







最近闲来无事,就想说捣鼓一下买来快吃灰一年的树莓派。在某宝花了30多大洋给树莓派装饰了一下。新买的东西总得试一下开始试试。。。
买了外壳、摄像头和麦克风。摄像头网上随便找个教程能拍照就OK了,接下来试下麦克风。
我买的麦克风长这样的,是免驱的,即插即用,方便快捷。网上也有教大家如何看麦克风驱动是否存在的命令这里我就不多收了

执行sudo arecord -D "plughw:1,0" -d 20 temp.wav录音20秒,之后生成一个文件temp.wav。这个音频文件需要用到播放器才能播放,所以安装omxplayer:sudo apt-get install omxplayer。安装完以后就可以播放录音文件了omxplayer -o local temp.wav就能播放本文件夹下的音频文件temp.wav。当你插上耳机认真听的时候你是很难听清的,可以说录音效果极其不佳,噪音特别大。因为你还需要再次配置一下麦克风。
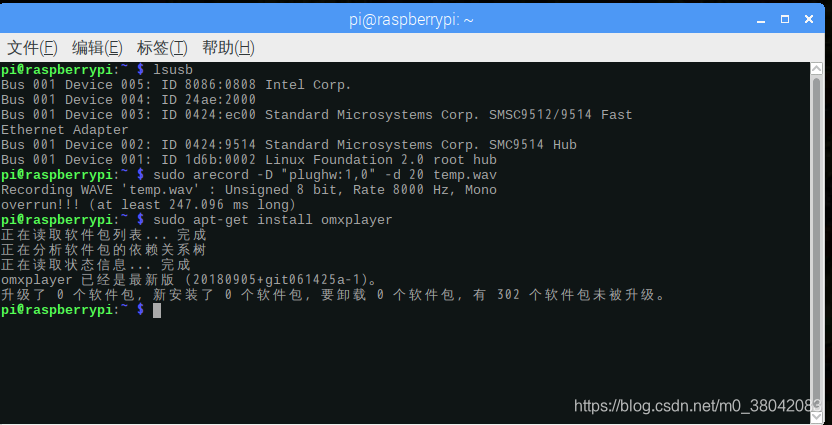
调节麦克风就比较简单了,看如下教程:
终端输入:alsamixer
就会出来如下界面,接下来按F6选择USB设备。
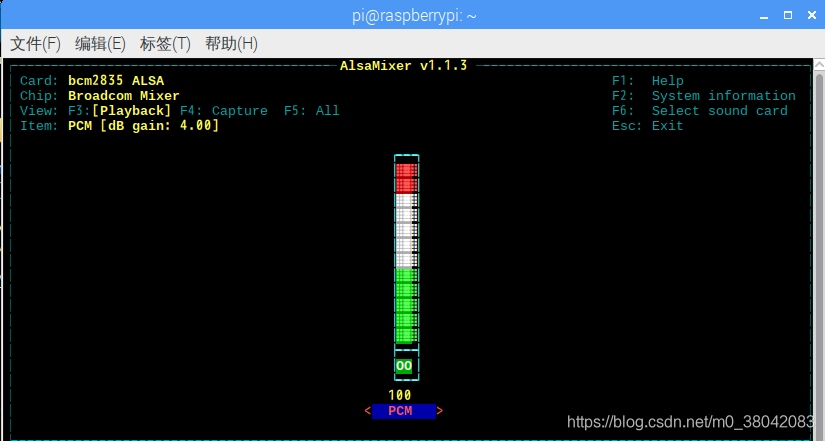
接下来按F5,选择ALL,就会出现下图:
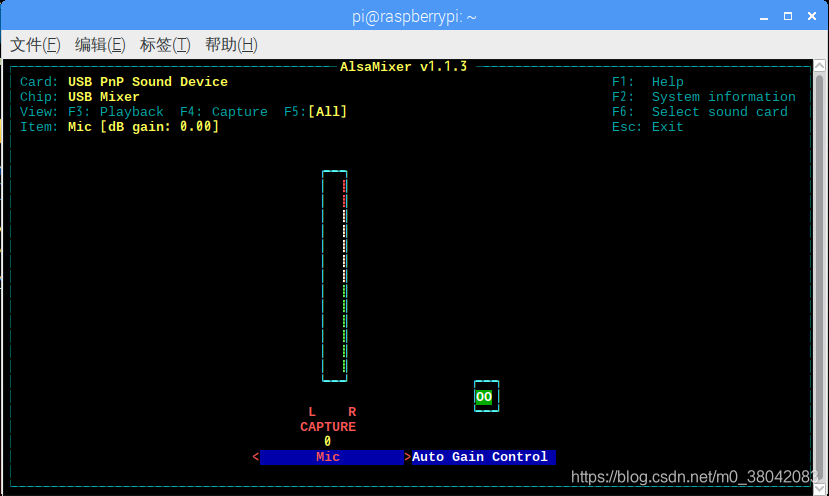
这个时候按键盘的↑调节CAPTURE应该是麦克风的增益,也可以按↓调小,将这个值调到最大如下图.
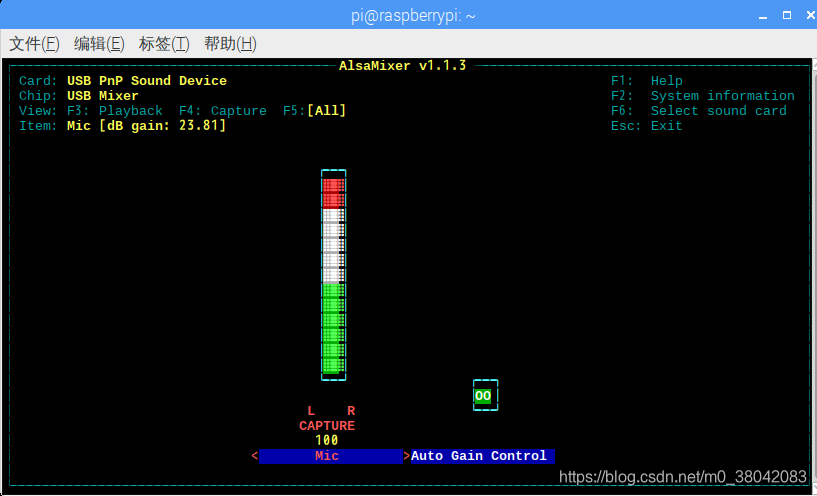
这个时候按ESC退出就可以了在执行录音的命令,听一下效果比没调节的时候好很多。
参考:
https://jingyan.baidu.com/article/fdbd4277a447ebb89e3f48ca.html
https://www.jianshu.com/p/2e8eed5070ed


















 8833
8833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











