







 本文探讨了图像复原任务中L1和L2损失函数的局限性,介绍了SSIM损失函数作为替代方案,详细解析了SSIM的计算原理,包括亮度、对比度和结构相似度的评估,并提供了TensorFlow中SSIMloss的实现方法。
本文探讨了图像复原任务中L1和L2损失函数的局限性,介绍了SSIM损失函数作为替代方案,详细解析了SSIM的计算原理,包括亮度、对比度和结构相似度的评估,并提供了TensorFlow中SSIMloss的实现方法。
基于深度学习的图像算法的损失函数有很多类型,常见的比方 L1 loss,L2 loss 等。但是对于图像复原工作而言 L2 loss 对于图像的细节结构不易恢复(或者说能恢复,但是相对而言训练的时间比较久),且 L2 对于敏感点的惩罚比较大。
在实际训练的某个任务中,我发现 L1 loss 收敛后的 loss (0.02)远远大于 L2 loss 收敛后的 loss(0.0004),而且两个对于一些细节的复原都不够,且不足以直观地表达人的认知感受。
那么有没有其他的 loss 呢?
答案是肯定的。
1 SSIM loss 是啥
2004年的一篇文献 Image Quality Assessment: From Error Visibility to Structural Similarity 提出了一种取代 MSE、用于重建图像和原图相似性的 metric,即 SSIM (Struction Similiarity Metric)指标,从一对图像的三个维度评价图像的相似度。三个维度包含亮度(luminance)、对比度(contrast)和结构(structure),用下式表示:
![]()
亮度相似度计算如下:
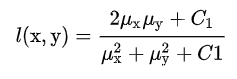
其中
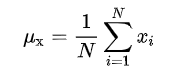 代表图像均值;
代表图像均值;
![]() 为除零保护(K1一般取0.01,L是灰度的动态范围,比方图像是uint8,则L=255);
为除零保护(K1一般取0.01,L是灰度的动态范围,比方图像是uint8,则L=255);
对比度相似度计算如下:
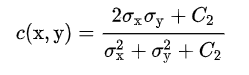
其中
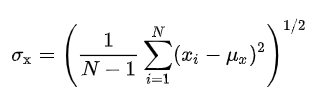 代表方差;
代表方差;
![]() (K2一般取0.03);
(K2一般取0.03);
结构相似度计算如下:
其中
 代表协方差;
代表协方差;
![]() ;
;
最后推断得到 SSIM 的公式:
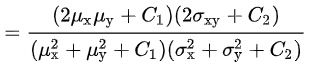
其中
![]() ;
;
![]() ;
;
2 tensorflow 实现 SSIM loss
tensorflow 中的 fg.image.ssim 函数:
tf.image.ssim(
img1,
img2,
max_val
)
参数:
- img1:第一批图像.
- img2:第二批图像.
- max_val:图像的动态范围(即最大允许值与最小允许值之间的差值,例如图像数据为 uint8,则值为255).
返回:
一个包含批处理中每个图像的SSIM值的张量.返回的SSIM值在范围(-1,1)中,当像素值非负时返回形状为:broadcast(img1.shape [: - 3],img2.shape [: - 3])的张量。
图像的尺寸要求至少为11 * 11。
对于归一化后的图像数据,一般用 tensorflow 计算 loss 的时候可以写成这样:
loss = 1 - tf.reduce_mean(tf.image.ssim(gt, y_pre, max_val=1.0))gt 是标签图像,y_pre 是预测图像。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









