









视频理解论文zoo
- SlowFast Networks for Video Recognition
- Gcnet: Non-local networks meet squeeze-excitation networks and beyond
- Video Classification With Channel-Separated Convolutional Networks
- STM: SpatioTemporal and Motion Encoding for Action Recognition
- More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation
- facebook的工作:SCSampler: Sampling Salient Clips from Video for Efficient Action Recognition
- Action Recognition With Spatial-Temporal Discriminative Filter Banks
- Self-supervised Co-training for Video Representation Learning
- Temporal Pyramid Network for Action Recognition
- Further Understanding Videos through Adverbs: A New Video Task
- Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
- What Makes Training Multi-Modal Classification Networks Hard?
- TEINet: Towards an Efficient Architecture for Video Recognition
- Knowledge Integration Networks for Action Recognition
- Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
- Intra- and Inter-Action Understanding via Temporal Action Parsing
- Similarity Reasoning and Filtration for Image-Text Matching
- TEA: Temporal Excitation and Aggregation for Action Recognition
- Multi-Modal Domain Adaptation for Fine-Grained Action Recognition
- TAM: TEMPORAL ADAPTIVE MODULE FOR VIDEO
- Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion
- 新的改变
- 功能快捷键
- 合理的创建标题,有助于目录的生成
- 如何改变文本的样式
- 插入链接与图片
- 如何插入一段漂亮的代码片
- 生成一个适合你的列表
- 创建一个表格
- 创建一个自定义列表
- 如何创建一个注脚
- 注释也是必不可少的
- KaTeX数学公式
- 新的甘特图功能,丰富你的文章
- UML 图表
- FLowchart流程图
- 导出与导入
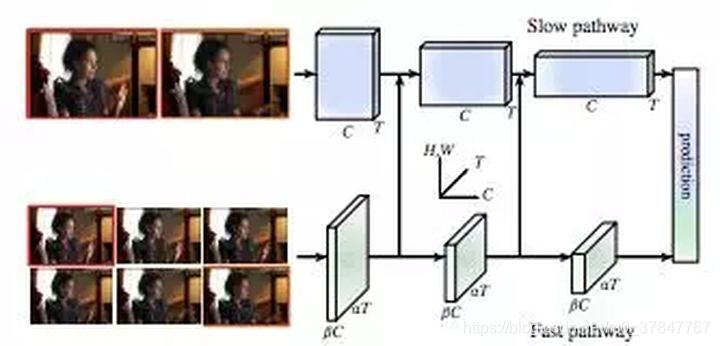
SlowFast Networks for Video Recognition
其中一个路径旨在捕获图像或几个稀疏帧提供的语义信息,它以低帧率运行,刷新速度缓慢。而另一个路径用于捕获快速变化的动作,它的刷新速度快、时间分辨率高。
Gcnet: Non-local networks meet squeeze-excitation networks and beyond
GCNet深入探讨了Non-local和SENet的优缺点,然后结合Non-local和SENet的优点提出了GCNet

Video Classification With Channel-Separated Convolutional Networks
改了结构
STM: SpatioTemporal and Motion Encoding for Action Recognition
时空特征和运动特征是视频动作识别中两个互补且至关重要的信息。最近最先进的方法采用3D CNN流学习时空特征,并采用另一个流流学习运动特征。在这项工作中,我们的目标是在一个统一的2D框架中有效地编码这两个特征。为此,我们首先提出了一个STM块,它包含一个信道的时空模块(CSTM)来表示时空特征和一个信道的运动模块(CMM)来有效地编码运动特征。然后我们用STM块替换原有的ResNet体系结构中的剩余块,通过引入非常有限的额外计算成本,形成一个简单而有效的STM网络。大量的实验表明,通过将时空和运动特征一起编码,提出的STM网络在时间相关数据集(即Something-Something v1 & v2和Jester)和场景相关数据集(即Kinetics400、UCF-101和HMDB-51)上都优于最先进的方法。
改结构

More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation
改结构
我们的方法在FLOPs中实现了3 ~ 4倍的减少,在FLOPs中实现了约2倍的减少 与基线相比的内存使用情况。这使得训练更深层次的模型成为可能 在相同的计算预算下有更多的输入帧。

facebook的工作:SCSampler: Sampling Salient Clips from Video for Efficient Action Recognition
视频信息冗余
由于真实的无剪辑的视频通常时间跨度大, 其中每一段包含相关的信息也是不一样的, 重要的和冗余的信息都有. 所以文章提出一种"clip-sampling"的模型, 它可以有效的识别一段长视频中最显著的片段. 并且可以有效的降低无修剪视频的computational cost.
动机:一个视频序列中会有很多与动作分类不相关的帧,从而产生无意义的结果,能否得到一种方法对于这些无意义的帧赋予一个低的权重?

