









并查集的概念
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。
什么意思呢? 处理判断该某几个元素是否同在该集合上,以及两个不相交集合之间的一个合并的过程
简单来讲就是找祖宗和认祖宗的故事(对于我一晚上的个人理解,不喜勿喷)
还有一张江湖解说图如下:
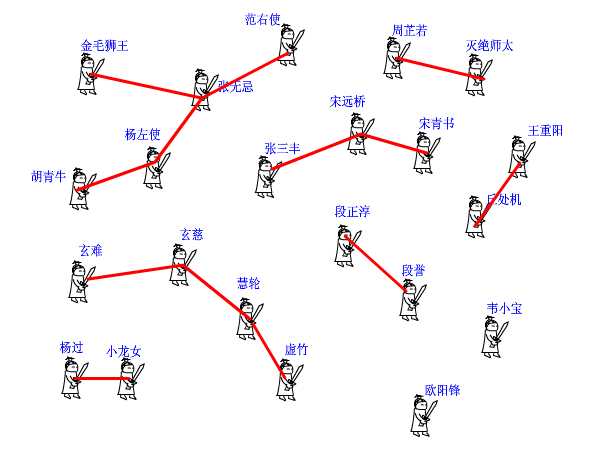
如果此时你想找到杨左使的管理者,就可以用并查集结构,如果你想让宋远桥归属到张无忌门派,就可以使用到并查集结构,那我来看下并查集的初始与结构是怎么样的
并查集的主要操作
构建并初始化并查集
初始化并查集结构,用上面图来说,就是先初始有多少个江湖人士,然后默认他们都是各自一派的管理员,代码如下:
class findUnionCollection{
private int[] s; // 江湖人数的数组集
int count; // 门派个数
// 构建江湖人士的数组集和门派个数
public findUnionCollection(int length){
s = new int[length];
s = initCollection(s);
count = length;
}
// 将每个江湖人士设置为各自一派的管理者(根节点默认为-1)
private int[] initCollection(int[] target){
for (int i =0;i<target.length;i++){
target[i]=-1;
}
return target;
}
}
有了各个门派的一个集合,此时我们应该也要有个可以找到每个门派的管理者一个查找方法
代码讲解:
public int find(int x){
// 当这个成员的所对应的值小于0,即为-1,则为门派的管理员,直接返回
if(s[x]<0){
return x;
}
// 如果不为0,则这个成员所对应的值是他的直接上层大佬
// 此时可以去递归这个大佬的大佬,直到找到最终的管理员
return find(s[x]);
}
当然,这里有个优化点,就是我们这边只是关心这个门派的管理员,而不关心这个门派的各个层次的关系,所以我们在查询的时候,可以将这层直接指引到管理员,方便下次直接查找,术语,简称路径压缩,代码如下:
public int find(int x){
// 当这个成员的所对应的值小于0,即为-1,则为门派的管理员,直接返回
if(s[x]<0){
return x;
}
// 如果不为0,则这个成员所对应的值是他的直接上层大佬
// 此时可以去递归这个大佬的大佬,直到找到最终的管理员
// 将各个门派的成员都指向最终管理员(实际就是路径压缩)
return s[x] = find(s[x]);
}
有了找祖宗的方法,当然也少不了认祖宗的方法,换江湖的说话,就是投靠另一门派
代码解析:
// 合并两个江湖人士所属门派
public void unionCollection(int child1,int child2){
// 先判断两个江湖人士是否所属一派,如果是,直接返回,无须合并
if(find(child1)==find(child2)){
return;
}
// 之后我们这个成员所属门派的管理员的深度进行对比
// 如果两个管理者的深度一样,就随机选一个管理员作为最终管理员,将加深其深度(减1)
// 如果child1的深度比child2的深度深,则将child2的管理员指向child1管理员
if(s[find(child1)]<s[find(child2)]){
s[find(child2)]=find(child1);
}else {
if(s[find(child1)]==s[find(child2)]){
s[find(child2)]--;
}
s[find(child1)]=find(child2);
}
由于每一次合并,都会减少一个门派,所以门派的数量也就递减
count--;
}
例题实战
题目描述
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。
示例 2:
输入:
[[1,1,0],
[1,1,1],
[0,1,1]]
输出: 1
说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。
注意:
N 在[1,200]的范围内。
对于所有学生,有M[i][i] = 1。
如果有M[i][j] = 1,则有M[j][i] = 1。
解题思路
1.先构建并初始一个长度为N的并查集数组,此时朋友圈的数量初始的长度
2.遍历M[][]二维数组,判断每个学生之间的关系是否为1,为1则调合并操作将两者关联起来,同时对朋友圈的数量递减
3遍历完则直接返回朋友圈的数量
3.代码实例:
class findUnionCollection{
private int[] s; // 江湖人数的数组集
int count; // 门派个数
// 构建江湖人士的数组集和门派个数
public findUnionCollection(int length){
s = new int[length];
s = initCollection(s);
count = length;
}
// 将每个江湖人士设置为各自一派的管理者(根节点默认为-1)
private int[] initCollection(int[] target){
for (int i =0;i<target.length;i++){
target[i]=-1;
}
return target;
}
public int find(int x){
// 当这个成员的所对应的值小于0,即为-1,则为门派的管理员,直接返回
if(s[x]<0){
return x;
}
// 如果不为0,则这个成员所对应的值是他的直接上层大佬
// 此时可以去递归这个大佬的大佬,直到找到最终的管理员
// 将各个门派的成员都指向最终管理员(实际就是路径压缩)
return s[x] = find(s[x]);
}
}
public void unionCollection(int child1,int child2){
// 先判断两个江湖人士是否所属一派,如果是,直接返回,无须合并
if(find(child1)==find(child2)){
return;
}
// 之后我们这个成员所属门派的管理员的深度进行对比
// 如果两个管理者的深度一样,就随机选一个管理员作为最终管理员,将加深其深度(减1)
// 如果child1的深度比child2的深度深,则将child2的管理员指向child1管理员
if(s[find(child1)]<s[find(child2)]){
s[find(child2)]=find(child1);
}else {
if(s[find(child1)]==s[find(child2)]){
s[find(child2)]--;
}
s[find(child1)]=find(child2);
}
由于每一次合并,都会减少一个门派,所以门派的数量也就递减
count--;
}
class Solution {
public Solution(){
}
public static int findCircleNum(int[][] M) {
int studentNums = M[0].length;
findUnionCollection FUC = new findUnionCollection(studentNums);
for(int i=0;i<studentNums-1;i++){
for(int j = i+1; j<M[i].length;j++){
if(M[i][j]==1){
FUC.unionCollection(i,j);
}
}
}
return FUC.getCount();
}
public static void main(String[] var0) {
int[][] M = new int[][]{{1,1,0},{1,1,0},{0,0,1}};
System.out.println("findUnionCollection:"+findCircleNum(M));
}
}















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









