







 本文详细介绍了机器学习中的评价函数,包括分类任务的准确率、精确率、召回率、F1分数、混淆矩阵等,以及回归任务的MAE、MSE、RMSE和决定系数。同时涵盖了聚类任务的内部指标和外部指标,如轮廓系数和兰德系数。此外,还区分了目标函数、损失函数和代价函数的概念及其在优化过程中的作用。
本文详细介绍了机器学习中的评价函数,包括分类任务的准确率、精确率、召回率、F1分数、混淆矩阵等,以及回归任务的MAE、MSE、RMSE和决定系数。同时涵盖了聚类任务的内部指标和外部指标,如轮廓系数和兰德系数。此外,还区分了目标函数、损失函数和代价函数的概念及其在优化过程中的作用。
总结
本系列是机器学习课程的系列课程,主要介绍机器学习中分类回归和聚类算法中的评价函数。
参考
Python sklearn机器学习各种评价指标——Sklearn.metrics简介及应用示例
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

机器学习常见评价指标

“没有测量,就没有科学。”——门捷列夫
在计算机科学特别是机器学习领域中,对模型的评估同样至关重要。只有选择与问题相匹配的评估方法,才能快速地发现模型选择或训练过程中出现的问题,迭代地对模型进行优化。
本篇文章就给大家分享一下分类和回归模型中常用地评价指标,希望对大家有帮助。
📌 分类模型
① 准确率和错误率
② 混淆矩阵
③ 精确率(查准率)Precision
④ 召回率(查全率)Recall
⑤ F1-Score
⑥ P-R曲线
⑦ ROC曲线
⑧ AUC
⑨ KS曲线
📌 回归模型
① 平均绝对误差(MAE)
② 均方误差(MSE)
③ 均方根误差(RMSE)
④ 决定系数R^2
⑤ 可解释变异
分类任务
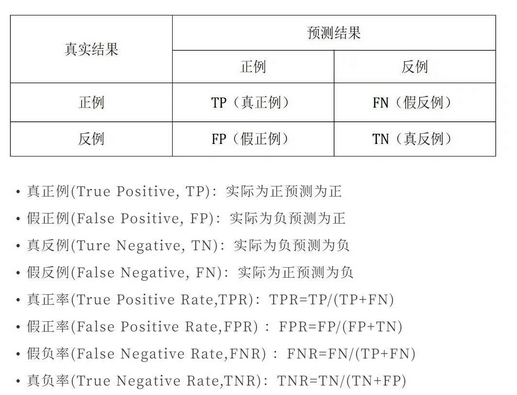
混淆矩阵
在机器学习领域,混淆矩阵(ConfusionMatrix),又称为可能性矩阵或错误矩阵。混淆矩阵的每一列代表了预测类别,每一行代表了数据的真实类别。分类问题的评价指标大多基于混淆矩阵计算得到的。

准确率(Accuracy)
识别对了的正例(TP)与负例(TN)占总识别样本的比例。
缺点:类别比例不均衡时影响评价效果。
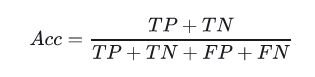

精确率(Precision)
识别正确的正例(TP)占识别结果为正例(TP+FP)的比例。

召回率(Recall)
识别正确的正例(TP)占实际为正例(TP+FN)的比例。

通常在排序问题中,采用Top N返回结果的精确率和召回率来衡量排序模型的性能,表示为Precision@N
和Recall@N。
Precision和Recall是一对矛盾又统一的指标,当分类阈值越高时,模型的精确率越高,相反召回率越低。
F1值