Action Recognition With Spatial-Temporal Discriminative Filter Banks
在过去的几年中,动作识别的性能有了显着提高。当前,大多数最新技术文献旨在通过更改主干CNN网络来提高性能,或者再次通过更改主干网络来探索计算效率与性能之间的不同折衷。但是,几乎所有这些工作都保持网络的最后一层相同,它们仅包含全局平均池,然后是完全连接的层。在这项工作中,我们着重于如何提高网络的表示能力,而不是改变骨干网,而着重于改进网络的最后一层,其中更改对计算成本的影响很小。特别是,我们假设当前的架构对更精细的细节不敏感,并且我们利用细粒度识别文献中的最新进展来改进此方面的模型。通过提出的方法,我们在两个主要的大型动作识别基准Kinetics-400和Something-Something-V1上获得了最先进的性能
动机:如何提高网络的表示能力,而不是改变骨干网,而着重于改进网络的最后一层
Self-supervised Co-training for Video Representation Learning
本文的目标是仅视觉自我监督视频表示学习。我们做出以下贡献:(i)我们研究了在基于实例的“信息噪声对比估计”(InfoNCE)训练中添加语义类肯定句的好处,表明这种形式的监督式对比学习可明显改善性能;(ii)我们提出了一种新颖的自我监督协同训练方案,以通过使用一个视图获取同一数据源的正视图样本来利用同一数据源的不同视图,RGB流和光流的互补信息来改善流行的infoNCE损失。另一个; (iii)我们在两个不同的下游任务(动作识别和视频检索)上全面评估所学表示的质量。在这两种情况下
动机:视频表示
Temporal Pyramid Network for Action Recognition
本文提出TPN(Temporal Pyramid Network)网络结构,特点是金字塔。起源于对视频动作快慢得研究,在多个数据集上取得优秀得结果。与本文思想相似的是Facebook 提出的SlowFast网络

Further Understanding Videos through Adverbs: A New Video Task
** 动机**: dataset
Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
** 动机**: dataset
与传统的训练集、数据集划分方法(训练集测试集包含相同的动词和名词)不同,我们在相同的动词、不同的名词上面训练和测试,因此我们测试集中的动词+名词的组合之前从来没见过。
现有的动作识别模型不能捕捉这种动词、名词的组合关系。
在本文中,我们提出了一个基于稀疏且语义丰富的学习对象图的模型(a model based on a sparse and semantically-rich object graph learned for each action)
Something-Something数据集则希望不通过外观信息来识别动作。我们在此基础上更进一步,提出了compositional action recognition任务,并进一步标注了bbox。
这个任务是,显式地组合视频中的动作主体和目标,并学习建模他们之间的关系来实现动作识别。并且通过组合动词和名词,来识别没有见过的动作。

