







Llama 3 近期重磅发布,发布了 8B 和 70B 参数量的模型,opencompass团队对 Llama 3 进行了评测!
书生·浦语和机智流社区同学投稿了 OpenCompass 评测 Llama 3,欢迎 Star。
https://github.com/open-compass/OpenCompass/
https://github.com/SmartFlowAI/Llama3-Tutorial/
1.环境配置
conda create -n llama3 python=3.10
conda activate llama3
conda install git
apt install git-lfs
下载 Llama3 模型
软链接 InternStudio 中的模型
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct \
~/model
安装 OpenCompass
cd ~
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e .
遇到错误请运行:
pip install -r requirements.txt
pip install protobuf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
数据准备
下载数据集到 data/ 处
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
命令行快速评测
查看配置文件和支持的数据集名称
OpenCompass 预定义了许多模型和数据集的配置,你可以通过 工具 列出所有可用的模型和数据集配置。
# 列出所有配置
# python tools/list_configs.py
# 列出所有跟 llama (模型)及 ceval(数据集) 相关的配置
python tools/list_configs.py llama ceval
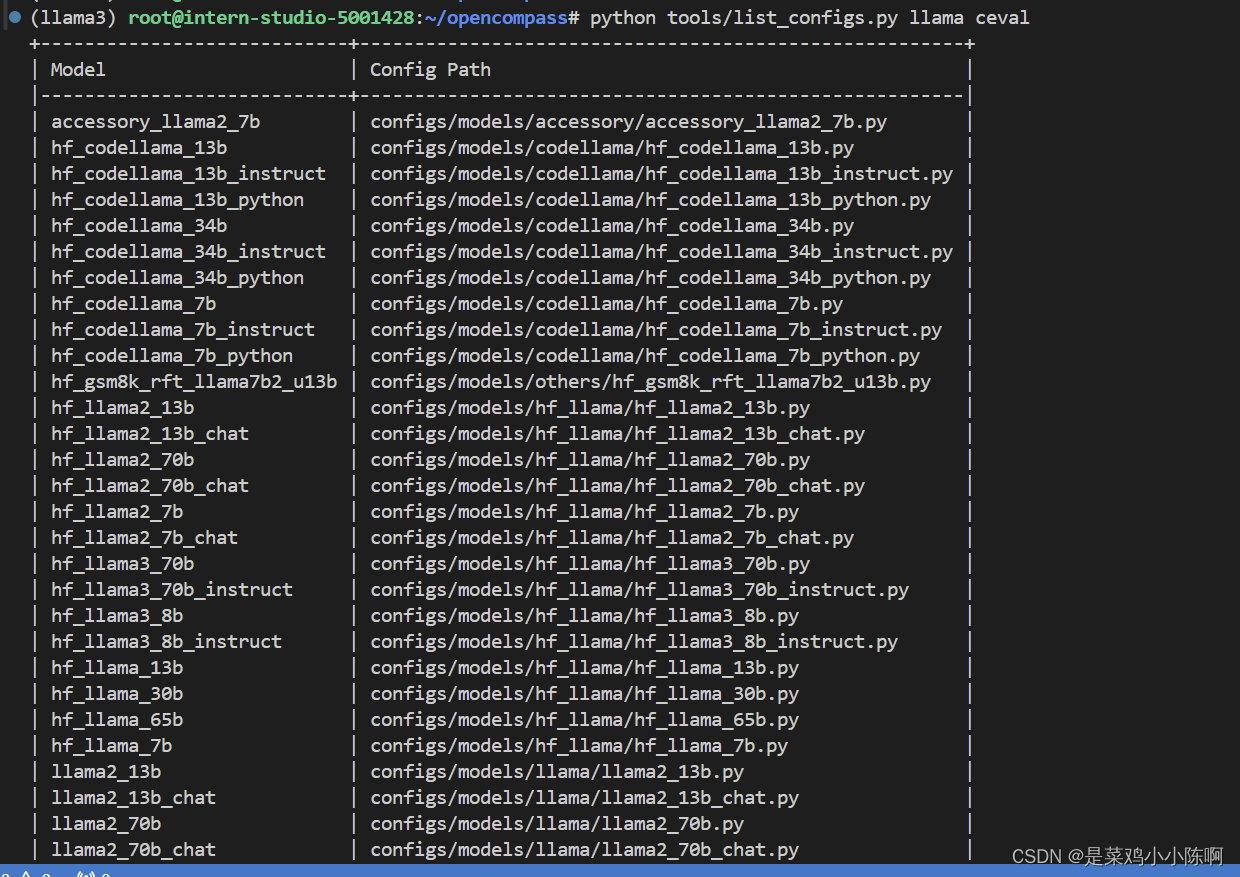
以 C-Eval_gen 为例:
git clone https://github.com/pltrdy/rouge
cd rouge
python setup.py install
python run.py --datasets ceval_gen --hf-path /root/model/Meta-Llama-3-8B-Instruct --tokenizer-path /root/model/Meta-Llama-3-8B-Instruct --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
命令解析
python run.py \
--datasets ceval_gen \
--hf-path /root/model/Meta-Llama-3-8B-Instruct \ # HuggingFace 模型路径
--tokenizer-path /root/model/Meta-Llama-3-8B-Instruct \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 2048 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 4 \ # 批量大小
--num-gpus 1 \ # 运行模型所需的 GPU 数量
--debug
config 快速评测
在 config 下添加模型配置文件 eval_llama3_8b_demo.py
from mmengine.config import read_base
with read_base():
from .datasets.mmlu.mmlu_gen_4d595a import mmlu_datasets
datasets = [*mmlu_datasets]
from opencompass.models import HuggingFaceCausalLM
models = [
dict(
type=HuggingFaceCausalLM,
abbr='Llama3_8b', # 运行完结果展示的名称
path='/root/model/Meta-Llama-3-8B-Instruct', # 模型路径
tokenizer_path='/root/model/Meta-Llama-3-8B-Instruct', # 分词器路径
model_kwargs=dict(
device_map='auto',
trust_remote_code=True
),
tokenizer_kwargs=dict(
padding_side='left',
truncation_side='left',
trust_remote_code=True,
use_fast=False
),
generation_kwargs={"eos_token_id": [128001, 128009]},
batch_padding=True,
max_out_len=100,
max_seq_len=2048,
batch_size=16,
run_cfg=dict(num_gpus=1),
)
]
30%A100显存不够,减小batch_size
在/root/opencompass/configs/datasets/mmlu/mmlu_gen_4d595a.py文中修改mmlu_all_sets,先仅测试第1个

