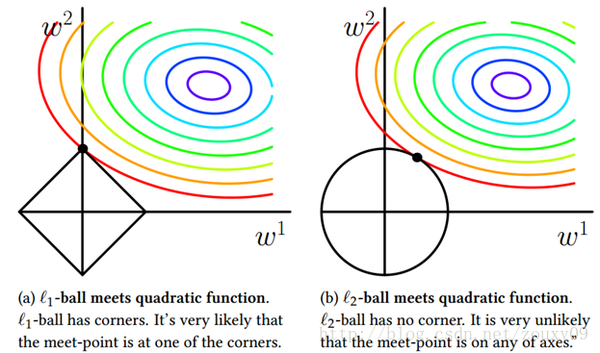
(从上面这张图可以看出,损失函数的主体是一个凸函数,它的等高线均匀地向外扩散。因此正方形的L1正则更容达到参数的稀疏性,而圆形的L2正则则不太容易达到这个效果。所以多年以来,大家一直在心中默默记住:L1可以达到参数稀疏化的效果。)
如果给数据加入噪声的限制,那么就是去噪自编码器(Denoising AutoEncoder),将从噪声中学习到数据的特征。同样也不能完全复制节点,完全复制并不能去除添加的噪声,无法复原数据,所以只能隵数据频繁出现的模式,将无规律的噪声略去才能复原。
3.去噪自编码器最长使用的噪声是加性高斯噪声,也可使用Masking Noise,即有随机遮挡的噪声(和后面提到的dropout类似的方法)。Hinton的思路是先用自编码器的方法进行无监督的预训练,提取特征并且初始化权重,然后用标注的信息进行监督式的训练。
4.下面开始用tensorflow实现最具代表性的去噪自编码器
#首先导入常用的库
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#自编码器中会用到一种xavier initialization的初始化方法,它会根据某一层网络的输入,输出节点调整最合适的分布。见附录1
def xavier_init(fan_in,fan_out,constant=1):
low = -constant * np.sqrt(6.0 / (fan_in + fan_out))
high = constant * np.sqrt(6.0 / (fan_in + fan_out))
return tf.random_uniform((fan_in,fan_out),minval=low,maxval=high,dtype=tf.float32)
#tf.random_uniform见附录2
class AdditiveGaussianNoiseAutoencoder(object):
def __init__(self, n_input, n_hidden, transfer_function = tf.nn.softplus,
optimizer = tf.train.AdamOptimizer(),scale = 0.1):
self.n_input=n_input #输入变量数
self.n_hidden=n_hidden #隐含层节点数
self.transfer=transfer_function #隐含层激活函数,默认是softplus,见附录4
self.scale=tf.placeholder(tf.float32) #高斯噪声系数,默认为0.1
self.training_scale=scale
network_weights=self._initialize_weights() #后面会定义该函数,函数的下划线问题件附录3
self.weights=network_weights
#接下来开始定义网络结构
self.x=tf.placeholder(tf.float32,[None,self.n_input]) #x为 任意长度xn_input的矩阵
self.hidden=self.transfer(tf.add(tf.matmul(self.x+scale*tf.random_normal((n_input,)),
self.weights['w1']),self.weights['b1']))
#self.x+scale*...是为x加入噪声,用self.transfer进行结果的激活处理
self.reconstruction = tf.add(tf.matmul(self.hidden, self.weights['w2']),
self.weights['b2'])
#经过隐含层后将在输出层进行数据复原和重建操作,此处不需要激活函数。
