







论文背景
传统的 Transformer 模型因为有 self-attention 的缘故,所以它的时间和空间复杂度都是
O
(
n
2
)
O(n^2)
O(n2),
n
n
n是输入序列的长度。为了解决这个问题,作者提出Longformer模型。
相关工作
对于Long-document Transformers,目前已经有了一些研究,这些研究提出了两种方法:第一种是left-to-right(ltr)方法,但是它只能处理自回归语言模型,不能处理迁移学习。本文的工作属于另一种方法:稀疏注意力模式(sparse attention pattern)。
背景知识
小cue一下:
- local attention build contextual representations
- global attention allows transformer to build full sequence representations for prediction
Longformer模型部分
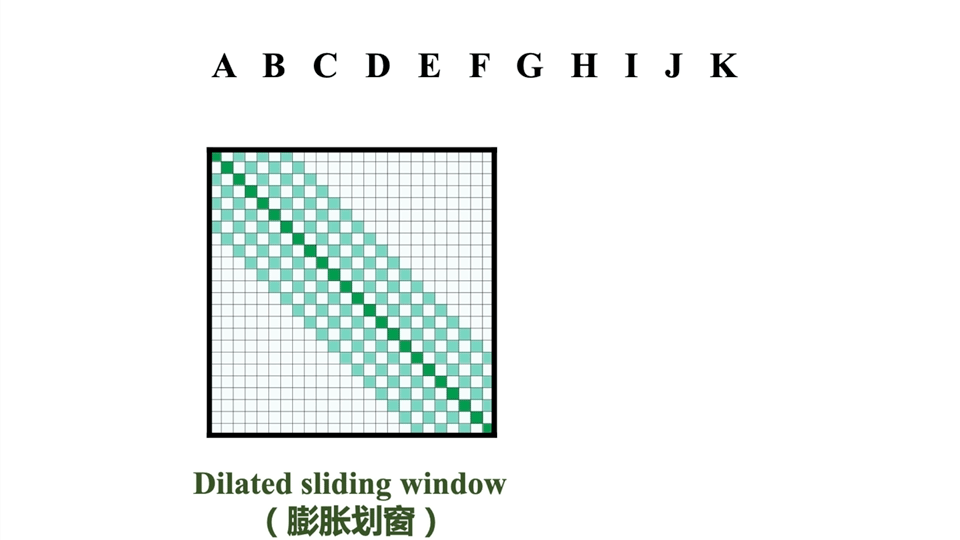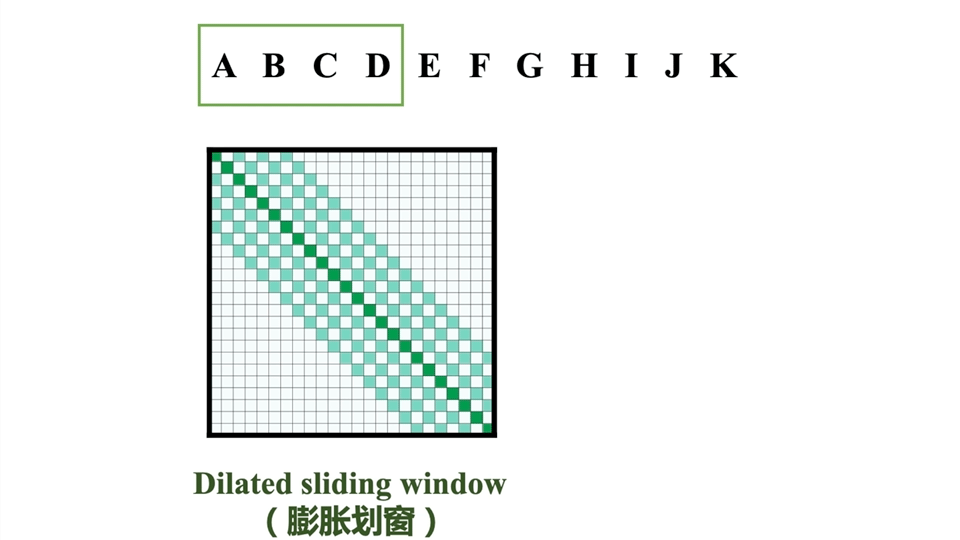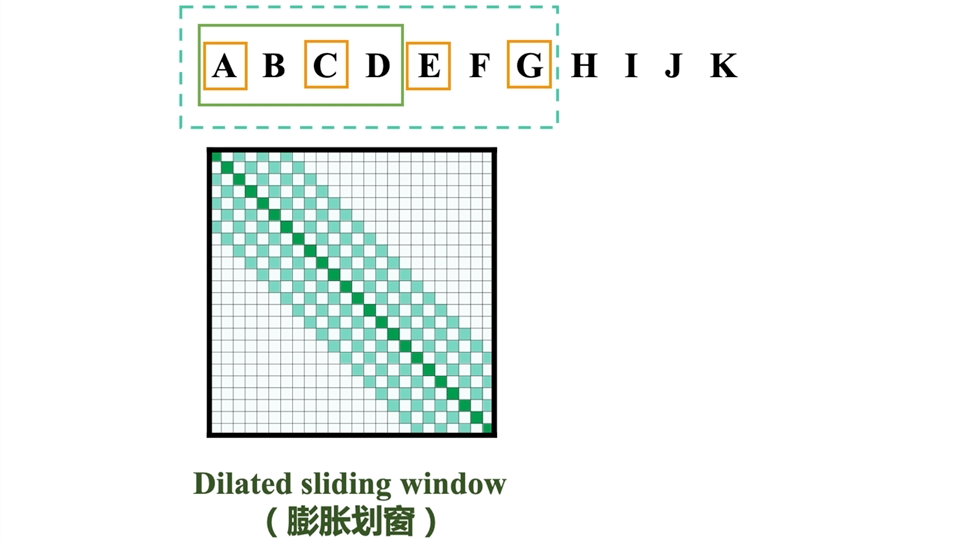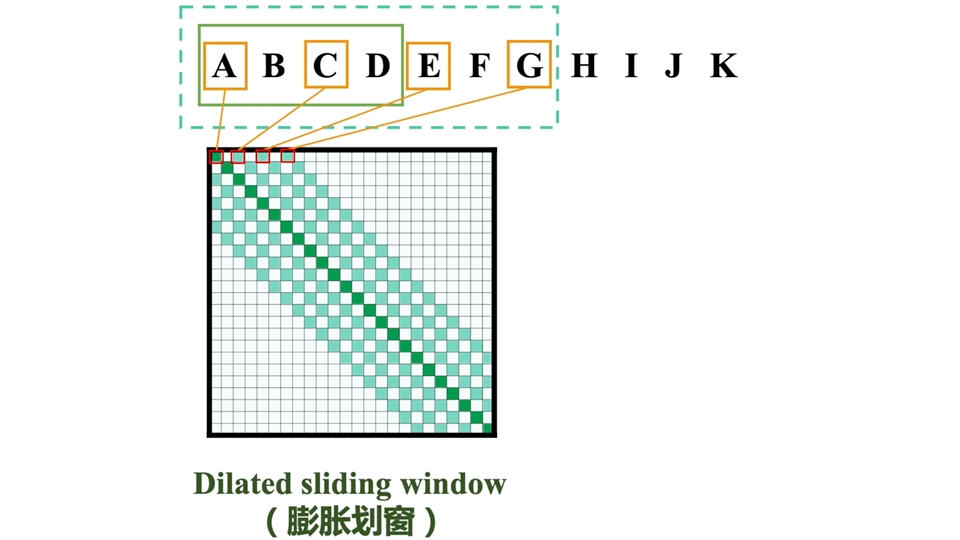
针对attention patten提出了三种改进方式:滑动窗口(sliding window)、Dilated sliding window、global+sliding window,如下图所示