运行python run.py configs/eval_llama3_8b_demo.py
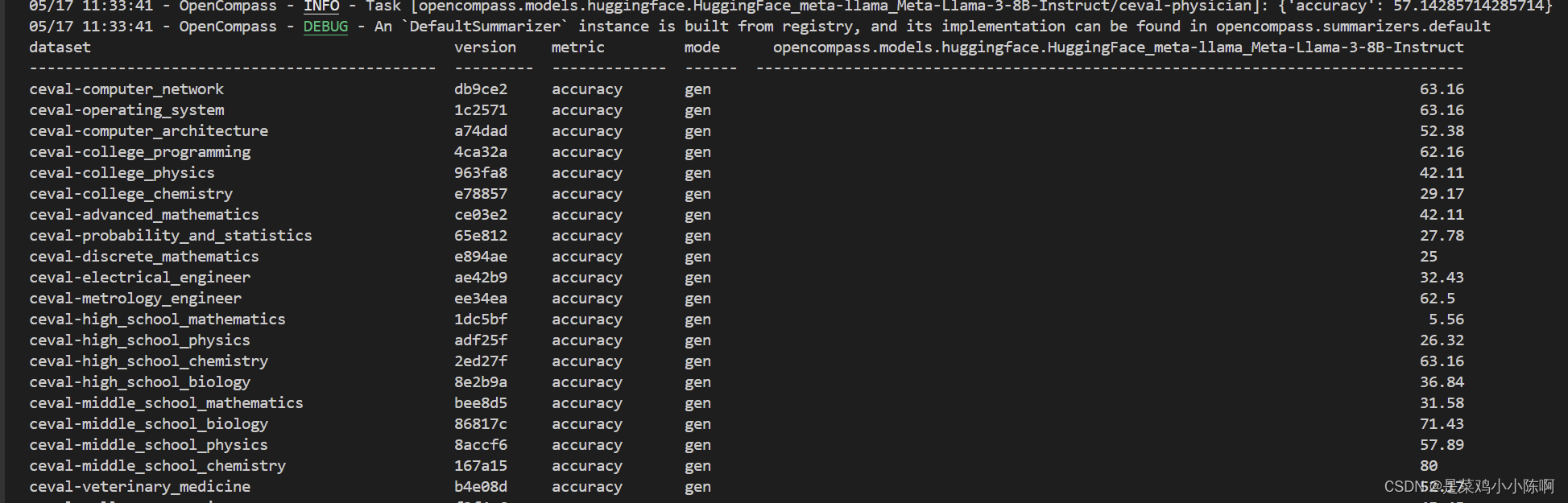
评测完成后,将会看到:
















 4563
4563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









