








概述
神经网络算法是机器学习和人工智能的基础。在各种神经网络算法中,最简单的是BP神经网络算法。本文将介绍BP神经网络算法基本原理,并提供一个BP神经网络算法完成聚类分析的案例。
BP神经网络具有输入层、隐含层(一层或多层)和输出层,通过这三层的神经网络可以逼近任意非线性函数。以二维输入样本,三个隐含层神经元为例:
参数说明:权值矩阵为W和V,阀值矩阵为θ1和θ2,传递函数为F(X)和G(X)。
当输出值Z1和样本中输入值Y1存在差值时,误差一步步反向回传,分配给权值矩阵和阀值矩阵。经过多次运算后,差值回逐渐趋于0。
流程图
BP神经网络算法的核心,在于每次计算得到输出值和样本值的误差,并根据误差按负梯度方向反向调整权值和阀值矩阵。流程图如下图示:
代码实现
本文中,隐含层和输出层的传递函数均采用: y=1/(1+exp(-x))。
输入数据如下:样本对(X,Y)中,X为 x∈[-3,3],y∈[-3,3]范围内的随机点位;Y为0或者1,当X在(x-1)(x-1) +y^2 <=2或者(x+1)(x+1)+y^2<=2范围内时,Y=1;其余情况为0。
%% 数据准备,100个样本对,30个测试对
MatrixX=6*rand(100,2)-3*ones(100,2);%%输入值
MatrixY=zeros(100,1);%%输出值
TestMatrixY=zeros(100,1);%%输出值
for i=1:100
Circle1=(MatrixX(i,1)-1)^2+MatrixX(i,2)^2;
Circle2=(MatrixX(i,1)+1)^2+MatrixX(i,2)^2;
if(Circle1<2||Circle2<2)
MatrixY(i)=1;
end
end
Max1=max(max(MatrixX));
Max2=max(MatrixY);
Maxt=max(Max1,Max2);
%% 训练
NumHide=50;%%隐含层节点数
Yita1=0.8;%%学习率
Yita2=0.8;%%学习率
W1=2*rand(NumHide,2)-1*ones(NumHide,2);%%权值矩阵W1
W2=2*rand(1,NumHide)-1*ones(1,NumHide);%%权值矩阵W2
Sita1=(2*rand(NumHide,1)-1*ones(NumHide,1))';%%阀值矩阵
Sita2=2*rand(1,1)-1;%%阀值矩阵
Times=1;
TimesLimits=500000;
residual=zeros(TimesLimits,1);%%误差收敛情况
while(Times<=TimesLimits)
for i=1:100
DetaW1=zeros(NumHide,2);
DetaW2=zeros(1,NumHide);
DetaSita1=zeros(NumHide,1);
DetaSita2=zeros(1,1);
X1=MatrixX(i,:)/Maxt; %%归一化
Y1=MatrixY(i)/Maxt;%%归一化
%% 计算隐含层神经元
NetX=X1*W1'+Sita1;%%1行10列
FNetX=NetX;
F1NetX=NetX;%%f'(NetX)
for j=1:NumHide
FNetX(j)=1/(1+exp(-NetX(j)));
F1NetX(j)=FNetX(j)*(1-FNetX(j));
end
%% 计算输出层神经元
NetY=FNetX*W2'+Sita2;
GNetY=1/(1+exp(-NetY));
G1NetY=GNetY*(1-GNetY);
residual(Times)=residual(Times)+sqrt((Y1-GNetY)^2);
%% 计算梯度
Deta2=(Y1-GNetY)*G1NetY;%%1行1列
Deta1=Deta2*F1NetX.*W2;%%1行10列
DetaW1=DetaW1+Yita1*Deta1'*X1;%%10行2列
DetaW2=DetaW2+Yita2*Deta2*FNetX;%%一行十列
DetaSita1=DetaSita1+Yita1*Deta1';
DetaSita2=DetaSita2+Yita2*Deta2;
%% 权值和阀值更新
W1=W1+DetaW1;
W2=W2+DetaW2;
Sita1=Sita1+DetaSita1';
Sita2=Sita2+DetaSita2;
end
Times=Times+1;
end
%% 结果测试
sitas=0:0.01*pi:2*pi;
Xzixs=sqrt(2)*cos(sitas)-ones(1,201);
Yzixs=sqrt(2)*sin(sitas);
plot(Xzixs,Yzixs,'-');%%画1#圆
hold on;
Xzixs=sqrt(2)*cos(sitas)+ones(1,201);
Yzixs=sqrt(2)*sin(sitas);
plot(Xzixs,Yzixs,'-');%%画2#圆
TestX=6*rand(30,2)-3*ones(30,2);%%输入值
TestY=zeros(30,1);%%输出值
for i=1:30
X1=TestX(i,:)/Maxt;
Net=X1*W1'+Sita1;
FNet=Net;
for j=1:NumHide
FNet(j)=1/(1+exp(-Net(j)));
end
Netk=FNet*W2'+Sita2;
GNet=1/(1+exp(-Netk));
TestY(i)=GNet;
end
TestY=TestY*Maxt;
% 画测试点
for i=1:30
if(TestY(i)>0.5)
plot(TestX(i,1),TestX(i,2),'r*');
hold on;
else
plot(TestX(i,1),TestX(i,2),'r.');
hold on;
end
end
实现效果
先画出区域范围,随机生成30个点,区域内的点标记为“*”,区域外的点标记为“.”,程序运行结果如下图示:
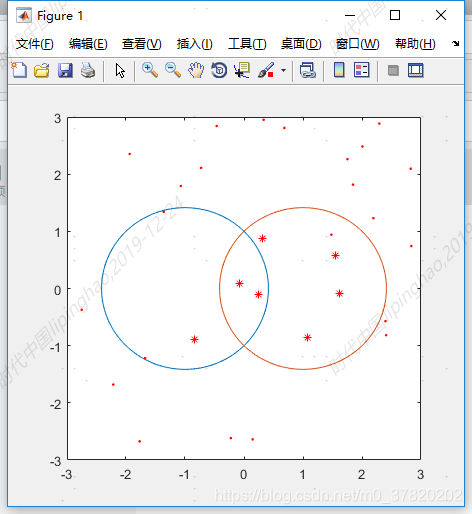
由上图可知,有3个圆圈范围内的点错误地标记为了“.”,其余点标记正确,正确率为90%。如果输入样本增多,就可以进一步提高正确率。


















 2928
2928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











