







DeepRS(001)–FM模型理论与实践
FM背景
在传统的逻辑回归等相关变种模型中均认为特征是相互独立的,但是实际在很多情况下特征之间的依赖关系却是不可忽视的,因此需要进行特征交叉。在大多数业务场景下,类别特征做完 OneHot后会变得相当稀疏,尤其是在进行特征交叉后,特征空间变得很大。而 FM 可用于解决特征交叉下数据稀疏所带来的一系列问题。
one-hot困境
FM的主要目标是,解决在数据稀疏的情况下,特征怎样进行交叉的问题。以一个广告分类的问题为例,根据用户画像、广告场景特征以及其他特征,预测用户是否会点击广告(二分类问题)。用户数据如图所示

点击是标签,国家、日期、广告类型是特征。这3种特征都是离散类型,对离散特征,通常采用OneHot(独热)编码转换成数值型特征。

离散特征经过OneHot编码之后,其数据特征是非常稀疏的,所以OneHot编码会导致特征空间变大。例如,商品的类目有5000个,那么,一个商品类目的离散特征就会转换为5000维的数值特征,特征空间变大。当然,通过对特征进行二阶关联之后,关联特征与 Label 之间的相关性会提高。
FM模型
FM 模型就是引入了多项式回归模型来加入特征间的关联性的,通常对线性模型增加一个二阶多项式,其多项式模型的公式变为
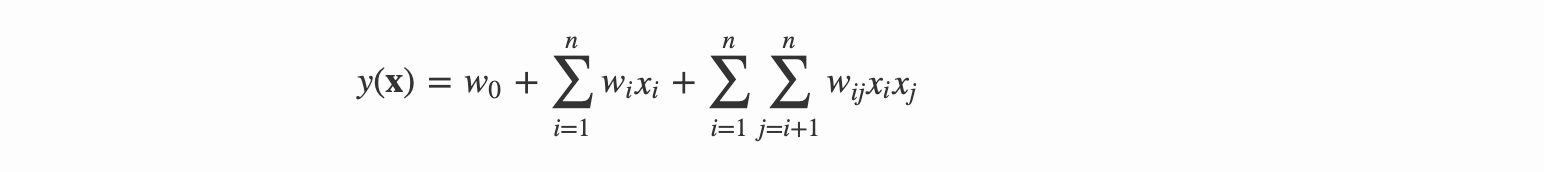
上述多项式模型的二阶特征的参数共有n(n-1)/2种,且任意参数间相互独立,并且在进行参数估计时发现,对于这些二次项的参数,都需要大量的非零样本来进行求解。但是很多时候特征空间是相当稀疏的,这种情况下参数的估计值变得相当不准确
为了解决上述特征矩阵稀疏带来的参数估计不准确的问题,FM 引入了矩阵分解的思路,对交叉项的系数矩阵进行了分解:Wi,j=<vi,vj>
上述矩阵分解的思想如下:由于特征之间不是相互独立的,因此可以使用一个隐因子来串联。这类似于在推荐算法中,可以将一个评分矩阵分解为用户矩阵和物品矩阵,每个用户和物品都可以用一个隐向量来表示。如图所示将一个用户表示成一个二维向量,同时把一个物品表示为一个二维向量,两个向量的点乘就是每个用户对每个物品的评分矩阵

FM中采用了类似的思想,将所有的二次项系数组成一个对称矩阵W,W可被分解为VTV,V的第j列即第j维特征的隐向量,因此FM模型可表示为如下这样。
根据V向量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qFdJ7Oi9-1589041623774)(evernotecid://CDCF9A4E-644D-4EF2-B63A-D5FE1415F62A/appyinxiangcom/18008202/ENResource/p16329)]](https://img-blog.csdnimg.cn/20200510002911376.png)
化简W矩阵:
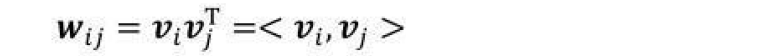
那么,FM公式如下:
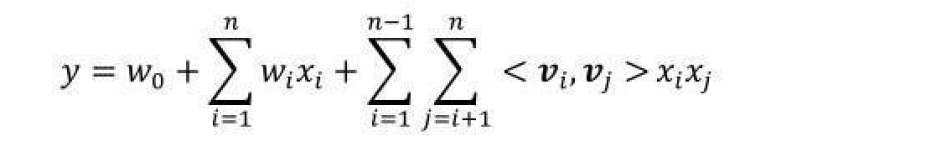
再进一步化简FM公式:

最终FM公式可以化简为
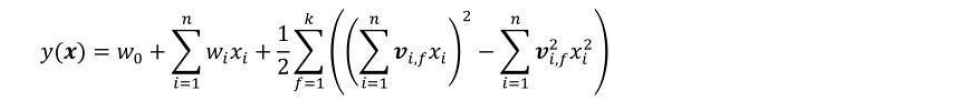
其中
v
i
,
f
x
i
{ v }_{ i,f }{ x }_{ i }
vi,fxi 为隐向量,通过隐向量相乘做特征交叉,极大的降低了向量空间大小,是参数量从
n
2
{ n }^{ 2 }
n2降低到
n
k
nk
nk, 且能更好的解决稀疏性问题,举例来说,我们有两个特征,分别是channel和brand,一个训练样本的feature组合是(ESPN, Adidas),在POLY2中,只有当ESPN和Adidas同时出现在一个训练样本中时,模型才能学到这个组合特征对应的权重。而在FM中,ESPN的隐向量也可以通过(ESPN, Gucci)这个样本学到,Adidas的隐向量也可以通过(NBC, Adidas)学到,这大大降低了模型对于数据稀疏性的要求。甚至对于一个从未出现过的特征组合(NBC, Gucci),由于模型之前已经分别学习过NBC和Gucci的隐向量,FM也具备了计算该特征组合权重的能力,这是POLY2无法实现的。也许FM相比POLY2丢失了某些信息的记忆能力,但是泛化能力大大提高,这对于互联网的数据特点是非常重要的。
FM的训练复杂度,利用SGD(Stochastic Gradient Descent)训练模型。模型各个参数的梯度如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wlMSfRSp-1589041623782)(evernotecid://CDCF9A4E-644D-4EF2-B63A-D5FE1415F62A/appyinxiangcom/18008202/ENResource/p16334)]](https://img-blog.csdnimg.cn/20200510003236588.png)
代码
# FM参数,生成或者获取W V
with tf.variable_scope("fm_layer", reuse=tf.AUTO_REUSE):
#一阶权重
self.FM_W = tf.get_variable(name='fm_w', shape=[self.feature_size, 1],initializer=tf.glorot_normal_initializer())
#隐向量
self.FM_V = tf.get_variable(name='fm_v', shape=[self.feature_size, self.fm_v_size], initializer=tf.glorot_normal_initializer())
self.FM_B = tf.Variable(tf.constant(0.0), dtype=tf.float32 ,name="fm_bias") # W0
# ---------- w * x----------
Y_first = tf.reduce_sum(tf.multiply(self.FM_W, dense_vector), 2) # None * F
# ---------- Vij * Vij* Xij ---------------
embeddings = tf.multiply(self.FM_V, dense_vector) # None * V * X
# sum_square part
summed_features_emb = tf.reduce_sum(embeddings, 1) # sum(v*x)
summed_features_emb_square = tf.square(summed_features_emb) # (sum(v*x))^2
# square_sum part
squared_features_emb = tf.square(embeddings) # (v*x)^2
squared_sum_features_emb = tf.reduce_sum(squared_features_emb, 1) # sum((v*x)^2)
# second order
Y_second = 0.5 * tf.subtract(summed_features_emb_square, squared_sum_features_emb) # 0.5*((sum(v*x))^2 - sum((v*x)^2))
# out = W * X + Vij * Vij* Xij
FM_out_lay1 = tf.concat([Y_first, Y_second], axis=1)
Y_Out = tf.reduce_sum(FM_out_lay1, 1)
# out = out + bias
y_d = tf.reshape(Y_Out,shape=[-1])
Y_bias = self.FM_B * tf.ones_like(y_d, dtype=tf.float32) # Y_bias
Y_Out = tf.add(Y_Out, Y_bias, name='Y_Out')
参考文献
- 推荐系统召回四模型之:全能的FM模型
- 黄美林:《推荐系统算法实践》
















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











