









摘要:
本文旨在减少 Detection Transformer 类目标检测器对标注数据的依赖程度,提高其数据效率。
研究动机
目前的研究似乎表明 Detection Transformers 能够在性能、简洁性和通用性方面全面超越基于CNN的目标检测器。但我们研究发现只有在COCO这样训练数据丰富的数据集上 Detection Transformers 能够表现出性能上的优越,而当训练数据量较小时,大多数 Detection Transformers的性能会下降显著。这些发现表明 Detection Transformers 相比于基于CNN的目标检测器更加依赖标注数据(data hungry)。然而标注数据的获得并非易事,尤其是对于目标检测任务而言不仅需要标出多个物体的类别标签,还需要准确标出物体的定位框。同时,训练数据量大,意味着训练迭代次数多,因此训练需要消耗更多的算力。
消融探究
本文进行了一系列的模型转化实验来寻找影响 Data-efficiency 的关键因素。将 Data-efficient的RCNN逐步转化为 Data hungry的 Detection Transformers 检测器,来消融不同设计的影响。
模型转化中的关键步骤有:
- 去除 FPN;
- 加入 Transformer 编码器;
- 将动态卷积替换成自注意力机制;
- 去除RoIAlign;
- 去除初始的proposal。
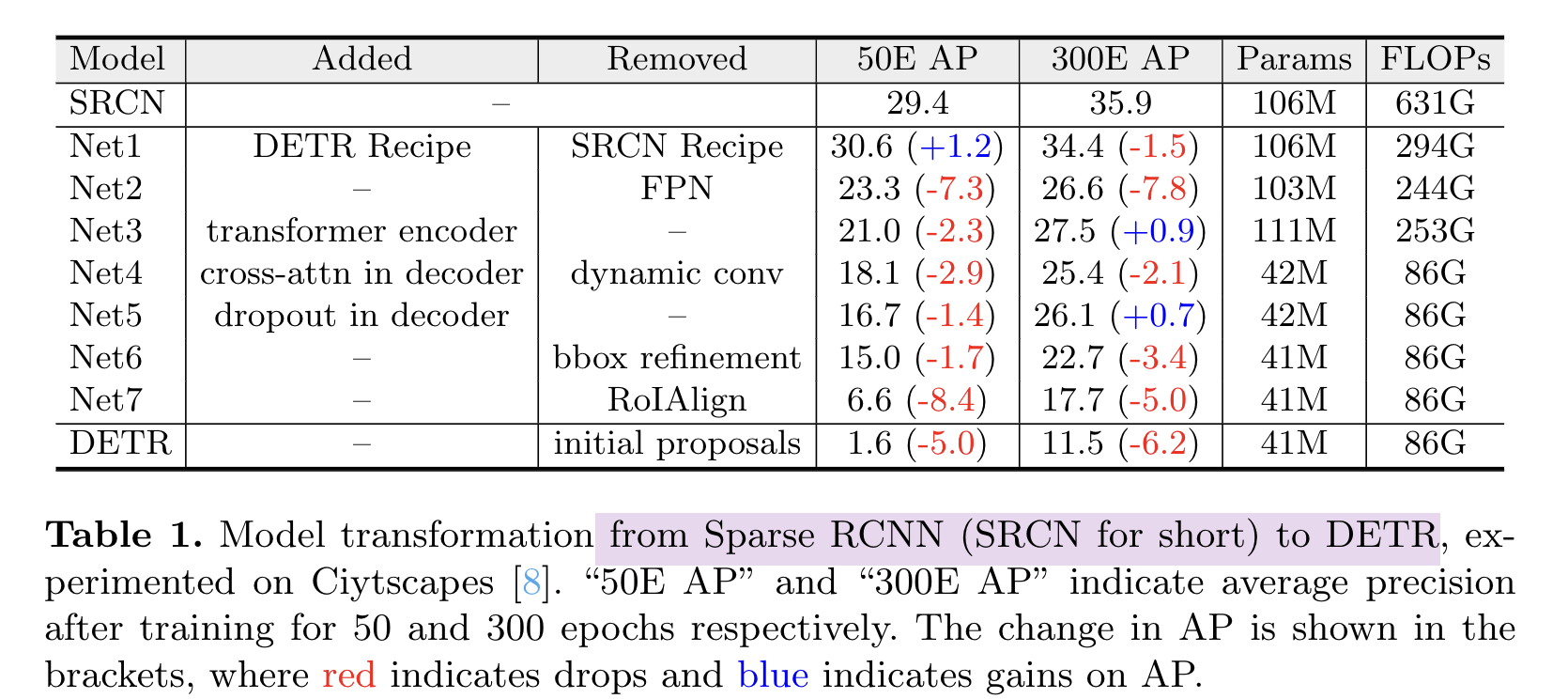
实验结果:
可以看出以下因素对模型的 data efficiency 具有关键作用。
- 从局部区域的稀疏特征采样,例如采用 RoIAlign;
