






一、MobileNet 系列模型
1.1 MobileNetV1 原理
1.1.1 深度可分离卷积
传统卷积操作在计算时,每个卷积核会对输入特征图的所有通道进行卷积操作,以生成输出特征图的一个通道。
1.1.2 模型架构
MobileNetV1 的整体架构由一系列的深度可分离卷积层和全连接层组成。网络的输入是一张 \(224\times 224\times 3\) 的图像,首先经过一个标准的 \(3\times 3\) 卷积层,将通道数增加到 32。然后,依次经过多个深度可分离卷积层,每个深度可分离卷积层由一个深度卷积和一个逐点卷积组成。在网络的前半部分,特征图的尺寸逐渐减小,通道数逐渐增加。例如,经过几个深度可分离卷积层后,特征图尺寸可能从 \(224\times 224\) 减小到 \(112\times 112\),通道数从 32 增加到 64。
最后,通过全局平均池化层将特征图压缩为一维向量,其长度等于最后一个卷积层的通道数。再经过一个全连接层,将向量映射到预定义的类别数,通过 Softmax 函数输出每个类别的概率。
1.1.3 宽度乘数和分辨率乘数
宽度乘数 \(\alpha\) 用于调整输入和输出通道数。假设原始模型的输入通道数为 \(C_{in}\),输出通道数为 \(C_{out}\),使用宽度乘数 \(\alpha\) 后,实际的输入通道数变为 \(\alpha C_{in}\),输出通道数变为 \(\alpha C_{out}\)。通过减小 \(\alpha\) 的值,可以减少模型的参数量和计算量,但可能会降低模型的精度。例如,当 \(\alpha = 0.5\) 时,模型的通道数变为原来的一半,计算量也相应减少。
分辨率乘数 \(\rho\) 用于调整输入图像的分辨率。假设原始输入图像的尺寸为 \(H\times W\),使用分辨率乘数 \(\rho\) 后,实际输入图像的尺寸变为 \(\rho H\times \rho W\)。降低分辨率可以减少计算量,但会损失一定的图像细节,从而影响模型的精度。
1.2 MobileNetV2 原理
1.2.1 线性瓶颈和倒残差结构
在传统的卷积神经网络中,通常会使用非线性激活函数(如 ReLU)来引入非线性,增强模型的表达能力。然而,在低维空间中,ReLU 会导致信息丢失。MobileNetV2 提出了线性瓶颈的概念,在深度可分离卷积的逐点卷积之后,不使用非线性激活函数,而是直接进行线性变换。这是因为在低维空间中,线性变换可以更好地保留特征信息。
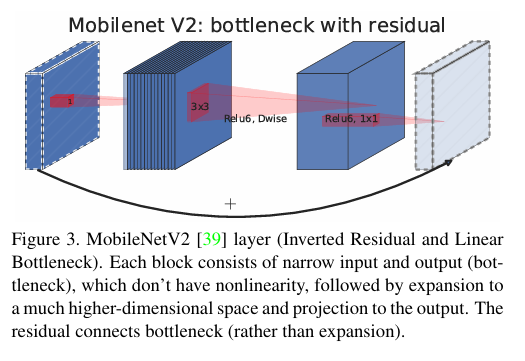
倒残差结构与传统的残差块不同。传统残差块是先通过 \(1\times 1\) 卷积将通道数降低,再进行 \(3\times 3\) 卷积,最后通过 \(1\times 1\) 卷积将通道数恢复。而倒残差结构先通过 \(1\times 1\) 卷积将通道数增加,再进行深度卷积,最后通过 \(1\times 1\) 卷积将通道数降低。这种结构可以在增加通道数的同时减少计算量。
以一个具体的倒残差块为例,假设输入特征图的通道数为 \(C_{in}\),首先通过一个 \(1\times 1\) 卷积将通道数扩展到 \(tC_{in}\)(t 为扩展因子),然后进行深度卷积,最后通过一个 \(1\times 1\) 卷积将通道数压缩到 \(C_{out}\)。如果 \(C_{in}=C_{out}\),则会使用跳跃连接将输入和输出相加。
