









题目
从网上下载或自己变成实现Adaboost,以不剪枝决策树为基学习器,在西瓜集数据集3.0 α \alpha α上训练一个AdaBoost继承,并与图8.4进行比较。
分析原理
简单来说Adaboost得到的是一个加法模型,他通过迭代计算一个一个的分类器,然后以一定的权值相加在一起,得到一个总的模型。因为每一个单独的分类器,都依靠上一次的训练结果在进行这一次的训练,所以这就是所谓的串行训练。
Adaboost实际上用错误率做了两件事:
- 根据当前训练所得分类器的错误率得到当前分类器在总分类器中的权值。理所当然,当前分类器的正确率越高,此权值就越大。
- 根据错误率修改当前样本的权值分布。初始每个数据的权值都是一样的,当前分类器误分的数据将会得到更大的权值,目的是在下一个分类器的训练中,重点关注之前容易被误分的数据,减少错误率。
代码
# coding=utf-8
import numpy as np
import matplotlib.pyplot as plt
def getDataSet():
"""
西瓜数据集3.0alpha。 列:[密度,含糖量,好瓜]
:return: np数组。
"""
dataSet = [
[0.697, 0.460, '是'],
[0.774, 0.376, '是'],
[0.634, 0.264, '是'],
[0.608, 0.318, '是'],
[0.556, 0.215, '是'],
[0.403, 0.237, '是'],
[0.481, 0.149, '是'],
[0.437, 0.211, '是'],
[0.666, 0.091, '否'],
[0.243, 0.267, '否'],
[0.245, 0.057, '否'],
[0.343, 0.099, '否'],
[0.639, 0.161, '否'],
[0.657, 0.198, '否'],
[0.360, 0.370, '否'],
[0.593, 0.042, '否'],
[0.719, 0.103, '否']
]
# 将是否为好瓜的字符替换为数字。替换是因为不想其他列的数值变成字符变量。
for i in range(len(dataSet)): # '是'换为1,'否'换为-1。
if dataSet[i][-1] == '是':
dataSet[i][-1] = 1
else:
dataSet[i][-1] = -1
return np.array(dataSet)
def calErr(dataSet, feature, threshVal, inequal, D):
"""
计算数据带权值的错误率。
:param dataSet: [密度,含糖量,好瓜]