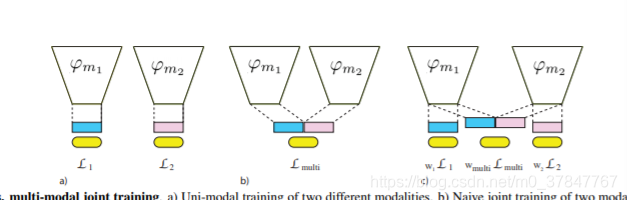
What Makes Training Multi-Modal Classification Networks Hard?
考虑对具有多个输入模态的任务进行多模态网络与单模态网络的端到端训练:多模态网络会接收更多信息,因此它应与单模态网络匹配或胜过其单模态网络。但是,在我们的实验中,我们观察到相反的情况:最佳的单模态网络可以胜过多模态网络。在不同的模式组合上以及在视频分类的不同任务和基准上,这种观察是一致的。本文确定了造成这种性能下降的两个主要原因:首先,由于容量增加,多模态网络经常容易出现过拟合现象。其次,不同的模式过拟合并以不同的速率泛化,因此使用单个优化策略联合训练它们是次优的。我们使用一种称为梯度混合的技术来解决这两个问题,它根据过拟合行为来计算模态的最佳混合。我们证明了Gradient Blending优于广泛使用的基准,可以避免过拟合,并在包括人类动作识别,以自我为中心的动作识别和声音事件检测在内的各种任务上实现了最先进的准确性
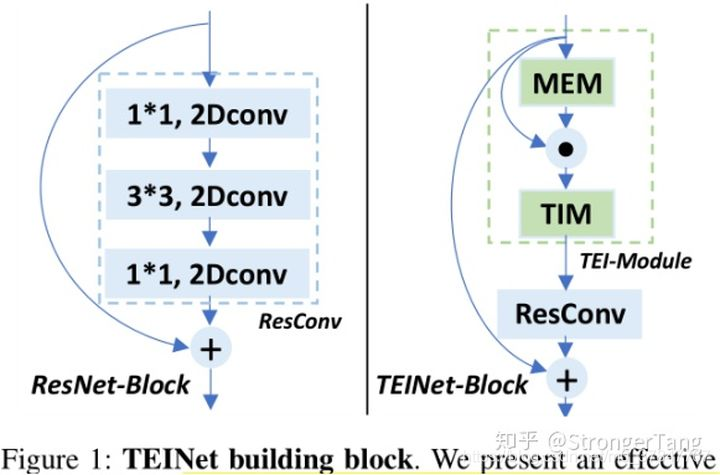
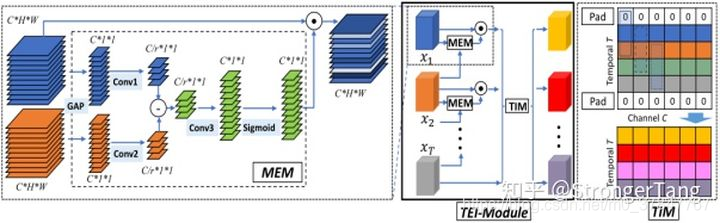
TEINet: Towards an Efficient Architecture for Video Recognition
在视频动作识别的架构设计中,效率是一个重要的问题。3D CNNs在视频动作识别方面取得了显著的进展。然而,与二维卷积相比,三维卷积往往引入大量的参数,导致计算量大。为了解决这个问题,我们提出了一个有效的时序模块,称为Temporal Enhancement-and-Interaction(TEI模块),它可以插入到现有的2D CNNs中。TEI模块通过分离通道相关和时间交互的建模,提出了一种不同的学习时间特征的范式。首先,它包含一个运动增强模块(MEM),该模块在抑制无关信息(例如背景)的同时增强与运动相关的特征。
然后,介绍了一个时序交互模块(TIM),它以通道方式补充时序上下文信息。该两阶段建模方案不仅能够灵活有效地捕捉时间结构,而且能够有效地进行模型推理。我们进行了大量的实验来验证TEINet在Something-Something V1&V2, Kinetics, UCF101 and HMDB51几个基准上的有效性。TEINet可以在这些数据集上达到很好的识别精度,同时保持很高的效率。
Shift思想在视频理解中的近期进展
TSM(ICCV2019) Temporal Shift Module for Efficient Video Understanding
Temporal Interlacing Network(aaai2020)
TEINet: Towards an Efficient Architecture for Video Recognition(aaai2020)
Gate-Shift Networks for Video Action Recognition(cvpr2020)
Learnable Gated Temporal Shift Module for Deep Video Inpainting(BMVC2019)
通过在2D CNN中位移 temporal 维度上的 channels,来实现时间上的信息交互。故不需要添加任何额外参数,且能捕捉Long-term 时空上下文关系。
参考链接: link
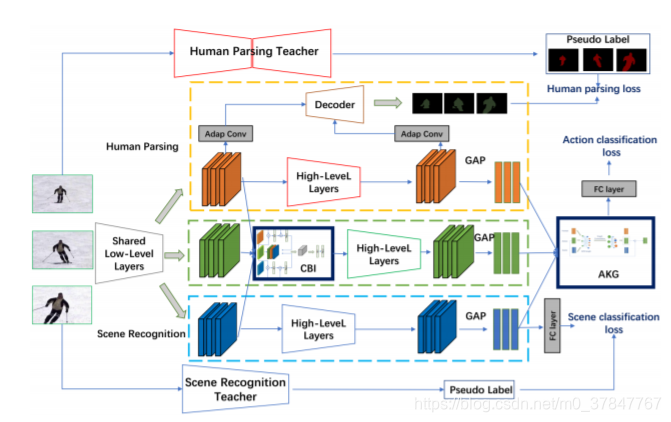
Knowledge Integration Networks for Action Recognition
在这项工作中,我们提出了用于视频动作识别的知识集成网络(简称KINet)。KINet能够聚合有意义的上下文特征,这些特征对于识别一个动作非常重要,如人类信息和场景上下文。我们设计了一个三分支体系结构,包括一个主要的动作识别分支,两个辅助的人体解析和场景识别分支,使模型能够编码人类和场景的知识用于动作识别。我们探索了两种训练前的教师网络模型,即提取人的知识和场景的知识,用于训练KINet的辅助任务。此外,我们提出了一种两级知识编码机制,该机制包括一个跨分支集成(CBI)模块,用于将辅助知识编码为中层卷积特征,以及一个动作知识图(AKG),用于有效地融合高层上下文信息。这就产生了一个端到端可训练的框架,三个任务可以协同训练,使模型能够有效地计算强大的上下文知识。所提出的KINet在大规模动作识别基准Kinetics-400上实现了最先进的性能,准确率最高达到77.8%。通过将经过动力学训练的模型转移到UCF-101,进一步证明了我们的KINet具有较强的性能,其精度达到97.8% top-1。
** 动机 **:KINet能够聚合有意义的上下文特征,这些特征对于识别一个动作非常重要,如人类信息和场景上下文。
Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
神经符号表示已被证明可以有效地学习视觉和语言中的结构信息。在本文中,我们提出了一种用于学习视频字幕的多模式神经符号表示的新模型架构。我们的方法使用基于字典学习的方法来学习视频及其配对文本描述之间的关系。我们将这些关系称为相对角色,并利用它们来引起每个令牌角色的注意。这将导致结构化和可解释性更高的体系结构,其中结合了字幕任务特定于模式的归纳偏差。直观地,该模型能够学习给定视频和文本对中的空间,时间和跨模式关系。我们的建议实现的解纠缠度使该模型具有更多功能来捕获多模式结构,从而为视频提供了更高质量的字幕。我们对两个已建立的视频字幕数据集进行的实验验证了基于自动指标的方法的有效性。我们进一步进行了人工评估,以测量所生成字幕的基础和相关性,并观察所提出模型的持续改进。代码和训练有素的模型可以在下面找到 我们进一步进行了人工评估,以测量所生成字幕的基础和相关性,并观察所提出模型的持续改进。代码和训练有素的模型可以在下面找到 我们进一步进行了人工评估,以测量所生成字幕的基础和相关性,并观察所提出模型的持续改进

