






一、配置环境
- 要使用selenium去调用浏览器,还需要一个驱动,不同浏览器的驱动需要独立安装
selenium官网下载:https://www.selenium.dev/downloads/
Chrome浏览器驱动下载链接:https://npm.taobao.org/mirrors/chromedriver/ - 解压后是exe文件
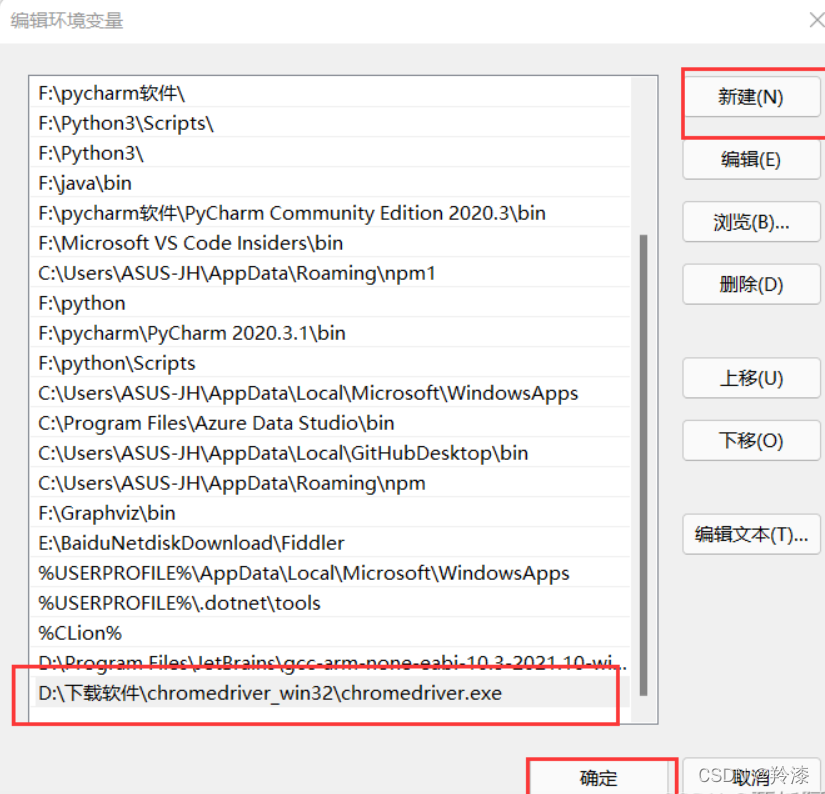
- 将该文件添加到环境变量PATH下
- 安装selenium
conda install selenium
pip install selenium
输入命令后输入y回车确认
- 安装webdriver_manager解决webdriver的管理问题
pip install webdriver_manager
conda install webdriver_manager
二、对百度进行自动化测试
- 打开浏览器,进入百度搜索界面
from selenium import webdriver
driver=webdriver.Chrome('D:\\下载软件\\chromedriver_win32\\chromedriver.exe')
#进入网页
driver.get("https://www.baidu.com/")
- 对百度页面右键检查或者点击电脑F12快捷键
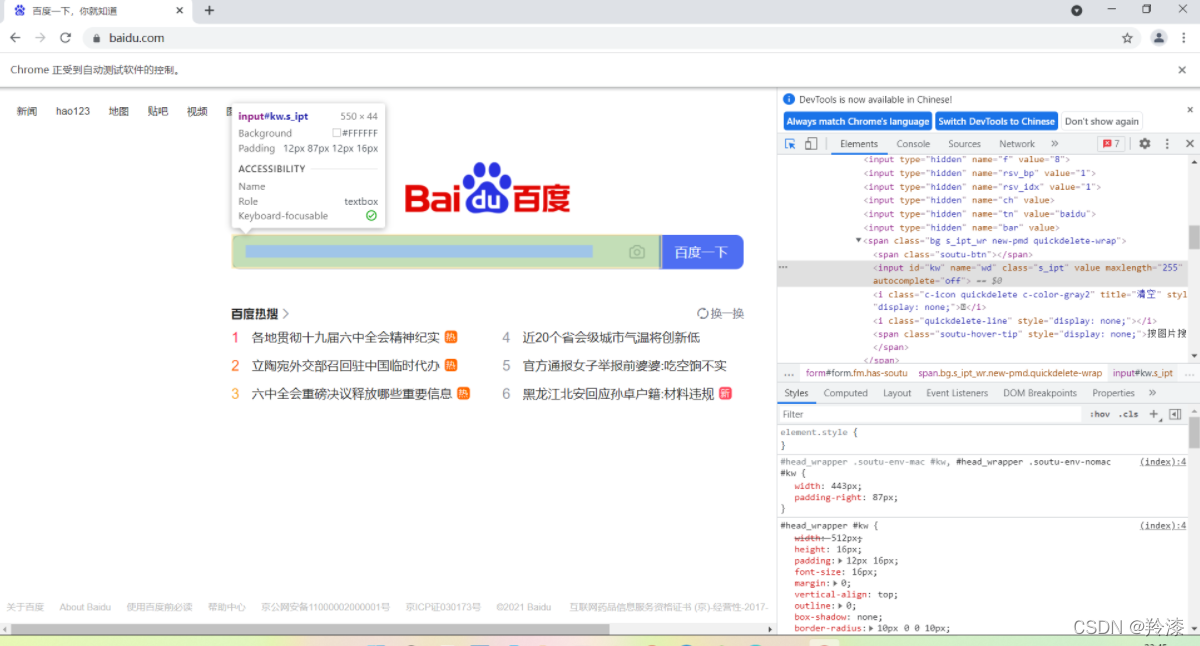
- 可以发现搜索框的id是kw
找到该元素,并填取对应的值
p_input = driver.find_element_by_id("kw")
p_input.send_keys('死妖阿')
- 同样检查网页找到按钮百度一下的id,为su
点击该按钮
p_btn=driver.find_element_by_id("su")
p_btn.click()
总结
完成了动态网页的信息爬取,就是爬取的速度比较慢,模拟人去点击网页,还是需要先找到相关元素。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









