







项目简介
在上期博客中,给小伙伴们简单介绍了一下什么是爬虫,并且还讲解了配置环境的相关操作。
上期博客链接:https://blog.csdn.net/YCH0309/article/details/138588771#comments_32784223
这期就为小伙伴们详解一下代码
代码详解
废话不多说,直接上代码:
import re
import requests
import pandas as pd
hospitals = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203"
}
url = "https://www.yixue.com/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8C%BB%E9%99%A2%E5%88%97%E8%A1%A8"
response = requests.get(url, headers=headers)
html_content = response.text
pattern_div = r'<div class="mw-parser-output">(.*?)</div>'
matches = re.findall(pattern_div, html_content, re.S)
pattern = r'<li><b><a href=".+?" title="[^"]+">([^<]+)</a>\([^)]+\)</b>\s*<ul>' \
r'<li><b>医院地址</b>:(.+?)</li>\s*' \
r'(<li><b>联系电话</b>:(.+?)</li>)?\s*' \
r'(<li><b>医院等级</b>:(.+?)</li>)?\s*' \
r'(<li><b>重点科室</b>:(.+?)</li>)?\s*' \
r'(<li><b>经营方式</b>:(.+?)</li>)?\s*' \
r'(<li><b>传真号码</b>:(.+?)</li>)?\s*' \
r'(<li><b>电子邮箱</b>:(.+?)</li>)?'
for match in matches:
sub_html_content = match
sub_matches = re.findall(pattern, sub_html_content, re.S)
for sub_match in sub_matches:
name, address, _, phone, _, grade, _, keshi, _, mode, _,fax, _, email = sub_match
if not phone:
phone = "无"
if not grade:
grade = "无"
if not keshi:
keshi = "无"
if not mode:
mode = "无"
if not fax:
fax = "无"
if not email:
email = "无"
hospitals.append({
"医院名称": name,
"医院地址": address,
"联系电话": phone,
"医院等级": grade,
"重点科室": keshi,
"经营方式": mode,
"传真号码": fax,
"电子邮箱": email
})
df = pd.DataFrame(hospitals)
df["医院名称"] = df["医院名称"].str.replace("</a>", "")
df.to_excel("hospitals.xlsx", sheet_name="Sheet1", index=False)小伙伴可以直接将代码复制到自己所配置的环境中(配置环境在上一期模块中有详细介绍)
现在就为大家一一进行详解代码啦!
部分一:
import re
import requests
import pandas as pd第一部分当然是导入爬虫所需要的库了
import re 这个re的意思代表的是正则表达式,对文字进行匹配
import requests 直白来说 requests就是用来向HTML发送一个请求的
import pandas as pd pandas库是对数据进行处理,在本篇文章中起到的作用是对爬取的数据在Excel表格中对数据进行处理。
部分二:
hospitals = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203"
}
url = "https://www.yixue.com/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8C%BB%E9%99%A2%E5%88%97%E8%A1%A8"
response = requests.get(url, headers=headers)
html_content = response.text在第二部分呢,咱们为了小伙伴的思路更加清晰,每一行都会采用序号进行表示
空列表
1、hospitals = [] 定义了一个空列表,将爬取出来的数据储存到这个空列表中
User-Agent
2、headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203"}
这一部分代码十分的关键,那么这一块代码的目的是什么呢?
大家想一下,既然咱们想要从这个网站中进行爬取数据,那个人家这个网站上的人肯定是不乐意的,人家辛辛苦苦搜集来的数据,让你几秒就爬取完了,这是肯定不行的,所以在这里呢,就相当于设置了一个反爬虫的机制。
User Agent中文名为用户代理,简称 UA。这个UA去哪里找呢? 下面小伙伴们跟紧我的步伐!