:param feature: [密度,含糖量]
:param threshVal:
:param inequal: 'lt' or 'gt. (大于或小于)
:param D: 数据的权重。错误分类的数据权重会大。
:return: 错误率。
"""
DFlatten = D.flatten() # 变为一维
errCnt = 0
i = 0
if inequal == 'lt':
for data in dataSet:
if (data[feature] <= threshVal and data[-1] == -1) or \
(data[feature] > threshVal and data[-1] == 1):
errCnt += 1 * DFlatten[i]
i += 1
else:
for data in dataSet:
if (data[feature] >= threshVal and data[-1] == -1) or \
(data[feature] < threshVal and data[-1] == 1):
errCnt += 1 * DFlatten[i]
i += 1
return errCnt
def buildStump(dataSet, D):
"""
通过带权重的数据,建立错误率最小的决策树桩。
:param dataSet:
:param D:
:return: 包含建立好的决策树桩的信息。如feature,threshVal,inequal,err。
"""
m, n = dataSet.shape
bestErr = np.inf
bestStump = {}
for i in range(n-1): # 对第i个特征
for j in range(m): # 对第j个数据
threVal = dataSet[j][i]
for inequal in ['lt', 'gt']: # 对于大于或等于符号划分。
err = calErr(dataSet, i, threVal, inequal, D) # 错误率
if err < bestErr: # 如果错误更低,保存划分信息。
bestErr = err
bestStump["feature"] = i
bestStump["threshVal"] = threVal
bestStump["inequal"] = inequal
bestStump["err"] = err
return bestStump