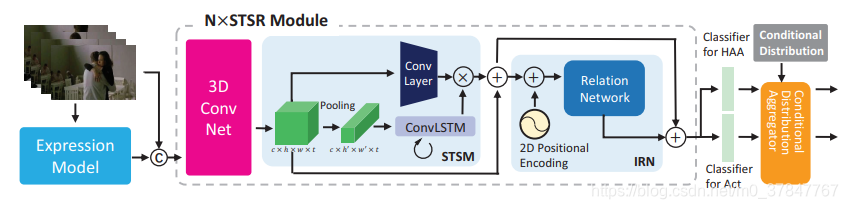
Intra- and Inter-Action Understanding via Temporal Action Parsing
邵典的论文 方法+dataset
当前用于动作识别的方法主要依靠深度卷积网络来导出视觉和运动特征的特征嵌入。尽管这些方法在标准基准上表现出了卓越的性能,但我们仍然需要更好地了解视频,尤其是其内部结构与高级语义的关系,这可能会带来多方面的好处,例如可解释性预测,甚至可以将识别性能提升到新水平的新方法。为了实现这一目标,我们构建了TAPOS,这是一个在体育视频上开发的带有子动作手动注释的新数据集,并在顶部进行了时间动作解析研究。我们的研究表明,体育活动通常由多个子动作组成,并且这种时间结构的意识有助于动作识别。我们还研究了许多时间解析方法,并在其上设计了一种改进的方法,**该方法能够从训练数据中挖掘子动作而无需知道它们的标签。**在构建的TAPOS上,显示了所提出的方法以揭示动作内信息(即动作实例如何由子动作构成)以及交互作用信息(即一个特定的子动作)通常会出现在各种动作中
Similarity Reasoning and Filtration for Image-Text Matching