F1是召回率R和精度P的加权调和平均,顾名思义即是为了调和召回率R和精度P之间增减反向的矛盾,对R和P进行加权调和。

P-R曲线
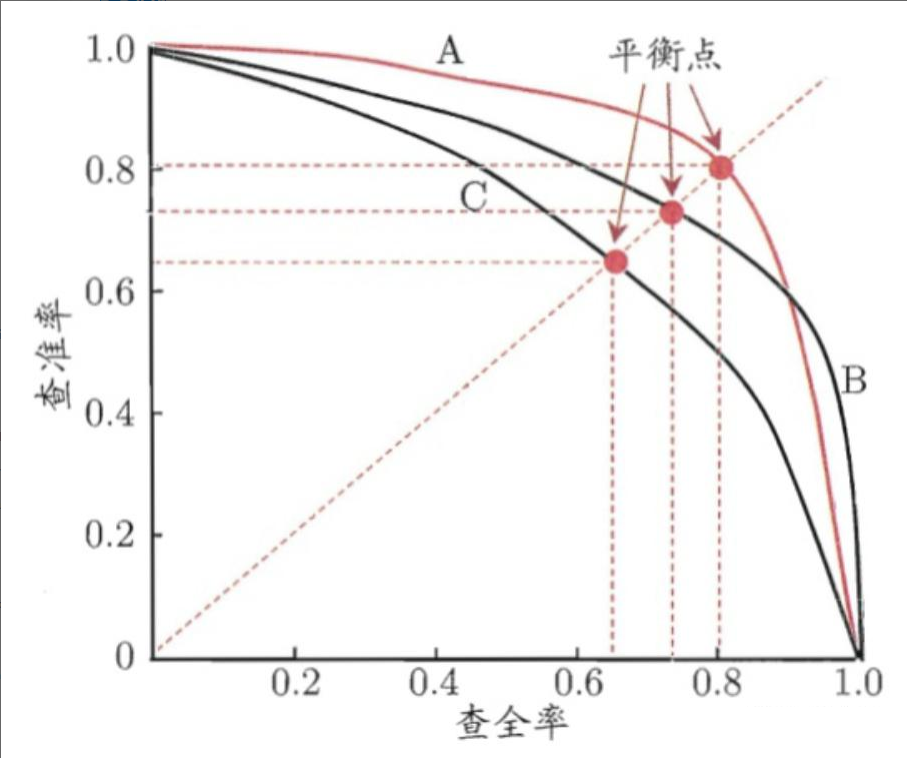
PR曲线通过取不同的分类阈值,分别计算当前阈值下的模型P值和R值,以P值为纵坐标,R值为横坐标,将算得的一组P值和R值画到坐标上,就可以得到P-R曲线。当一个模型的P-R曲线完全包住另一个模型的P-R曲线,则前者的性能优于后者(如A>C,B>C)。