# 一些测试代码。
# dataSet = getDataSet()
# D = np.ones((1, dataSet.shape[0])) / dataSet.shape[0]
# print(buildStump(dataSet, D))
# pos = []
# neg = []
# for data in dataSet:
# if data[-1] == 1:
# pos.append(data)
# else:
# neg.append(data)
# pos = np.array(pos)
# neg = np.array(neg)
# plt.scatter(pos[:, 0], pos[:, 1], label="pos")
# plt.scatter(neg[:, 0], neg[:, 1], label="neg")
# x1 = np.linspace(0, 1, 10)
# plt.plot(x1, [0.211] * 10)
# plt.show()
def predict(data, bestStump):
"""
通过决策树桩预测数据
:param data: 待预测数据
:param bestStump: 决策树桩。
:return:
"""
if bestStump["inequal"] == 'lt':
if data[bestStump["feature"]] <= bestStump["threshVal"]:
return 1
else:
return -1
else:
if data[bestStump["feature"]] >= bestStump["threshVal"]:
return 1
else:
return -1
def AdaBoost(dataSet, T):
"""
每学到一个学习器,根据其错误率确定两件事。
1.确定该学习器在总学习器中的权重。正确率越高,权重越大。
2.调整训练样本的权重。被该学习器误分类的数据提高权重,正确的降低权重,
目的是在下一轮中重点关注被误分的数据,以得到更好的效果。
:param dataSet: 数据集。
:param T: 迭代次数,即训练多少个分类器
:return: 字典,包含了T个分类器。
"""
m, n = dataSet.shape
D = np.ones((1, m)) / m # 初始化权重,每个样本的初始权重是相同的。
classLabel = dataSet[:, -1].reshape(1, -1) # 数据的类标签。
G = {} # 保存分类器的字典,
for t in range(T):
stump = buildStump(dataSet, D) # 根据样本权重D建立一个决策树桩
err = stump["err"]
alpha = np.log((1 - err) / err) / 2 # 第t个分类器的权值