1.2.2 模型架构
MobileNetV2 的模型架构由多个倒残差块组成。网络的输入同样是一张 \(224\times 224\times 3\) 的图像,首先经过一个标准的 \(3\times 3\) 卷积层,将通道数增加到 32。然后,依次经过多个倒残差块,每个倒残差块包含一个或多个深度可分离卷积层。在网络的前半部分,特征图的尺寸逐渐减小,通道数逐渐增加。
最后,通过全局平均池化层将特征图压缩为一维向量,再经过一个全连接层,将向量映射到预定义的类别数,通过 Softmax 函数输出每个类别的概率。
1.3 MobileNetV3 原理
1.3.1 自动搜索技术
MobileNetV3 使用了神经架构搜索(NAS)技术来自动搜索最优的网络架构。NAS 技术通过定义一个搜索空间和一个评估指标,在搜索空间中不断尝试不同的网络架构,找到在评估指标上表现最优的架构。
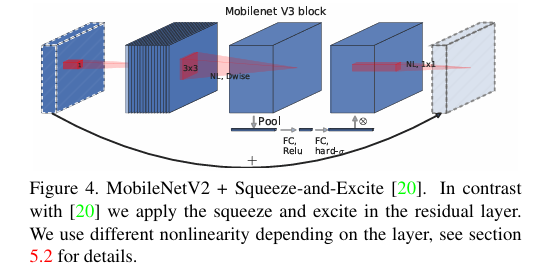
在 MobileNetV3 中,搜索空间包括不同的卷积层配置、激活函数选择、通道数等。评估指标通常是模型的精度和计算量的综合考虑。通过在大规模数据集上进行搜索,找到在精度和计算量之间取得平衡的网络结构。
1.3.2 改进的激活函数

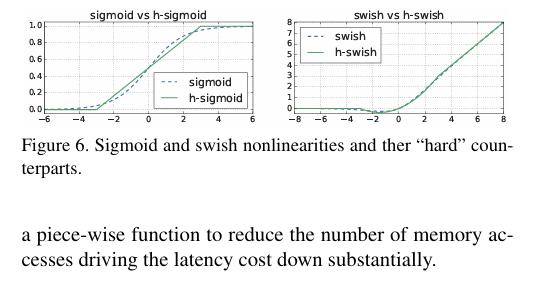
1.3.3 精简的模型结构
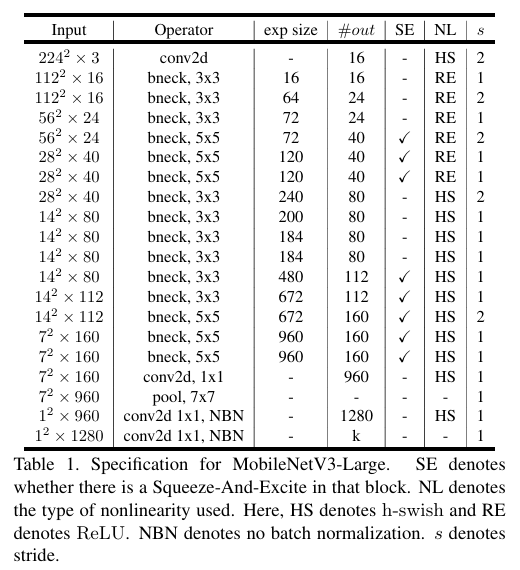
MobileNetV3 对模型结构进行了进一步的精简。它去除了一些不必要的层和参数,同时增加了一些新的模块,如注意力机制。注意力机制可以让模型更加关注重要的特征区域,提高模型的性能。例如,在某些卷积层之后添加 SE(Squeeze-and-Excitation)模块,通过对通道进行自适应的缩放,增强模型对不同通道特征的利用能力。
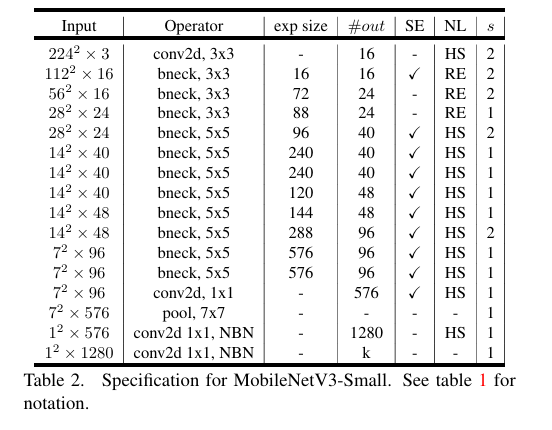
1.4 MobileNet 系列的应用场景
1.4.1 移动设备和嵌入式系统
在移动设备和嵌入式系统中,资源通常比较有限,包括计算能力、内存和电池续航等。MobileNet 系列模型的轻量级特点使其非常适合在这些设备上运行。例如,在智能手机上,可以使用 MobileNet 模型实现实时图像分类应用,如拍照识别花卉、动物等。用户拍摄一张花卉照片,手机上的 MobileNet 模型可以快速判断花卉的种类,并提供相关的信息。
在智能手表等可穿戴设备上,也可以利用 MobileNet 模型进行简单的图像识别任务,如识别运动场景、食物等。由于可穿戴设备的计算资源和电池续航有限,MobileNet 模型的低计算量和低功耗特性可以保证应用的流畅运行。
1.4.2 物联网(IoT)设备
物联网设备通常分布在各种环境中,且数量众多,对设备的成本和能耗有较高的要求。MobileNet 系列模型可以满足这些需求,用于智能家居、智能农业等领域的图像识别任务。
在智能家居中,智能摄像头可以使用 MobileNet 模型识别家中的人员、物体等。例如,当检测到主人回家时,自动打开灯光、空调等设备。在智能农业中,安装在农田里的摄像头可以使用 MobileNet 模型识别农作物的生长状态、病虫害情况等,为农民提供决策依据。
