







我们用Python来自己编写Logistics算法
首先,先将一些理论。Logistics算法用于实现线性可分的二分类问题
1. Sigmoid函数
fx=1/(1+exp(-x))
Sigmoid函数是常用的阈值函数之一,函数图像如下(是不是很像累积分布函数,值域都是0~1)
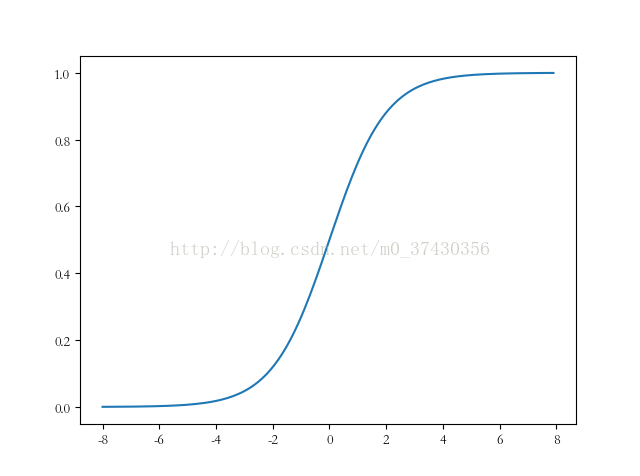
所以,我们选用Sigmoid函数来表示二分类的概率
Px=sig(Wx+b)
2. 损失函数
为了考察,模型与真实值之间拟合的好坏,我们需要设定损失函数来描述模型与真实值之间的差距。在Logistics模型中,我们选取最大似然函数的对数形式来作为模型的损失函数。
最大似然函数:

h为sigmoid函数,X为特征变量,y为分类标识(0,1)变量 ,m为变量个数
损失函数:

我们的优化目标为最小化损失函数,用到的是梯度下降算法。
3. 梯度下降算法

d为梯度下降方向,w为变量
我们顺着梯度方向更新权值W

直到目标函数达到最优值
4. 梯度下降算法来实现Logistics Regression模型
利用梯度下降算法对损失函数进行处理,求得梯度下降算法的最优值。

小x是样本X的特征分量,由上式得到的更新公式为
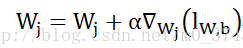
将上述的权重更新公式,代入模型进行训练,就得到了Logistics回归模型的权重值
5. 举个栗子
要分类的样本
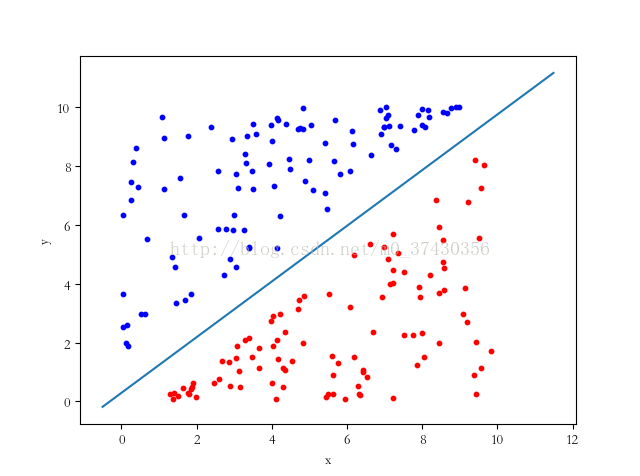
我们的目标就是要得到上图的那条分界线
# -*- coding: utf-8 -*-
#%% 导入包
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#%% 导入数据
data=pd.read_table('Logistics_Regression/lr.txt',sep='\t',names=['x','y','label'])
print(data.head())
x=data['x']
y=data['y']
label=data['label']
plt.scatter(data[label==0]['x'],data[label==0]['y'],s=10,c='b')
plt.scatter(data[label==1]['x'],data[label==1]['y'],s=10,c='r')
plt.xlabel('x')
plt.ylabel('y')
feature=data.iloc[:,0:2]
#%%
print(np.shape(np.shape(feature)[0]))
print(type(np.shape(feature)[0]))
w=lr_train_bgd(feature,label,1000,0.01)
w=pd.DataFrame(w)
print(w)
xx=np.arange(-0.5,11.5,0.01)
yy=-xx*(float(w.loc[0]/w.loc[1]))+float(w.loc[2]/(-w.loc[1]))
plt.plot(xx,yy)
#%%定义sig函数
def sig(x):
# input: x
# output: sigmond函数值
import numpy as np
return 1/(1+np.exp(-x))
#%% 训练模型
def lr_train_bgd(feature,label,maxCycle,alpha):
# 利用梯度下降算法训练LR模型
# input: feature(特征) label(标签) maxCycle(最大迭代次数) alpha(学习率)
# output: w(权重)
import numpy as np
feature['bias']=np.ones((np.shape(feature)[0],1))
n=np.shape(feature)[1]
w=np.mat(np.ones((n,1)))
i=0
while i<=maxCycle:#小于最大迭代次数
i+=1
h=sig(np.mat(feature)*w)
err=np.mat(label).T-h #误差
if i%100==0:
print ("\t-----------iter"+str(i)+\
",train error rate= "+str(error_rate(h,np.mat(label).T)))
w=w+alpha*np.mat(feature).T*err
return w
#%%error_rate函数的实现
def error_rate(h,label):
#计算当前的损失函数值
#input: h:预测值
# label:实际值
#output:err/m : 错误率
import numpy as np
m=np.shape(h)[0]
sum_err=0.0
for i in range(m):
if h[i,0]>0 and (1-h[i,0])>0:
sum_err-=(label[i,0]*np.log(h[i,0])+\
(1-label[i,0])*np.log(1-h[i,0]))
else:
sum_err-=0
return sum_err/m6. 结果

得到的权重为4.527177,-4.793982,1.394178















 2826
2826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