# 更新训练数据集的权值分布
pre = np.zeros((1, m))
for i in range(m):
pre[0][i] = predict(dataSet[i], stump)
a = np.exp(-alpha * classLabel * pre)
D = D * a / np.dot(D, a.T)
G[t] = {}
G[t]["alpha"] = alpha
G[t]["stump"] = stump
return G
def adaPredic(data, G):
"""
通过Adaboost得到的总的分类器来进行分类。
:param data: 待分类数据。
:param G: 字典,包含了多个决策树桩
:return: 预测值
"""
score = 0
for key in G.keys():
pre = predict(data, G[key]["stump"])
score += G[key]["alpha"] * pre
flag = 0
if score > 0:
flag = 1
else:
flag = -1
return flag
def calcAcc(dataSet, G):
"""
计算准确度
:param dataSet: 数据集
:param G: 字典,包含了多个决策树桩
:return:
"""
rightCnt = 0
for data in dataSet:
pre = adaPredic(data, G)
if pre == data[-1]:
rightCnt += 1
return rightCnt / float(len(dataSet))
def main():
dataSet = getDataSet()
for t in [3, 5, 11]: # 学习器的数量
G = AdaBoost(dataSet, t)
print(f"G{t} = {G}")
print(calcAcc(dataSet, G))
if __name__ == '__main__':
main()
输出:
分类器和准确度。T表示分类器的数量。直接打印出来不直观,我整理了下格式。
T=3
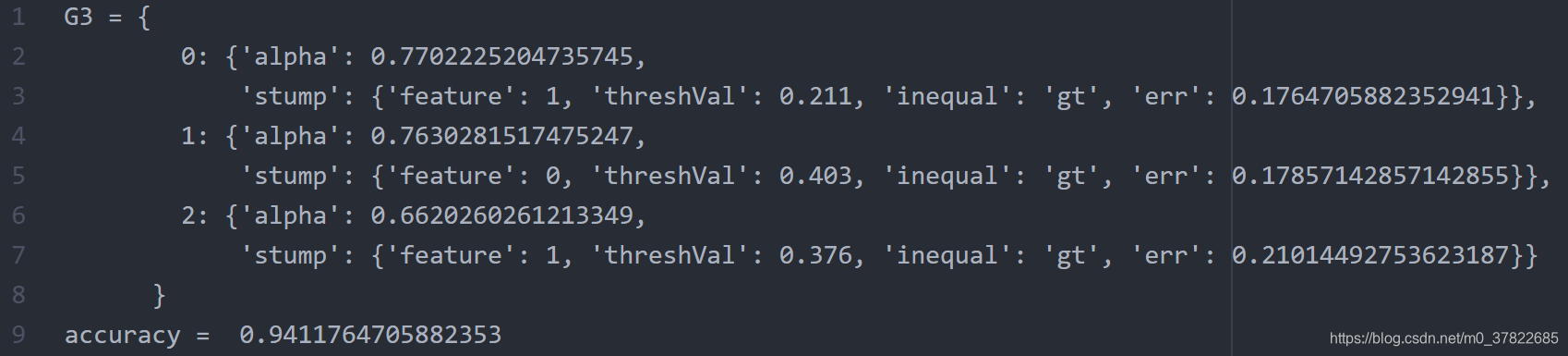
T=5
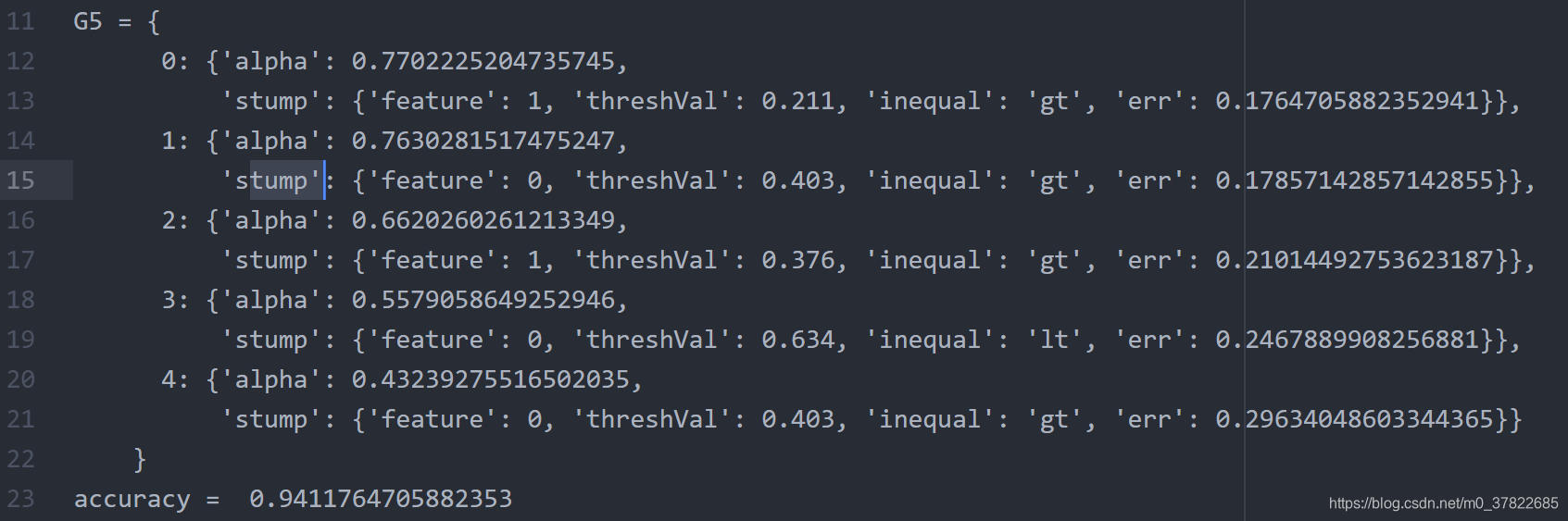
T=11
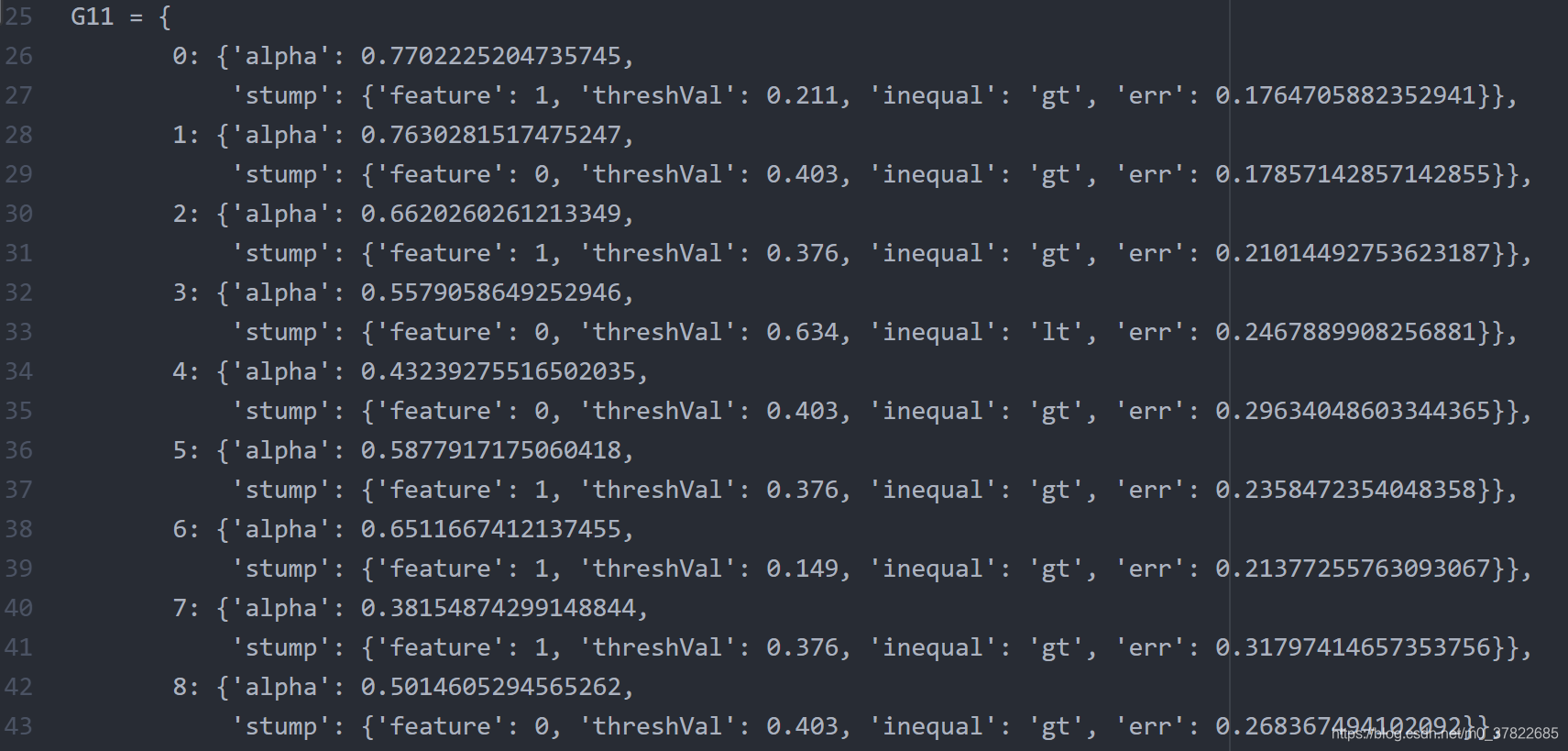

可以看出11个基学习器就已经在训练集上得到了百分之百的正确率。

















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