1.4.3 实时图像分类任务
对于一些需要实时处理的图像分类任务,如视频监控中的目标分类、自动驾驶中的交通标志识别等,MobileNet 系列模型的快速推理速度可以保证系统的实时性。
在视频监控系统中,每秒需要处理大量的视频帧。MobileNet 模型可以在短时间内对每一帧图像进行分类,判断是否存在异常目标,如入侵者、火灾等。在自动驾驶中,车辆需要实时识别道路上的交通标志,如限速标志、红绿灯等。MobileNet 模型的快速推理能力可以确保车辆及时做出正确的决策。
二、YOLO 分类模型原理
2.1 YOLO 基本原理
2.1.1 边界框预测
YOLO 将输入图像划分为 \(S\times S\) 个网格,每个网格负责预测 B 个边界框。每个边界框由四个参数表示:中心坐标 \((x, y)\)、宽度 w 和高度 h。这些参数是相对于网格的位置和大小进行归一化的。
假设网格的左上角坐标为 \((x_{grid}, y_{grid})\),网格的宽度和高度分别为 \(w_{grid}\) 和 \(h_{grid}\)。边界框的中心坐标 \((x, y)\) 是相对于网格左上角的偏移量,范围在 \([0, 1]\) 之间。宽度 w 和高度 h 是相对于整个图像的宽度和高度进行归一化的,范围也在 \([0, 1]\) 之间。
2.1.2 置信度预测

2.1.3 类别概率预测
每个网格还会预测 C 个类别概率,表示该网格内目标属于每个类别的概率。这些概率是在假设该网格内包含目标的前提下进行预测的。最终,每个边界框的类别概率是通过将置信度与网格的类别概率相乘得到的。
2.2 YOLO 系列的发展
2.2.1 YOLOv1
YOLOv1 是 YOLO 系列的第一个版本,它将输入图像划分为 \(7\times 7\) 个网格,每个网格预测 2 个边界框。YOLOv1 的优点是速度快,但在小目标检测和定位精度上存在一定的不足。
由于 YOLOv1 是将图像划分为固定大小的网格,对于小目标,如果目标跨多个网格或者位于网格边缘,可能会导致检测不准确。此外,YOLOv1 在训练时使用了均方误差损失函数,对于不同类型的预测(如边界框坐标、置信度、类别概率)没有进行有效的区分,可能会影响模型的性能。
2.2.2 YOLOv2
YOLOv2 在 YOLOv1 的基础上进行了改进,引入了锚框(Anchor Boxes)的概念。锚框是预先定义的一组不同大小和比例的边界框,通过聚类算法自动学习不同目标的先验框尺寸。在预测时,每个边界框会预测相对于锚框的偏移量,而不是直接预测边界框的坐标。
同时,YOLOv2 还采用了批量归一化(Batch Normalization)技术,加速了模型的训练过程。批量归一化可以使输入数据的分布更加稳定,减少了内部协变量偏移,从而提高了模型的收敛速度和泛化能力。
2.2.3 YOLOv3
YOLOv3 进一步改进了模型结构,采用了多尺度检测的方法。它在不同尺度的特征图上进行目标检测,提高了对不同大小目标的检测能力。具体来说,YOLOv3 使用了 Darknet - 53 作为骨干网络,提取不同尺度的特征图。然后,在这些特征图上分别进行目标检测,每个尺度的特征图负责检测不同大小的目标。
