






一、引言
在数据处理和机器学习领域,数据的维度常常是一个需要解决的关键问题。高维度数据可能会带来诸如计算成本高、模型复杂度增加以及过拟合等诸多问题。降维技术就是为了解决这些问题而出现的,其中主成分分析(PCA)和线性判别分析(LDA)是两种非常重要的降维方法。

二、PCA(主成分分析)的原理
(一)寻找数据变化的主要方向
PCA 的核心思想是在高维数据空间中找到能够最大程度地保留数据方差的方向。想象我们有一组二维数据点(例如平面上的许多点),这些点分布在一个倾斜的椭圆区域内。PCA 试图找到这个椭圆的长轴和短轴方向。长轴方向是数据变化最大的方向,也就是第一主成分,而短轴方向是与长轴垂直且数据变化次大的方向,即第二主成分。
从直观上理解,主成分就是数据的 “主要轮廓”。在更高维度的数据中,PCA 会依次找到数据变化最大、次大等方向,将数据投影到这些方向构成的新空间中,从而实现降维。
(二)数据协方差矩阵的作用
为了找到这些主要方向,PCA 利用了数据的协方差矩阵。协方差矩阵描述了数据各个维度之间的相关性。如果两个维度之间的协方差为正,说明它们倾向于同时增大或减小;如果协方差为负,则一个维度增大时另一个维度倾向于减小。通过对协方差矩阵进行特征分解,PCA 可以获取特征值和特征向量。特征值表示对应特征向量方向上数据的方差大小,而特征向量就是我们要找的主成分方向。
(三)数据投影实现降维
一旦确定了主成分方向(特征向量),就可以将原始数据点投影到这些主成分方向上。例如,如果我们选择保留前 k 个主成分,就将数据从原始的高维空间投影到由这 k 个主成分构成的 k 维子空间中。这个投影过程实际上是通过计算原始数据点与主成分方向的内积来实现的,从而将高维数据转换为低维数据表示。
三、LDA(线性判别分析)的原理
(一)基于类别可分性的降维
LDA 的目标是找到一个投影方向,使得不同类别数据在投影后的空间中尽可能地分开,同时同一类别数据的内聚性尽可能高。与 PCA 主要关注数据的方差不同,LDA 更侧重于类别之间的区分。
假设我们有两类数据,分别用不同颜色的点表示在二维平面上。LDA 试图找到一条直线,当把数据点投影到这条直线上时,两类数据的投影点之间的间隔尽可能大,并且每类数据投影后的分布尽可能紧凑。
(二)类间散度和类内散度
为了实现这个目标,LDA 使用了类间散度矩阵(![]() )和类内散度矩阵(
)和类内散度矩阵(![]() )的概念。类间散度矩阵衡量了不同类别中心之间的距离,它表示了类别之间的分离程度。类内散度矩阵则衡量了每个类别内部数据的分散程度。LDA 的目标是最大化类间散度与类内散度的比值(
)的概念。类间散度矩阵衡量了不同类别中心之间的距离,它表示了类别之间的分离程度。类内散度矩阵则衡量了每个类别内部数据的分散程度。LDA 的目标是最大化类间散度与类内散度的比值(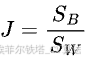 ),通过求解这个优化问题来找到最佳的投影方向。
),通过求解这个优化问题来找到最佳的投影方向。
(三)投影实现降维
当找到最佳投影方向(通过求解广义特征值问题得到)后,就可以将原始数据投影到这个方向上,从而将高维数据转换为低维数据。在多类别情况下,LDA 可能会找到多个投影方向来区分不同的类别,这些投影方向构成的子空间用于数据的降维。
四、PCA 和 LDA 的区别
(一)目标不同
- PCA:主要目标是在数据空间中找到数据变化最大的方向,以最大程度地保留数据的方差。它是一种无监督的降维方法,不考虑数据的类别标签,只是关注数据本身的分布特性。
- LDA:以分类为导向,目的是找到能够使不同类别数据之间的区分度最大的投影方向。它是一种有监督的降维方法,需要利用数据的类别标签来进行降维操作。
(二)适用的数据类型
- PCA:适用于数据没有类别标签或者不需要考虑类别信息的情况。例如,在对图像进行特征提取时,如果只是想减少图像数据的维度而不涉及图像的分类,PCA 可能是一个很好的选择。
- LDA:在有明确类别标签的分类问题中表现出色。比如在人脸识别中,不同人的脸属于不同的类别,LDA 可以通过找到区分不同人脸类别的投影方向来进行降维和分类。
(三)对数据分布的假设
- PCA:假设数据是在高维空间中呈椭圆形分布(更准确地说是高斯分布),并且希望找到这个椭圆的主轴方向。它主要关注数据的全局结构,对数据中的噪声比较敏感。
- LDA:假设每个类别内部的数据服从高斯分布,并且不同类别之间的高斯分布具有不同的均值。它更侧重于类别之间的差异,对于类别内部的数据分布变化相对不太敏感,只要类别之间的区分度能够得到保持。
(四)降维后的结果