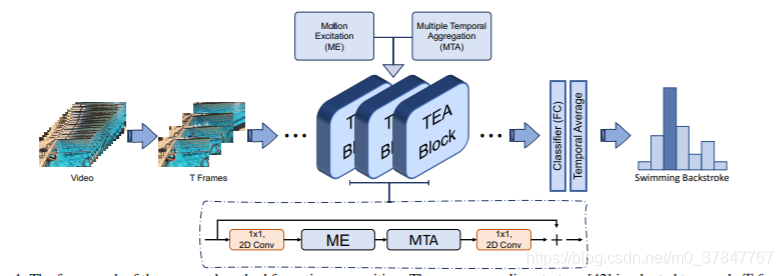
TEA: Temporal Excitation and Aggregation for Action Recognition
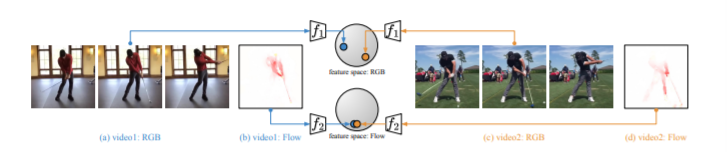
Multi-Modal Domain Adaptation for Fine-Grained Action Recognition
细粒度的动作识别数据集表现出环境偏差,其中从有限数量的环境中捕获了多个视频序列。由于不可避免的域转移,在一个环境中训练模型并在另一个环境中部署会导致性能下降。无监督域适应(UDA)方法经常利用源域和目标域之间的对抗训练。但是,这些方法尚未探索每个域内视频的多模式性质。在这项工作中,除了对抗性对齐(图1),我们还将模式的对应性作为UDA的一种自我监督的对齐方法。我们使用大规模用于动作识别的两种模式:RGB和光学流,在大型EPIC-Kitchens数据集中的三个厨房上测试了我们的方法。我们显示,仅多模式自我监督比仅进行源训练的性能平均提高了2.4%。然后,我们将对抗训练与多模式自我监督相结合,表明我们的方法比其他UDA方法要好3%。