此外,YOLOv3 还使用了逻辑回归来预测每个边界框的置信度和类别概率,避免了 Softmax 函数在多标签分类中的局限性。
2.2.4 YOLOv4
YOLOv4 在 YOLOv3 的基础上进行了大量的改进,包括使用了新的骨干网络(CSPDarknet53)、PANet 作为特征融合网络、Mish 激活函数等。
CSPDarknet53 是在 Darknet - 53 的基础上进行改进的,通过引入跨阶段部分连接(Cross Stage Partial Connection),减少了模型的计算量,提高了特征的表达能力。PANet 是一种特征融合网络,它可以将不同尺度的特征图进行融合,增强了模型对不同大小目标的检测能力。Mish 激活函数具有更好的非线性特性,可以提高模型的性能。
2.2.5 YOLOv5
YOLOv5 是一个开源的目标检测框架,它采用了 PyTorch 深度学习框架实现,具有易于使用、训练速度快等优点。YOLOv5 提供了不同大小的模型(如 YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x),可以根据不同的应用场景选择合适的模型。
YOLOv5 在模型结构上进行了优化,采用了 Focus 层、CSP 模块等,提高了模型的计算效率。同时,它还支持数据增强、模型量化等技术,进一步提高了模型的性能和部署效率。
2.2.6 YOLOv8
YOLOv8 是 Ultralytics 公司在 2023 年发布的最新版本的 YOLO 系列模型,它在 YOLOv5 的基础上进行了全面的升级。YOLOv8 采用了更先进的模型架构,如改进的 CSP 模块和注意力机制,提高了模型的检测精度和速度。
在训练方面,YOLOv8 支持多种训练策略,如自适应学习率调整、混合精度训练等,加速了模型的训练过程。此外,YOLOv8 还提供了丰富的 API 和工具,方便用户进行模型的训练、评估和部署。
2.3 YOLO 分类模型的应用场景
2.3.1 视频监控
在视频监控领域,YOLO 分类模型可以实时检测视频中的目标,如人员、车辆、物体等,并对其进行分类。在安防监控中,YOLO 模型可以检测监控区域内是否有陌生人进入,当检测到异常情况时,及时发出警报。在交通监控中,YOLO 模型可以检测道路上的车辆类型、行驶方向等信息,为交通管理提供数据支持。
例如,在一个大型商场的监控系统中,YOLO 模型可以实时检测商场内的人员流动情况,统计不同区域的人流量,帮助商场管理者进行合理的布局和营销决策。
2.3.2 自动驾驶
在自动驾驶中,YOLO 分类模型可以检测道路上的各种目标,如行人、车辆、交通标志等,为自动驾驶系统提供决策依据。自动驾驶车辆需要实时感知周围的环境,YOLO 模型的快速检测能力可以确保车辆及时做出正确的决策,如刹车、加速、转弯等。
例如,当自动驾驶车辆行驶在道路上时,YOLO 模型可以检测到前方的行人,及时发出警报并采取制动措施,避免发生碰撞事故。
2.3.3 工业检测
在工业生产中,YOLO 分类模型可以用于产品质量检测、缺陷检测等任务。通过检测产品中的缺陷和异常,提高产品质量和生产效率。
例如,在电子产品生产线上,YOLO 模型可以检测电路板上的元件是否安装正确、是否存在短路等问题。在食品生产线上,YOLO 模型可以检测食品的外观、大小、颜色等是否符合标准,筛选出不合格的产品。
2.3.4 智能安防