- 多尺度特征融合,而这依赖于稀疏特征采样使得其运算量变得可接受;
- 相较于初始的空间位置先验作预测。
其中(1)和(3)有利于模型关注到特定的物体区域,缓解从大量数据中学习locality的困难。(2)有利于充分利用和增强图像的特征,但其也依赖于稀疏特征。
在DETR后续的改进工作中,Deformable DETR 也具有较好的数据效率。本文基于Sparse RCNN和DETR的模型转化实验得到的结论同样也能够说明为什么Deformable DETR的具有较好的数据集效率:Multi-scale Deformable Attention从图像局部区域内做特征的稀疏采样,并运用了多尺度特征,同时模型的预测是相对于初始的reference point的。
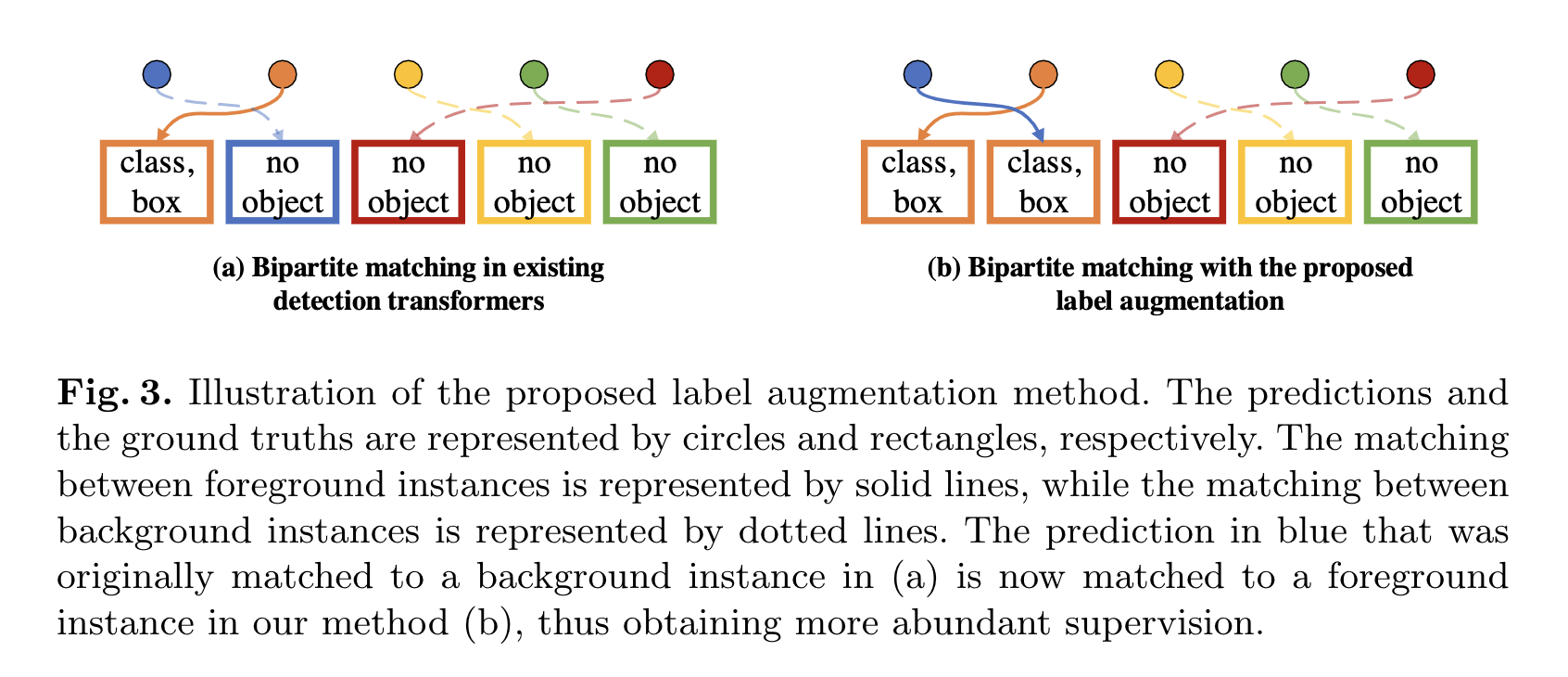
另外,作者提出了一种简单有效的标签增强(label augmentation)策略:通过在二分图匹配过程中重复正样本,来为Detection Transformer提供更丰富的监督信号。
Reference:
论文链接:https://arxiv.org/abs/2203.09507
作者解读链接:https://zhuanlan.zhihu.com/p/545435909
源码指路:https://github.com/encounter1997/DE-DETRs
A u t h o r : C h i e r Author: Chier Author:Chier















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









