







简单的调参法:网格搜索、简单随机抽样
贝叶斯优化:假设有一系列观察样本,并且数据是一条接一条地投入模型进行训练(在线学习)。这样训练后的模型将显著地服从某个函数,而该未知函数也将完全取决于它所学到的数据。因此,我们的任务就是找到一组能最大化学习效果的超参数,即求最大化目标函数值的参数。
算法流程:贝叶斯优化根据先验分布,假设采集函数(Acquisition function)而学习到目标函数的形状。在每一次使用新的采样点来测试目标函数时,它使用该信息来更新目标函数的先验分布。然后,算法测试由后验分布给出的最值可能点。
目标函数的分布建模:高斯过程(Gaussian Process),生成了多维高斯分布。
逼近目标函数的高斯过程:目标函数(虚线)未知,该目标函数是模型性能和超参数之间的实际关系。

Question:对于贝叶斯优化,一旦它找到了局部最优解,那么它就会在这个区域不断采样,所以贝叶斯优化很容易陷入局部最优解。
解决:开发(exploitation)和探索(exploration)之间的权衡
采集函数:定义一个采集函数(Acquisition function),反复计算采集函数的极大值而寻找下一个采样点。
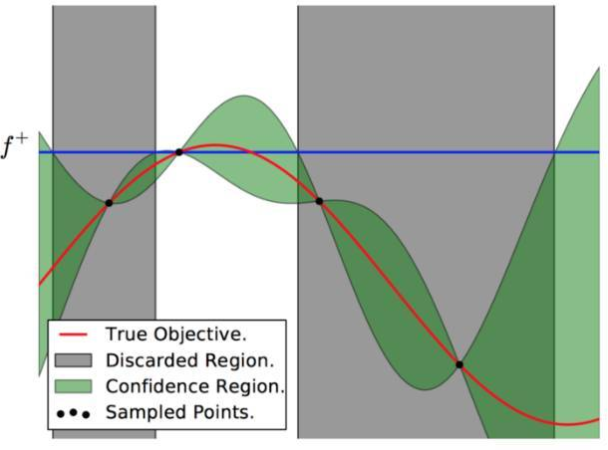
贝叶斯优化过程:红色的曲线为实际的目标函数,希望使用高斯过程逼近该目标函数。采样点(图有 4 个抽样点),绿色的区域为置信域,即目标曲线最有可能处于的区域。我们确定了第二个点(f+)为最大的样本观察值,所以下一个最大点应该要比它大或至少与之相等。因此,绘制出一条蓝线,并且下一个最大点应该位于这一条蓝线之上。下一个采样在交叉点 f+和置信域之间,我们能假定在 f+点以下的样本是可以丢弃的,就缩小了观察区域,迭代这一过程,直到搜索到最优解。
论文:Taking the Human Out of the Loop: A Review of Bayesian Optimization















 4422
4422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