在智能安防领域,YOLO 分类模型可以用于门禁系统、入侵检测等场景。通过检测人员和物体的进出情况,保障安全。
例如,在一个企业的门禁系统中,YOLO 模型可以检测进入人员的身份和面部特征,判断是否为授权人员。如果检测到未经授权的人员进入,系统会及时发出警报。
三、MobileNet 系列与 YOLO 分类模型的比较
3.1 功能和任务
3.1.1 MobileNet 系列
MobileNet 系列主要用于图像分类任务,即判断输入图像属于哪一个预定义的类别。它只关注图像的整体类别,不涉及目标的位置信息。例如,输入一张猫的图片,MobileNet 模型会输出该图片属于猫类别的概率。
3.1.2 YOLO 分类模型
YOLO 分类模型主要用于目标检测任务,不仅要识别出图像中存在的目标类别,还要确定目标在图像中的具体位置。例如,输入一张包含多个人和车辆的街道图片,YOLO 模型会输出每个人和每辆车的位置信息(边界框)以及对应的类别标签。
3.2 模型复杂度和计算量
3.2.1 MobileNet 系列
MobileNet 系列模型通过深度可分离卷积等技术,大幅减少了模型的参数量和计算量,具有轻量级的特点。特别是 MobileNetV3,在保证一定精度的前提下,进一步优化了模型结构,计算效率更高。
以 MobileNetV3 - Small 为例,其参数量约为 2.5 百万,计算量约为 0.22 亿次乘法累加运算(MAdd)。相比之下,一些大型的图像分类模型,如 ResNet - 50,参数量约为 2500 万,计算量约为 3.86 亿次乘法累加运算(MAdd)。
3.2.2 YOLO 分类模型
YOLO 分类模型的复杂度和计算量相对较高,尤其是在处理高分辨率图像和多目标检测时。虽然 YOLO 系列在不断优化,但为了保证检测精度,仍然需要一定的计算资源。
以 YOLOv5s 为例,其参数量约为 7.2 百万,计算量约为 16.5 亿次乘法累加运算(MAdd)。当输入图像的分辨率增加或者目标数量增多时,计算量会进一步增大。
3.3 精度和性能
3.3.1 MobileNet 系列
在图像分类任务中,MobileNet 系列的精度相对较高,但与一些大型的图像分类模型(如 ResNet、EfficientNet)相比,仍有一定的差距。不过,由于其轻量级的特点,在资源受限的设备上可以实现快速推理。
例如,在 ImageNet 数据集上,MobileNetV3 - Large 的 top - 1 准确率约为 75.2%,而 ResNet - 50 的 top - 1 准确率约为 76.1%。虽然 MobileNetV3 - Large 的准确率略低于 ResNet - 50,但它的计算量和参数量远小于 ResNet - 50,在移动设备上的推理速度更快。
3.3.2 YOLO 分类模型
在目标检测任务中,YOLO 分类模型的精度和性能在不断提高。随着版本的更新,YOLO 系列在检测精度和速度上都取得了显著的进步,特别是 YOLOv8,在多个数据集上都达到了领先的水平。
例如,在 COCO 数据集上,YOLOv8s 的平均精度(mAP)约为 48.2%,推理速度约为 95 帧每秒(FPS)。相比之下,YOLOv5s 的 mAP 约为 46.3%,推理速度约为 90 帧每秒(FPS)。
3.4 应用场景的适应性
3.4.1 MobileNet 系列