- PCA:降维后的结果是数据在方差最大方向上的投影,新的维度(主成分)是按照数据方差大小排序的。这些主成分可能并不直接对应于任何实际的物理或语义特征,但它们能够有效地表示数据的主要变化趋势。
- LDA:降维后的维度具有明确的类别区分意义,即每个维度都有助于最大程度地分离不同类别。这使得 LDA 降维后的结果在分类任务中更具有可解释性。
五、PCA 和 LDA 的应用场景
(一)PCA 的应用场景
- 数据可视化
- 在高维数据(如基因数据、文本数据等)中,通过 PCA 将数据降到二维或三维空间,可以直观地观察数据的分布情况。例如,在分析文档集合时,可以将词频向量表示的文档通过 PCA 降维后,在平面上绘制出文档的分布,从而发现文档之间的相似性和聚类情况。
- 数据预处理
- 在机器学习算法中,高维数据可能会导致模型训练时间过长和过拟合。PCA 可以作为数据预处理步骤,减少数据的维度,同时保留数据的主要信息。例如,在支持向量机(SVM)训练之前,对高维数据进行 PCA 降维,可以加快 SVM 的训练速度,并且在一定程度上提高模型的泛化能力。
- 信号处理
- 在音频和图像信号处理中,PCA 可以用于提取信号的主要成分。例如,在音频信号中,可以通过 PCA 提取主要的频率成分,去除噪声和次要频率成分,从而实现音频信号的压缩和降噪。在图像压缩中,PCA 可以将图像的像素矩阵降维,用较少的系数来表示图像,达到压缩图像数据的目的。
(二)LDA 的应用场景
- 模式识别与分类
- 在人脸识别系统中,LDA 可以用于提取能够区分不同人脸的特征。通过将人脸图像的高维像素数据投影到 LDA 找到的低维空间中,这些低维特征可以有效地用于分类不同的人脸。同样,在手写数字识别中,LDA 可以帮助找到区分不同数字的特征方向,提高数字分类的准确率。
- 生物医学领域的分类问题
- 在疾病诊断中,例如根据基因表达数据来区分癌症和非癌症样本。LDA 可以利用已知的疾病类别标签,找到能够区分不同疾病状态的基因表达模式,从而为疾病的早期诊断和分类提供依据。
六、PCA 和 LDA 在人工智能领域的具体应用
(一)在计算机视觉中的应用
- PCA 的应用
- 在图像特征提取方面,PCA 可以用于提取图像的主成分特征。例如,对于一组风景图片,PCA 可以将每张图片的像素矩阵看作一个高维向量,通过 PCA 找到这些图片的主要变化模式,如光照变化、场景布局变化等的主要方向。这些主成分特征可以作为图像的低维表示,用于图像检索系统。当用户输入一张查询图像时,系统可以通过比较查询图像和数据库中图像的主成分特征来找到相似的图像。
- 在视频分析中,PCA 可以对视频帧序列进行降维。视频数据通常具有非常高的维度,通过 PCA 将视频帧投影到低维空间,可以提取视频的主要动态特征。例如,在动作识别中,PCA 降维后的特征可以用于描述不同的人体动作模式,如行走、跑步、跳跃等,为后续的分类算法提供有效的输入。
- LDA 的应用
- 在目标检测和识别中,LDA 可以用于区分不同类型的目标。例如,在交通场景中,通过 LDA 可以找到能够区分汽车、行人、自行车等不同目标的特征方向。将图像中的目标区域提取出来并投影到 LDA 的低维空间中,然后根据这些低维特征进行目标分类。在安防监控系统中,LDA 可以帮助识别不同的行为模式,如正常行走、可疑徘徊等,从而提高监控系统的智能性。
(二)在自然语言处理中的应用
- PCA 的应用
- 在文本分类任务中,PCA 可以用于对文本的词向量表示进行降维。文本通常被表示为高维的词向量空间(例如通过词袋模型或词嵌入模型),PCA 可以将这些高维词向量投影到低维空间,减少数据的维度。这有助于加快文本分类算法的训练速度,并且可以在一定程度上减轻维度灾难问题。同时,PCA 降维后的文本特征仍然可以保留文本的主要语义信息,例如主题分布等。
- 在文本聚类中,PCA 可以用于对文本数据进行预处理。通过将文本数据降维到二维或三维空间,可以直观地观察文本的聚类情况。例如,在分析新闻文章聚类时,PCA 可以帮助发现不同主题的新闻文章之间的关系,为新闻推荐系统等应用提供支持。
- LDA 的应用
- 在主题模型中,LDA(这里指潜在狄利克雷分配,与线性判别分析同名但不同概念)和线性判别分析 LDA 都有应用。线性判别分析 LDA 可以用于区分不同主题的文本。例如,在学术文献分类中,LDA 可以根据文献的内容和类别标签(如计算机科学、生物学等不同学科领域),找到能够区分不同学科主题的特征方向。这些特征可以用于自动分类学术文献,提高文献检索系统的准确性。
(三)在机器学习算法优化中的应用
- PCA 的应用
- 在神经网络中,PCA 可以用于对输入数据进行预处理。高维输入数据可能会导致神经网络的参数过多,训练困难。通过 PCA 将输入数据降维,可以减少神经网络的输入维度,从而降低网络的复杂度。例如,在图像识别神经网络中,将图像数据经过 PCA 降维后再输入到网络中,可以加快网络的训练速度,并且可能提高网络的泛化能力。
