










 博客指出组合多来源图像制作的数据集存在重复图像,人工筛选耗时易错。介绍了图像哈希原理,可用于近重复检测等。分析不使用MD5、sha - 1的原因,提出使用差异哈希算法,还说明了其好处及比较方法,如用汉明距离比较。
博客指出组合多来源图像制作的数据集存在重复图像,人工筛选耗时易错。介绍了图像哈希原理,可用于近重复检测等。分析不使用MD5、sha - 1的原因,提出使用差异哈希算法,还说明了其好处及比较方法,如用汉明距离比较。
我们使用的数据集可能是通过组合来自多个来源的图像而制作的。这样的数据集中将有很多重复的图像,如果依靠人工手动筛选将会花费很多时间并且容易出错- 因此,我需要一种方法来检测 并从数据集中删除这些重复的图像。
1.数据集有重复图像会造成的问题
1.将偏见引入到数据集中,为神经网络提供了额外的机会来学习特定于重复项的模式。
2.这会损害模型泛化性
2.运用的原理
图像哈希(也称感知哈希)是基于图像的可视化内容构造哈希值的过程。我们将图像哈希用于CBIR(Content-based image retrieval),近重复检测和反向图像搜索引擎。
图像哈希的过程:
1检查图像内容
2.构造一个哈希值,该哈希值根据图像内容唯一地标识输入图像
看起来相似的图像也应具有相似的哈希值(其中相似通常定义为哈希值之间的汉明距离)
通过使用图像哈希算法,我们可以在恒定的时间内找到最接近的图像,或者在使用适当的数据结构是最差的时间为O(logn).
3.为什么不使用MD5,sha-1等
这个问题在于:哈希算法的本质,更改文件中的单位将导致不容的哈希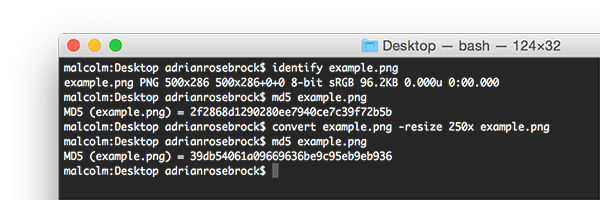
图1:在此示例中,我将输入一个图像并计算md5哈希值。然后,我将图像的大小调整为250像素而不是500像素的宽度,然后再次计算md5哈希值。即使图像的内容没有改变,哈希也改变了。
这就意味着,如果我们仅更改输入图像中单个像素的颜色,我们将得到不同的校验和,而实际上我们无法分辨出单个像素是否发生了变化-对人眼来说,两张图片是相同的。
在图像哈希中,我们实际上是希望相似的图像也具有相似的哈希值。因此如果图像相似,我们就会寻求一些哈希冲突。
我们将为该文章实现的图像哈希算法称为差异哈希或简称为dhash。
差异哈希是通过计算相邻像素之间的差异(即相对梯度)来工作的。
差异哈希的好处:
1.如果输入图像的宽高比发生变化,则图像哈希不会更改。
2.调整亮度或对比度也不会更改我们的哈希值,或者仅对其稍作更改,一确保哈希值紧密地靠在一起
3.差异哈希非常快
比较差异哈希
通常使用汉明距离来比较hash。汉明距离测量的是两个不同的哈希中的位数。
汉明距离为0的两个哈希值意味着两个哈希值是相同的(因为没有不同位),并且两个图像是相同的或者在感知上也相似。
Dr. Neal Krawetz of HackerFactor表明哈希的差别大于10位是最有可能不同的,而在1和10之间的汉明距离是潜在相同的图像的变形。实际上,您可能需要针对自己的应用程序和相应的数据集调整这些阈值。
# -*- coding: utf-8 -*-
"""
@author : xxx
@version :
@time : 2020/11/18 10:00
@function:
"""
from imutils import paths
import numpy as np
import argparse
import cv2
import os
def dhash(image, hash_size=8):
# 转灰度,并调整大小
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 丢弃任何颜色信息@1
resized = cv2.resize(gray, (hash_size + 1, hash_size)) # 忽略宽高比@2
# 计算像素之间的水平梯度
diff = resized[:, 1:] > resized[:, :-1] # 计算差异
# 将差异图片转换为哈希并返回
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v]) # 建立hash
if __name__ == '__main__':
parse = argparse.ArgumentParser()
parse.add_argument('-d', '--dataset', required=True, help='path to input dataset') # 数据集路径
parse.add_argument('-r', '--remove', type=int, default=-1,
help='whether or not duplicates should be removed (i.e., dry run)') # 是删除还是只查看重复项
args = vars(parse.parse_args())
print('{INFO} computing image hashes ..')
image_paths = list(paths.list_images(args['dataset']))
# print('image_path', image_paths)
hashes = {}
for image_path in image_paths:
image = cv2.imread(image_path)
h = dhash(image) # 计算图像的hash值
# 抓取具有该哈希值的所有图像路径,添加当前图像路径,并将列表存储回哈希字典中
p = hashes.get(h, [])
p.append(image_path)
hashes[h] = p
# 遍历图像哈希
for (h, hashed_paths) in hashes.items():
# 检查是否有多个图像具有相同的哈希值
if len(hashed_paths) > 1:
# 检查这是否是空转
if args['remove'] <= 0:
# 初始化蒙太奇用来存储具有相同图像的所有图像
montage = None
# 遍历具有相同hash值的所有图像路径
img_name = ''
for p in hashed_paths:
# 加载输入图像并将其调整为固定宽度
image = cv2.imread(p)
image = cv2.resize(image, (900, 900))
# 如果为None就初始化
if montage is None:
montage = image
# 否则就水平堆叠
else:
montage = np.hstack([montage, image])
img_name += p + '_'
# 显示蒙太奇的哈希
print('[INFO] hash: {}'.format(h))
cv2.imshow('{}'.format(img_name), montage)
cv2.waitKey(0)
else: # 删除重复的图像
for p in hashed_paths[1:]:
# 循环遍历具有相同散列的所有图像路径*列表中的第一张图片除外(因为我们要保留一幅)*
os.remove(p)
注释:
@1-丢弃颜色信息:
a.只需要检查一个通道,因此可以更快的哈希图像。
b.匹配相同但色彩空间稍有更改的图像
@2-忽略宽高比:
a.可以允许用于一定差异的图片具有一样的哈希值
参考:
2.https://www.pyimagesearch.com/2017/11/27/image-hashing-opencv-python/

















 1850
1850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









