






 本文探讨了在使用LSTM处理自然语言时,考虑到LSTM本身能捕捉时间序列信息,作者疑惑是否有必要额外添加自注意力机制来强调不同时间步长的输出重要性。读者寻求对此问题的见解和解答。
本文探讨了在使用LSTM处理自然语言时,考虑到LSTM本身能捕捉时间序列信息,作者疑惑是否有必要额外添加自注意力机制来强调不同时间步长的输出重要性。读者寻求对此问题的见解和解答。
一、LSTM用于自然语言处理中,可以捕捉过往时序的信息,当LSTM层的每个时间步长都输出时,应该是当前时刻输出值所包含的过往输入信息最大,那么还有必要在输出层使用注意力机制模型注意不同的因状态的时刻输出吗?
如下图,LSTM+Attention网络结构图。
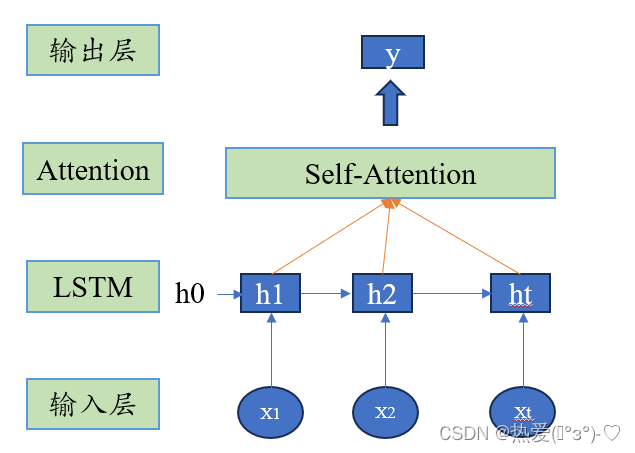
网络设置:
输入层:输入维度(样本数,时间步长,每个时刻样本的维度),输入是3D张量
LSTM:保证每一个时刻均输出,需要设置如下(tensorflow)LSTM 隐藏层神经元个数是输入向量的维度伸缩(输入特征维度5,LSTM隐藏层个数10,即输入特征5>10变换)
return_sequences=TrueAttention:对LSTM输出进行自注意力机制,然后进行打分最终预测不同LSTM输出时刻对y的重要性。
输出层:y(可能需要经过flatten()进行维度展平)
但是以上困惑之处,在于LSTM每一个输出时刻都是按照一定信息量逐步增加,例如图中,h4>h3>h2>h1,在最终预测y。为何还需要自注意力机制?(请各位大佬指点迷津!)















 3215
3215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









