







梯度下降:
- 梯度下降法是一种优化算法,思想是沿着目标函数梯度的方向更新参数值以希望达到目标函数最小(或最大)。梯度下降法是深度学习网络最常用的优化算法。

反向传播法:
-
由于深度学习网络按层深入,层层嵌套的特点,对深度网络目标函数计算梯度的时候,需要用反向传播的方式由深到浅倒着计算以及更新参数。所以反向传播法是梯度下降法在深度网络上的具体实现方式。

-
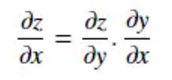
一句话总结就是反向传播法采用链式法则进行偏导作用在各个层,并采用梯度下降的优化算法进行每层权重的更新。
下面就通过公式推导和例子来进行分析神经网络的权重更新过程:
一、一个简单 例子
给i一个简单的传播函数:
y = wx + b
误差error:
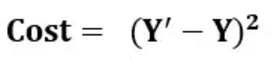
代入则得到Cost = (wx+b - Y)^2
Cost = (Error)^2 Error = wx+b-Y
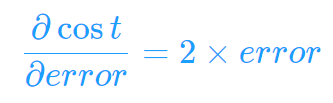
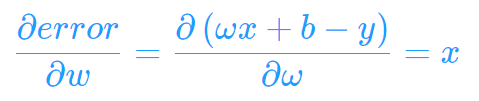
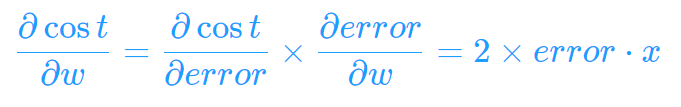
通过以上就可求出偏导:
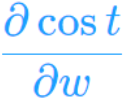
二、升华一下

如图所示:前向传播就不多说了,直接累乘加激活即可完成每层前传值。
现在说下后向传播:
- 构建误差(损失):总误差(square error)
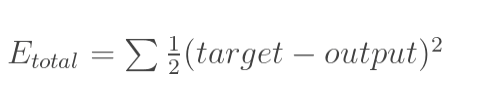
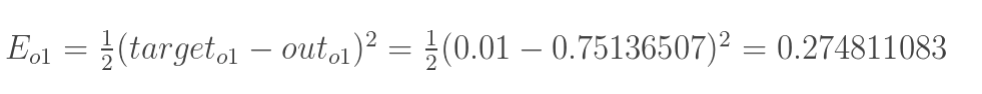

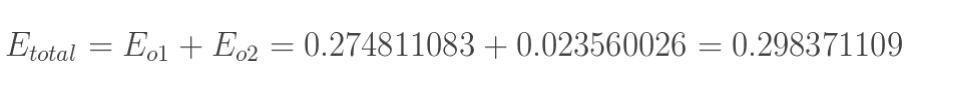
W5权值更新

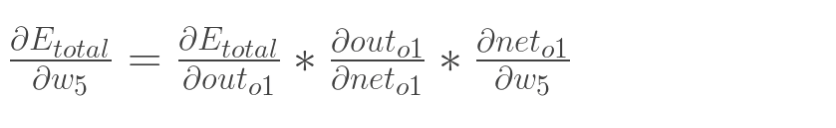

同理

W1权值更新
W1涉及多个输出反馈来进行更新



为了进行对每层中每个w进行更新,简化公式直接和输入计算出梯度:

三、数学推导
数学推导见https://blog.csdn.net/xierhacker/article/details/53431207
参考文献
- https://segmentfault.com/a/1190000019862084
- https://blog.csdn.net/xierhacker/article/details/53431207
- https://www.cnblogs.com/softzrp/p/6718909.html
- https://www.cnblogs.com/codehome/p/9718611.html














 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