- 在聚类算法中,PCA 可以改善聚类效果。高维数据中的噪声和无关维度可能会干扰聚类算法的正常运行。PCA 通过去除数据中的次要维度和噪声,使得聚类算法能够更好地发现数据的真实聚类结构。例如,在 K - Means 聚类算法中,对数据进行 PCA 预处理后,聚类结果可能会更加准确和稳定。
- LDA 的应用
- 在分类算法中,LDA 可以作为一种特征提取和降维方法与其他分类算法结合使用。例如,在决策树分类器中,将原始数据通过 LDA 降维后再输入到决策树中,可以提高决策树的分类性能。LDA 可以帮助决策树更好地找到区分不同类别数据的特征,减少决策树的深度和复杂度,从而提高分类效率和准确性。在贝叶斯分类器中,LDA 降维后的特征可以用于估计类条件概率,提高贝叶斯分类器的性能。
七、结论
PCA 和 LDA 是两种非常重要的降维方法,它们在原理、目标、适用场景和应用方面都有各自的特点。PCA 侧重于数据的方差和全局结构,是一种无监督的方法,适用于数据可视化、预处理和信号处理等多种场景;LDA 则以类别区分性为重点,是一种有监督的方法,在模式识别、分类和生物医学等领域有着广泛的应用。在人工智能领域,它们在计算机视觉、自然语言处理和机器学习算法优化等方面都发挥着不可替代的作用,帮助研究人员和工程师更好地处理高维数据,提高系统的性能和效率。随着人工智能技术的不断发展,PCA 和 LDA 的应用也将不断拓展和深化,为解决更复杂的高维数据问题提供有力的支持。
PCA 示例代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# 1. 加载示例数据集(这里以鸢尾花数据集为例)
iris = load_iris()
X = iris.data
y = iris.target
# 2. 创建PCA对象并指定要保留的主成分数量(这里保留2个主成分用于可视化)
pca = PCA(n_components=2)
# 3. 对数据进行PCA降维
X_pca = pca.fit_transform(X)
# 4. 可视化降维后的数据
plt.figure(figsize=(8, 6))
for target_name, target_value in zip(iris.target_names, [0, 1, 2]):
plt.scatter(X_pca[y == target_value, 0], X_pca[y == target_value, 1], label=target_name)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA on Iris Dataset')
plt.legend()
plt.show()
在上述代码中:
- 首先通过
sklearn.datasets模块加载了鸢尾花数据集,其中X是数据特征部分,y是对应的类别标签(这里主要用于可视化区分不同类别在降维后空间的分布情况)。 - 接着创建了
PCA类的实例,并指定n_components=2,意味着要将原始数据降到二维空间。 - 调用
fit_transform方法对数据进行拟合和降维操作,得到降维后的数据X_pca。 - 最后使用
matplotlib库将降维后的数据按照不同类别进行可视化展示,这样可以直观看到不同类别鸢尾花在经过 PCA 降维后的二维空间中的分布情况。
LDA 示例代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
# 1. 加载示例数据集(鸢尾花数据集)
iris = load_iris()
X = iris.data
y = iris.target
# 2. 创建LDA对象并指定要保留的判别分量数量(这里保留2个用于可视化)
lda = LDA(n_components=2)
# 3. 对数据进行LDA降维
X_lda = lda.fit(X, y).transform(X)
# 4. 可视化降维后的数据
plt.figure(figsize=(8, 6))
for target_name, target_value in zip(iris.target_names, [0, 1, 2]):
plt.scatter(X_lda[y == target_value, 0], X_lda[y == target_value, 1], label=target_name)
plt.xlabel('Linear Discriminant 1')
plt.ylabel('Linear Discriminant 2')