ROC(Receiver Operating Characteristic)
ROC曲线也称受试者工作特征。以FPR(假正例率:假正例占所有负例的比例)为横轴,TPR(召回率)为纵轴,绘制得到的曲线就是ROC曲线。与PR曲线相同,曲线下方面积越大,其模型性能越好。
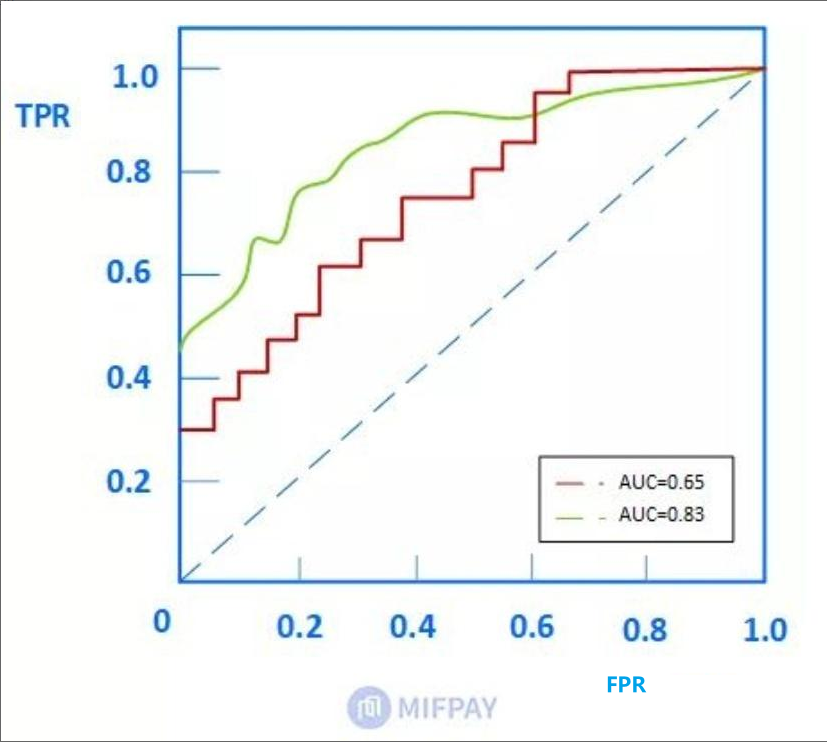
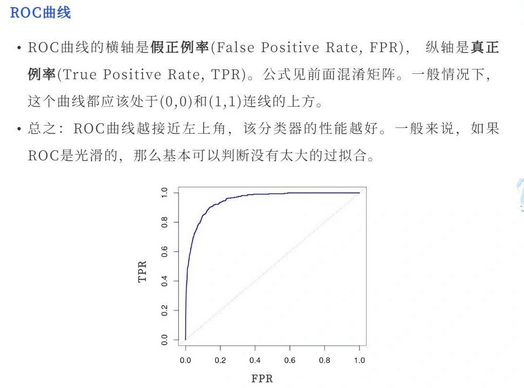
AUC
含义一:ROC曲线下的面积即为AUC。面积越大代表模型的分类性能越好。
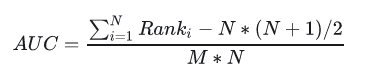

含义二:随机挑选一个正样本以及负样本,算法将正样本排在所有负样本前面的概率就是AUC值。 是排序模型中最为常见的评价指标之一。
M代表数据集中正样本的数量,N代表负样本数量。AUC的评价效果不受正负样本比例的影响。因为改变正负样本比例,AOC曲线中的横纵坐标大小同时变化,整体面积不变。
KS曲线
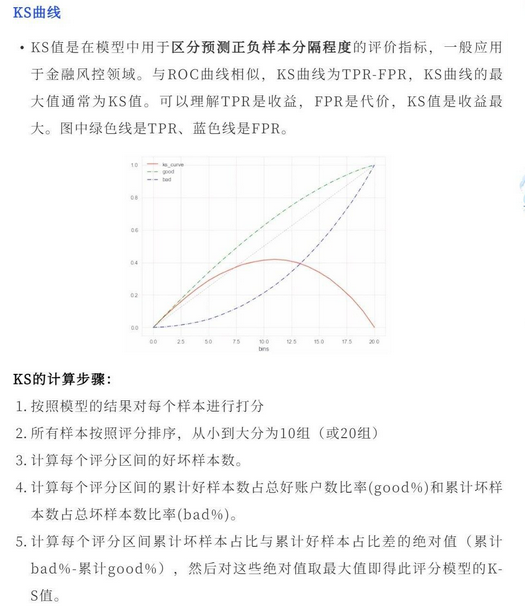
sklearn实现分类评价
sklearn.metrics 是 scikit-learn 库中的一个模块,它提供了许多用于评估预测模型性能的指标和工具。这些指标和工具可以帮助你了解模型在训练集和测试集上的表现,以及模型是否能够很好地泛化到未见过的数据。
以下是一些 sklearn.metrics 中常用的函数和指标:
- 分类指标:
accuracy_score: 计算分类准确率。classification_report: 显示主要分类指标的文本报告,包括精确度、召回率、F1 分数等。confusion_matrix: 计算混淆矩阵,用于评估分类模型的性能。precision_score: 计算精确度。recall_score: 计算召回率。f1_score: 计算 F1 分数(精确度和召回率的调和平均数)。roc_auc_score: 计算接收者操作特性(ROC)曲线下的面积(AUC)。
回归任务
MAE(Mean Absolute Error)
MAE是平均绝对误差,又称L1范数损失。通过计算预测值和真实值之间的距离的绝对值的均值,来衡量预测值与真实值之间的真实距离。
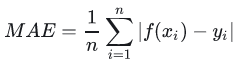

