






异常值处理
箱线图分析删除异常值

上图是一个power字段的箱线图,从上图可以看出,这个图形中包含了大量异常数据点,它们偏离中间的数据主体。
箱线图如何判断数据是异常数据?
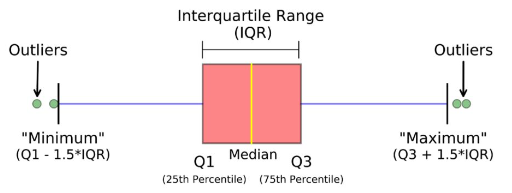
箱线图中间是一个箱体,也就是粉红色部分,Q1是下四分位数,Q3是上四分位数,中间是中位数,上下四分位数之差是四分位距(IQR),用Q1-1.5IQR得到下边缘,Q3+1.5IQR得到上边缘。在上边缘之外的数据就是极大异常值,在下边缘之外的数据就是极小异常值,总之,在上下边缘之外的就是异常值。图中的1.5是一个参数scale,可以自己设置,比如设置成3。
BOX-COX转换(处理有偏分布)
Box-Cox的变换公式:
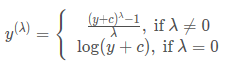

上图中的
λ
\lambda
λ取不同值时,曲线的斜率不一样。曲线斜率越大的区域,则对应区域的X变换后将被拉伸, 变换后这段区域的方差加大; 曲线斜率越小的区域, 对应区域的X变换后将被压缩, 变换后这段区域的方差变小。
上图中看出
λ
\lambda
λ = 0时, 取值较小的部分被拉伸, 取值较大的部分被压缩;
λ
\lambda
λ > 1时则相反. 所以box-cox变换的应用必须先分析输入X的分布是哪一种偏斜: X分布左偏,则应该应用l
λ
\lambda
λ= 0的变换; X分布右偏,则应该应用
λ
\lambda
λ > 1的变换。
长尾截断的方式
通过箱线图找出了异常点,可以通过长尾截断的方式处理异常点,也可以通过删除的方式处理异常点。长尾截断的方式即是将异常值赋值为非异常值的最小值或者是最大值。
缺失值处理
删除
如果缺失值的样本不多的话,可以直删除。
不处理
有些算法可以处理缺失值的情况,所以可以不用进行处理。
插值补全
目标是使用可以在数据集的有效值中识别的已知关系来辅助估计缺失值。
统计量
通过均值、众数和中位数来进行补全。
在这种情况下,我们计算该变量的所有非缺失值的mean或Median,然后用Mean或Median替换缺失值。
预测模型
通过创建一个预测模型来估计替代缺失值。
在这种情况下,我们将数据集分为两组:一组没有变量的缺失值,另一组有缺少值, 第一个数据集成为模型的训练数据集,而具有缺失值的第二个数据集是测试数据集,变量与缺失值被视为目标变量。 接下来,我们创建一个模型,根据训练数据集的其他属性预测目标变量,并填充测试数据集的缺失值。我们可以使用回归,方差分析,逻辑回归和各种建模技术来执行此操作。
KNN
此方法使用与值丢失的属性最相似的属性来估计属性的缺失值,通过距离函数确定两个属性的相似度。
分箱
数据分箱处理, 即把一段连续的值切分成若干段,每一段的值看成一个分类。通常把连续值转换成离散值的过程,我们称之为分箱处理。在处理缺失值时可以把缺失值分为一个箱。
数据分桶
连续值经常离散化或者分离成“箱子”进行分析, 为什么要做数据分桶呢?
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
等频分桶
区间的边界值要经过选择,使得每个区间包含大致相等的实例数量。比如说 N=10 ,每个区间应该包含大约10%的实例。
等距分桶
从最小值到最大值之间,均分为 N 等份, 这样, 如果 A,B 为最小最大值, 则每个区间的长度为 W=(B−A)/N , 则区间边界值为A+W,A+2W,….A+(N−1)W 。这里只考虑边界,每个等份里面的实例数量可能不等。
Best-KS分桶
Best-KS分箱的算法执行过程是一个逐步拆分的过程:
- 将特征值值进行从小到大的排序。
- 计算出KS最大的那个值,即为切点,记为D。然后把数据切分成两部分。
- 重复步骤2,进行递归,D左右的数据进一步切割。直到KS的箱体数达到我们的预设阈值即可。
Best-KS分箱的特点:
- 连续型变量:分箱后的KS值<=分箱前的KS值
- 分箱过程中,决定分箱后的KS值是某一个切点,而不是多个切点的共同作用。这个切点的位置是原始KS值最大的位置。
卡方分桶
自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想:
对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
数据转换
标准化
将数据转换为标准正态分布
归一化
将数据转换到[0,1]区间
幂律分布处理
可以采用公式: l o g ( 1 + x 1 + m e d i a n ) log(\frac{1+x}{1+median}) log(1+median1+x)















 8814
8814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