plt.title('LDA on Iris Dataset')
plt.legend()
plt.show()
在这段 LDA 代码里:
- 同样先加载鸢尾花数据集,获取数据特征
X和类别标签y。 - 创建
LinearDiscriminantAnalysis(缩写为LDA)类的实例,并设定n_components=2,目的是将数据降到二维空间以便可视化。 - 通过
fit方法基于数据和类别标签进行模型训练,然后使用transform方法对数据进行降维转换,得到X_lda。 - 最后利用
matplotlib绘制散点图来展示不同类别鸢尾花在经过 LDA 降维后的二维空间中的分布情况,对比 PCA 可视化的结果,可以看到 LDA 更侧重于让不同类别之间分得更开。
PCA 在图像数据预处理中的应用示例代码
import numpy as np
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 1. 加载人脸数据集(示例使用Labeled Faces in the Wild数据集)
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
X = lfw_people.data
y = lfw_people.target
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. 使用PCA进行降维(这里保留100个主成分,可根据实际情况调整)
pca = PCA(n_components=100)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 4. 使用支持向量机(SVM)进行分类
svm = SVC(kernel='linear')
svm.fit(X_train_pca, y_train)
y_pred = svm.predict(X_test_pca)
# 5. 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
在这个代码示例中:
- 首先从
sklearn.datasets中获取人脸数据集(Labeled Faces in the Wild),包含了人脸图像数据(已经处理为向量形式)以及对应的人物身份标签。 - 划分出训练集和测试集,用于后续的模型训练和评估。
- 创建
PCA对象并设置保留100个主成分,对训练集数据进行拟合和降维,再用训练好的PCA模型对测试集数据进行降维转换。 - 构建了一个线性核的支持向量机(
SVM)分类器,使用降维后的训练数据进行训练,然后对降维后的测试数据进行预测,并计算预测的准确率,以此展示 PCA 在图像数据预处理、降低维度从而辅助分类任务提高效率方面的应用。
LDA 在手写数字识别中的应用示例代码
import numpy as np
from sklearn.datasets import load_digits
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 1. 加载手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. 使用LDA进行降维(这里保留2个判别分量用于简单示例,实际可调整)
lda = LDA(n_components=2)
X_train_lda = lda.fit(X_train, y_train).transform(X_train)
X_test_lda = lda.transform(X_test)
# 4. 使用K近邻分类器进行分类
knn = KNeighborsClassifier()
knn.fit(X_train_lda, y_train)
y_pred = knn.predict(X_test_lda)
# 5. 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
在这个示例里:
- 通过
sklearn.datasets加载手写数字数据集,该数据集包含手写数字的图像特征(以向量形式表示)以及对应的数字类别标签。 - 划分训练集和测试集后,创建
LDA对象并设定保留2个判别分量,对训练集和测试集数据依次进行拟合降维和直接降维操作。 - 运用
K近邻分类器基于降维后的数据进行训练和预测,最后计算准确率,展示了 LDA 在手写数字识别场景下,通过找到区分不同数字类别的投影方向进行降维,进而辅助分类任务提升性能的作用。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