MSE(Mean Square Error)
MSE是真实值与预测值的差值的平方然后求和平均。通过平方的形式便于求导,所以常被用作线性回归的损失函数。
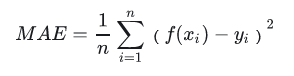

RMSE(Root Mean Square Error)
RMSE衡量观测值与真实值之间的偏差。常用来作为机器学习模型预测结果衡量的标准。 受异常点影响较大,鲁棒性比较差。
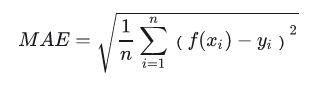

决定系数

可解释变异

sklearn实现回归
回归指标:
mean_squared_error: 计算均方误差(MSE)。mean_absolute_error: 计算平均绝对误差(MAE)。r2_score: 计算 R² 分数,即决定系数。
排序任务
AUC
同上。AUC不受数据的正负样本比例影响,可以准确的衡量模型的排序能力,是推荐算法、分类算法常用的模型评价指标。
MAP(Mean Average Precision)
全局平均准确率,其中AP表示单用户TopN推荐结果的平均准确率。
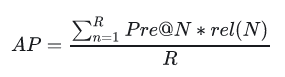
这里R表示推荐的结果序列长度,rel(N)表示第N个推荐结果的相关性分数,这里命中为1,未命中为0。AP衡量的是整个排序的平均质量。对全局所有用户的AP取平均值就是MAP。
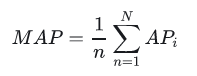
NDCG
首先介绍CG(累计收益),模型会给推荐的每个item打分表示与当前用户的相关性。假设当前推荐item的个数为N个,我们把这N个item的相关分数进行累加,就是当前用户的累积增益:
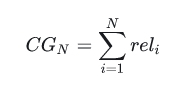
显然CG不考虑不同位置对排序效果的影响,所以在此基础上引入位置影响因素,即DCG(折损累计增益),位置靠后的结果进行加权处理:
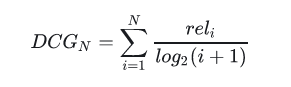
推荐结果的相关性越大,DCG越大,推荐效果越好。
NDCG(归一化折损累计增益),表示推荐系统对所有用户推荐结果DCG的一个平均值,由于每个用户的排序列表不一样,所以先对每个用户的DCG进行归一化,再求平均。其归一化时使用的分母就是IDCG,指推荐系统为某一用户返回的最好推荐结果列表,即假设返回结果按照相关性排序,最相关的结果放在前面,此序列的DCG为IDCG。
MRR(Mean Reciprocal Rank)
MRR平均倒数排名,是一个国际上通用的对搜索算法进行评价的机制,即第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
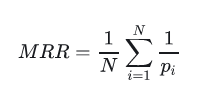
聚类任务
聚类任务的评价指标分为内部指标(无监督数据)和外部指标(有监督数据)。
内部指标(无监督数据,利用样本数据与聚类中心之间的距离评价):
紧密度(Compactness)
每个聚类簇中的样本点到聚类中心的平均距离。紧密度越小,表示簇内的样本点越集中,样本点之间聚类越短,也就是说簇内相似度越高。
分割度(Seperation)
每个簇的簇心之间的平均距离。分割度值越大说明簇间间隔越远,分类效果越好,即簇间相似度越低。
轮廓系数 (Silhouette Coefficient)
对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。轮廓系数的取值范围是[-1,1],同类别样本距离越相近,不同类别样本距离越远分数越高。假设:
a:某个样本与其所在簇内其他样本的平均距离
b:某个样本与其他簇样本的平均距离
单个样本的轮廓系数s为:
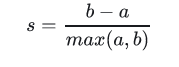 聚类的总体轮廓系数为:
聚类的总体轮廓系数为:
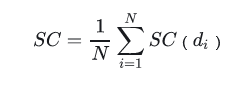
外部指标(有监督数据,利用样本数据与真实label进行比较评价):
兰德系数(Rand index)
兰德系数是使用真实label对聚类效果进行评估,评估过程和混淆矩阵的计算类似:

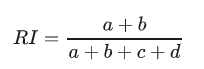
互信息(Mutual Information)
sklearn实现聚类
聚类指标:
silhouette_score: 计算轮廓系数,用于评估聚类效果。calinski_harabasz_score: 计算 Calinski-Harabasz 指数,用于评估聚类效果。 -davies_bouldin_score: 计算 Davies-Bouldin 指数,用于评估聚类效果。
目标函数、损失函数、代价函数、评价函数区别
在机器学习和优化问题中,目标函数、损失函数、代价函数都是评估和优化模型的关键概念,它们之间既有联系又有区别:
-
损失函数(Loss Function):
- 描述了一个模型对于单个样本预测输出与真实值之间的差异。损失函数通常是非负的,并且理想情况下,在预测完全准确时其值为零。
- 举例:在二元分类问题中,常用的损失函数包括逻辑回归的对数损失(Log Loss, Binary Cross-Entropy Loss),它量化了模型预测的概率分布与实际标签之间的距离。
-
代价函数(Cost Function):
- 在机器学习中,特别是在监督学习场景下,代价函数指的是在整个训练集上的损失函数的平均值,即所有样本损失之和的平均,用来衡量模型在所有训练数据上的整体表现。
- 举例:假设我们在做线性回归,使用的损失函数可能是每个样本的平方误差,代价函数则是所有样本平方误差之和除以样本数量,即均方误差(Mean Squared Error, MSE)。
-
目标函数(Objective Function):
- 目标函数是模型优化过程中试图最小化的函数,它不仅包含训练误差的部分(如代价函数),还可能包含正则化项(Regularization Term),旨在控制模型复杂度,防止过拟合。
- 举例:在线性回归中,目标函数可能是代价函数加上L1或L2正则化项,如岭回归(Ridge Regression)的目标函数是在MSE的基础上添加了权重向量的L2范数惩罚项。
总结一下:
- 损失函数关注单个数据点的预测误差;
- 代价函数是损失函数在训练集上的平均,反映了模型在所有训练数据上的总体性能;
- 目标函数进一步扩展了代价函数的概念,包含了对模型复杂性的惩罚项,体现了模型泛化能力的考量。
在不同的文献和上下文中,有时人们会互换使用“代价函数”和“损失函数”的说法,尤其是在只考虑训练误差而不涉及正则化时。而在正则化存在的情况下,目标函数则明确包含了正则化项,是优化过程中真正要最小化的目标。
- 评价函数:
损失函数是用来衡量预测值和真实值差距的函数,是模型优化的目标,所以也称之目标函数、优化评分函数。这是机器学习中很重要的性能衡量指标。
评价函数和损失函数相似,只是关注点不同:
损失函数用于训练过程,
而评价函数用于模型训练完成后(或每一批次训练完成后)的度量,
确定方向过程
针对完全没有基础的同学们
1.确定机器学习的应用领域有哪些
2.查找机器学习的算法应用有哪些
3.确定想要研究的领域极其对应的算法
4.通过招聘网站和论文等确定具体的技术
5.了解业务流程,查找数据
6.复现经典算法
7.持续优化,并尝试与对应企业人员沟通心得
8.企业给出反馈
















 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