#以上出现的self.weights[]各类将会在后面给出具体定义。附录
1:
Xavier初始化的实现就是下面的均匀分布:(其中j为输入节点,j+1为输出节点。)
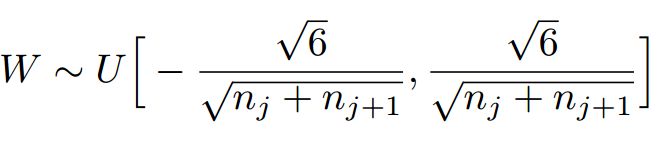
——————————————————————————————————————
2:
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
tf.random_uniform(shape,minval=0,maxval=None,dtype=tf.float32,seed=None,name=None)
这几个都是用于生成随机数tensor的。尺寸是shape
random_normal: 正太分布随机数,均值mean,标准差stddev
truncated_normal:截断正态分布随机数,均值mean,标准差stddev,不过只保留[mean-2*stddev,mean+2*stddev]范围内的随机数
random_uniform:均匀分布随机数,范围为[minval,maxval]
tf.random_normal(shape[1,5],mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
3:
变量:
前带_的变量: 标明是一个私有变量, 只用于标明, 外部类还是可以访问到这个变量
前带两个_ ,后带两个_ 的变量: 标明是内置变量,
大写加下划线的变量: 标明是 不会发生改变的全局变量
函数:
前带_的变量: 标明是一个私有函数, 只用于标明,
前带两个_ ,后带两个_ 的函数: 标明是特殊函数
4:
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够
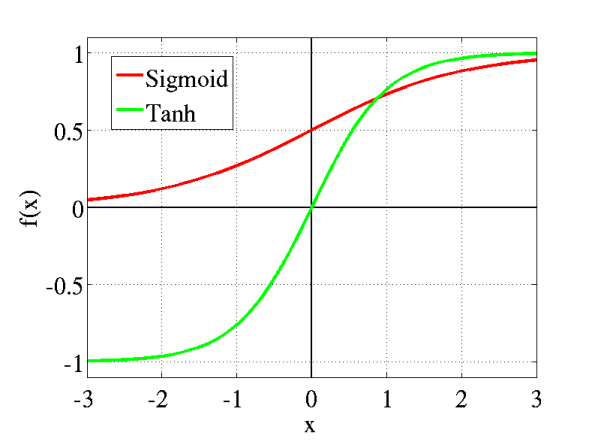
传统神经网络中最常用的两个激活函数,Sigmoid系(Logistic-Sigmoid、Tanh-Sigmoid)被视为神经网络的核心所在。
从数学上来看,非线性的Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,在信号的特征空间映射上,有很好的效果。
从神经科学上来看,中央区酷似神经元的兴奋态,两侧区酷似神经元的抑制态,因而在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。
无论是哪种解释,看起来都比早期的线性激活函数(y=x),阶跃激活函数(-1/1,0/1)高明了不少。
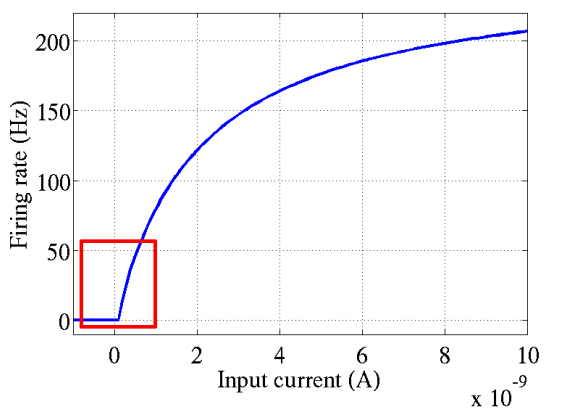
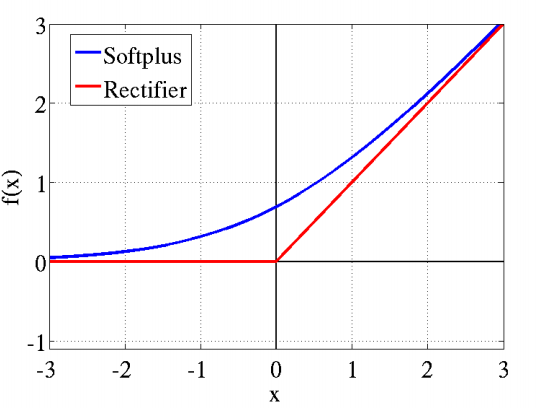
这个模型对比Sigmoid系主要变化有三点:①单侧抑制 ②相对宽阔的兴奋边界 ③稀疏激活性(重点,可以看到红框里前端状态完全没有激活)
同年,Charles Dugas等人在做正数回归预经元激活频率函数有神似的地方,这促成了新的激活函数的研究。测论文中偶然使用了Softplus函数,Softplus函数是Logistic-Sigmoid函数原函数。
Softplus(x)=log(1+ex)
按照论文的说法,一开始想要使用一个指数函数(天然正数)作为激活函数来回归,但是到后期梯度实在太大,难以训练,于是加了一个log来减缓上升趋势。
加了1是为了保证非负性。同年,Charles Dugas等人在NIPS会议论文中又调侃了一句,Softplus可以看作是强制非负校正函数
max(0,x)平滑版本。
偶然的是,同是2001年,ML领域的Softplus/Rectifier激活函数与神经科学领域的提出脑神经元激活频率函数有神似的地方,这促成了新的激活函数的研究。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