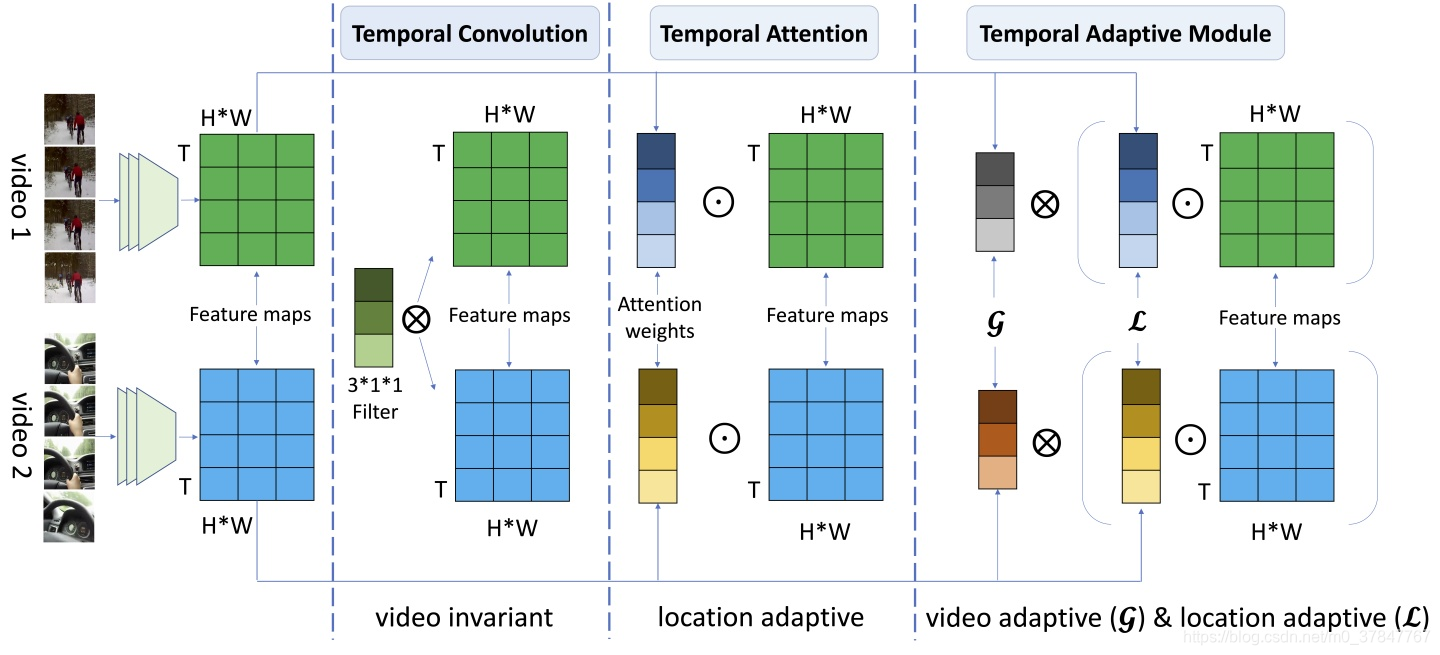
TAM: TEMPORAL ADAPTIVE MODULE FOR VIDEO
在视频动作识别中,时序建模对学习视频中的时序结构信息至关重要。但由于受多种因素的影响(例如相机运动,视角切换,场景多样),导致视频数据在时序维度上具有及其复杂的动态特性。为了能够有效捕捉视频中的时序动态特性,我们提出了一种自适应的时序建模方法TAM (Temporal Adaptive Module)。TAM中的时序核参数被分解成位置敏感的自适应权重和位置无关的自适应卷积核,以视频自适应方式动态地学习其中的时序线索。基于TAM实例化得到的TANet,在Kinetics-400、Something-Something数据集上均取得了优异的性能。
不同视频在时序维度上呈出不同的运动模式。为了解决这个问题,时序自适应模块(TAM)为每个视频生成特定的时序建模核。该算法针对不同视频片段,灵活高效地生成动态时序核,自适应地进行时序信息聚合。
作者说它论文的链接link
Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion
我们期望视频表示学习能够捕获的一个重要因素,尤其是与图像表示学习相反的是对象运动。但是,我们发现在当前的主流视频数据集中,某些动作类别与发生动作的场景高度相关,这使得模型倾向于退化为仅对场景信息进行编码的解决方案。例如,==**受过训练的模型可能只是因为看到了场地而忽略了对象在场地上作为啦啦队长跳舞,因此可以将视频预测为正在踢足球 **==这违背了我们对视频表示学习的初衷,并且可能给不同的数据集带来场景偏见,这是不容忽视的。为了解决这个问题,我们建议通过两个简单的操作将场景和运动(DSM)分离,因此,模型对运动信息的关注会得到更好的回报。具体来说,我们为每个视频构造一个正向剪辑和一个负向剪辑。与原始视频相比,正/负通过空间局部扰动和时间局部扰动来保持运动不变/破碎,而场景破坏/保持不变。我们的目标是将正片拉近,同时将负片推到潜在空间中的原始片段。这样,可以减小场景的影响,同时可以进一步提高网络的时间敏感性。我们对具有不同主干和不同预训练数据集的两个任务进行了实验,发现我们的方法优于SOTA方法,在使用同一主干的UCF101和HMDB51数据集上分别对动作识别任务分别有8.1%和8.8%的显着改进。
动机:问题很好
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' | ‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" | “Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash | – is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎














 1935
1935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