适用于对计算资源要求较高、实时性要求较低的图像分类场景,如移动设备上的图像识别应用、物联网设备中的图像分类任务等。在这些场景中,设备的计算能力和电池续航有限,需要模型能够在低功耗、低计算资源的情况下运行。
例如,在一个智能门锁系统中,使用 MobileNet 模型进行人脸识别,只需要判断输入的人脸图像是否与授权人员的人脸匹配,不需要知道人脸在图像中的具体位置。由于智能门锁的计算资源有限,MobileNet 模型的轻量级特点可以保证系统的稳定运行。
3.4.2 YOLO 分类模型
适用于需要实时处理、对目标位置信息有要求的场景,如视频监控、自动驾驶、工业检测等。在这些场景中,需要模型能够快速准确地检测出目标的位置和类别,以做出及时的决策。
例如,在一个自动驾驶车辆中,YOLO 模型需要实时检测道路上的行人、车辆、交通标志等目标的位置和类别,为车辆的行驶提供决策依据。由于自动驾驶车辆的行驶速度较快,需要模型具有较高的实时性和准确性。
3.5 模型训练和部署
3.5.1 MobileNet 系列
MobileNet 系列模型的训练相对简单,由于其参数量少,训练速度较快。在训练过程中,可以使用较小的批量大小和较少的训练轮数,从而减少训练时间和计算资源的消耗。
在部署方面,由于其轻量级的特点,可以很容易地部署到各种设备上。可以将 MobileNet 模型转换为适合移动设备和嵌入式系统的格式,如 TensorFlow Lite、ONNX 等,然后在这些设备上进行推理。
3.5.2 YOLO 分类模型
YOLO 分类模型的训练需要大量的标注数据和计算资源,训练过程相对复杂。由于 YOLO 模型需要同时预测目标的位置和类别,损失函数的设计和优化比较复杂。在训练过程中,需要使用较大的批量大小和较多的训练轮数,以保证模型的收敛和精度。
在部署方面,由于其计算量较大,需要配备高性能的 GPU 才能实现高效推理。可以将 YOLO 模型部署到服务器、边缘计算设备等具有较强计算能力的设备上。同时,为了提高部署效率,还可以使用模型量化、剪枝等技术对模型进行优化。
四、结论
MobileNet 系列和 YOLO 分类模型在功能、模型复杂度、精度和应用场景等方面存在明显的差异。MobileNet 系列适用于图像分类任务,具有轻量级、计算量小的特点,适合在资源受限的设备上运行;而 YOLO 分类模型适用于目标检测任务,能够同时识别目标的类别和位置,在实时性要求较高的场景中表现出色。
在实际应用中,需要根据具体的任务需求和资源情况选择合适的模型。如果是简单的图像分类任务,且对计算资源有限制,那么 MobileNet 系列模型是一个不错的选择;如果是需要实时检测目标位置和类别的任务,那么 YOLO 分类模型更适合。
同时,随着深度学习技术的不断发展,MobileNet 系列和 YOLO 分类模型也在不断改进和优化。未来,我们可以期待这些模型在更多的领域得到应用,为我们的生活和工作带来更多的便利。例如,在医疗领域,MobileNet 模型可以用于医学图像的分类诊断,YOLO 模型可以用于肿瘤的检测和定位;在农业领域,MobileNet 模型可以用于农作物的分类识别,YOLO 模型可以用于病虫害的检测和防治。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