图中深绿色面积代表Query的数量,浅绿色面积代表Query需要关注的Key的数量
- 滑动窗口(sliding window)
对于每一个token,只对其附近的w个token计算attention,复杂度为 O ( n × w ) O ( n × w ) O(n×w)其中 n为文本的长度。作者认为,根据应用任务的不同,可以对Transformer每一层施以不同的窗口大小 w。
实验中:
如果transformer的不同层采用不同窗口大小,是否可以提高性能?
实验结果表明,由底层至高层递增窗口大小,可提升性能;递减则反而性能降低。

- Dilated sliding window(maybe叫膨胀滑窗,感觉像是一种跳跃式的滑窗)
在对每一个进行token编码时,普通滑窗机制只能考虑到长度为w的上下文。作者进一步提出膨胀滑窗机制,在不增加计算负荷的前提下,拓宽模型“视野”。其做法借鉴了空洞卷积(dilated CNN)的思想。如下图所示,在滑动窗口中,被attend到的两个相邻token之间会存在大小为d的间隙。当transformer的层数为l时,则视场范围可达到 l ∗ d ∗ w l*d*w l∗d∗w ,就像下动图中第7行及之后一样 。实验表明,由于考虑了更加全面的上下文信息,膨胀滑窗机制比普通的滑窗机制表现更佳。
- 全局+滑动窗口(global+sliding window)
Bert
应用于具体任务时,实现方式略有不同:
对于文本分类任务,会在文本序列前添加[CLS]这一特殊token;
而对于QA类任务,则会将问题与文本进行拼接后输入。
Longformer
作者也希望能够根据具体任务的不同,在local attention的基础上添加少量的global attention。
比如,在分类任务上就会在[CLS]处添加一个global attention
而在QA任务上会对question中的所有token添加global attention。
对于添加了global attention的token,对其编码时要对整个序列做attention。并且,编码其他所有token时,也要attention。
















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