进入官方医院链接以后,鼠标右键最下方有一个检查,点击进去以后可以出现上方的页面,在键盘中点击Ctrl+R
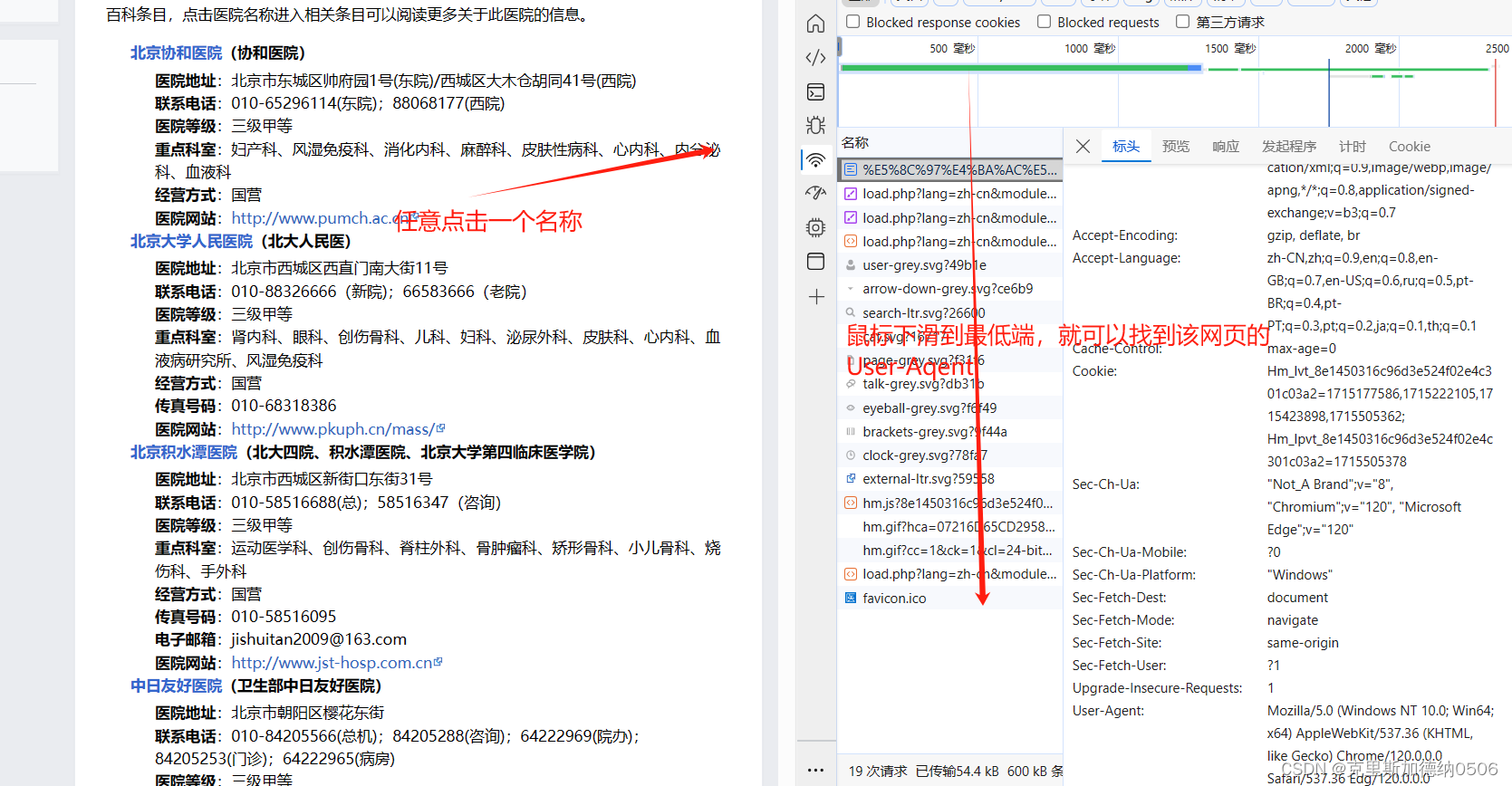
大家可以根据图片中的流程就行操作,找到网页对应的User-Agent,并且将其写入代码中即可。
可以将User-Agent抽象的理解成打开,所需要爬取网页的钥匙。有了这个钥匙以后就可以在该网页中进行爬取数据啦!
URL
3、url = "https://www.yixue.com/%E5%8C%97%E4%BA%AC%E5%B8%82%E5%8C%BB%E9%99%A2%E5%88%97%E8%A1%A8"
这个url放的就是咱们爬取官方医院数据的网址了。
向HTTP发送请求
4、response = requests.get(url, headers=headers)
在这个是对response变量进行赋值,使用requests.get()方法向指定的URL发送HTTP GET请求,获取网页的响应。要注意一点的就是,这个方法需要传入两个参数:URL和headers。
获取HTTP响应内容
5、html_content = response.text
使用response.text 方法对HTTP中的内容进行获取,并且将这个内容保存在html_content这个变量中。
到这里小伙伴是不是有一种这样的感觉:

相信大家一定行,静下心来,仔细的阅读这篇文章,发现爬虫也不难。
部分三:
pattern_div = r'<div class="mw-parser-output">(.*?)</div>'
matches = re.findall(pattern_div, html_content, re.S)从部分三就开始涉及到正则表达式这一部分了,在讲解完部分三以后,将会在下一个博客中对正则表达式进行一个详细的介绍。
1、pattern_div = r'<div class="mw-parser-output">(.*?)</div>'
为了大家方便理解这一行代码,我使用字体颜色,来体现代码结构
相信大家看到这行代码会有一点点的小懵,稍安勿躁,大家跟着我的思路走:
首先pattern_div就是一个变量名,没有什么好说的
r''是什么意思呢?
r'' 用于定义原始字符串,方便处理包含正则表达式模式的字符串。
看到这句话,是不是有点看不懂? 看不懂就对了,这是它的定义有点抽象,我给大家举一例子来说:
在正则表达式中经常会用到 \,但是如果你直接写在普通字符串中,Python 会将其解释为转义字符,而不是作为正则表达式中的特殊符号。为了避免这种情况,可以使用原始字符串,这样 \ 就会被当作普通字符处理,不会被解释为转义字符。
更加直白的可以理解成:加上r''以后呢,一些字符串的含义就发生了改变,更加适用于正则表达式进行一些相关的操作了
<div class="mw-parser-output">内容</div>

对于会前端的小伙伴看到这个东西,十分的熟悉吧 就是一个div框架,具体的HTML内容将会在下一篇博客中进行展示。
(.*?)
非贪婪模式 (.*?),表示匹配任意字符,但尽可能少地匹配,直到下一个模式被满足或者到达字符串结尾。(涉及到正则表达式的相关内容)
2、matches = re.findall(pattern_div,html_content, re.S)
首先是re.findall()函数 是 Python 中 re 模块 提供的一个函数,用于在字符串中查找所有匹配某个模式的子串,并以列表的形式返回所有匹配项。
pattern_div:要匹配的正则表达式模式
html_content: 要在其中查找匹配项的字符串(包含了原始 HTML 内容的字符串,你希望从这个字符串中提取匹配pattern_div 模式的部分。)
re.S的概念有点抽象,下面我将放一个简单的代码,方便大家理解:
import re
# 使用 re.S 标志匹配包括换行符在内的所有字符
text = "Hello\nWorld"
pattern = r'.+'
matches = re.findall(pattern, text, re.S)
print(matches) # 输出: ['Hello\nWorld']
# 没有使用 re.S 标志时,. 不能匹配换行符
matches_without_flags = re.findall(pattern, text)
print(matches_without_flags) # 输出: ['Hello']
也就是在说,大家今后在使用re.findall()这个函数的时候,都要在最后加上re.S这个参数。
最终matches这个变量中的内容为:mw-parser-output这个类中的所有文字
后续代码将会从这个变量中筛选出各个类别的有效信息
在下一章博客中,首先会对正则表达式和HTML基础框架进行一个简单的介绍后,再去讲解剩余的代码














 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









