






上次给出了将解耦知识蒸馏应用于高光谱图像分类的代码。这次我们将继续探讨这一研究领域。首先我们需要给出一些常用的基础概念加深读者对这一方面的理解。
1)知识蒸馏的基本概念:
知识蒸馏(Knowledge Distillation, KD)是一种模型压缩技术,旨在通过将大型、性能优越的教师网络(Teacher Network)中的知识传递给较小的学生网络(Student Network),以提升学生网络的性能,同时减少计算和存储成本。不同网络层的知识传递,可以将其分为:1)基于中间层的知识蒸馏;2)基于决策层的知识蒸馏。
给出一个基于中间层知识蒸馏的小案例。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的教师网络(Teacher Network)
class TeacherNet(nn.Module):
def __init__(self):
super(TeacherNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.fc = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = torch.relu(self.conv1(x)) # 取出中间特征
feature = torch.relu(self.conv2(x)) # 这个作为中间层知识
x = torch.flatten(feature, start_dim=1)
x = self.fc(x)
return x, feature
# 定义一个较小的学生网络(Student Network)
class StudentNet(nn.Module):
def __init__(self):
super(StudentNet, self).__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1) # 通道数减少
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1) # 通道数减少
self.fc = nn.Linear(16 * 7 * 7, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
feature = torch.relu(self.conv2(x)) # 这个作为学生的中间特征
x = torch.flatten(feature, start_dim=1)
x = self.fc(x)
return x, feature
# 蒸馏训练过程
def train_distillation(teacher, student, data, optimizer, criterion, kd_criterion, alpha=0.5):
teacher.eval() # 教师网络设为评估模式
student.train()
for x, y in data:
x, y = x.to(device), y.to(device)
# 前向传播
with torch.no_grad():
teacher_pred, teacher_feature = teacher(x) # 获取教师网络输出和中间层特征
student_pred, student_feature = student(x) # 获取学生网络输出和中间层特征
# 计算普通分类损失
loss_cls = criterion(student_pred, y)
# 计算中间层的 MSE 知识蒸馏损失
loss_kd = kd_criterion(student_feature, teacher_feature.detach()) # detach 使教师特征不参与梯度计算
# 总损失 = 分类损失 + 蒸馏损失
loss = alpha * loss_cls + (1 - alpha) * loss_kd
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 训练流程
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
teacher_model = TeacherNet().to(device)
student_model = StudentNet().to(device)
# 假设数据加载器 `train_loader` 已经定义
optimizer = optim.Adam(student_model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss() # 分类损失
kd_criterion = nn.MSELoss() # 中间层蒸馏损失
# 训练学生网络
train_distillation(teacher_model, student_model, train_loader, optimizer, criterion, kd_criterion, alpha=0.5)
在2015年知识蒸馏被提出的一段时间里研究们大都研究的是基于中间层特征的研究,研究者们通过实验证明基于决策的知识蒸馏的效果是不如基于中间层知识蒸馏的。在2022年"Decoupled Knowledge Distillation"中提出从理论分析决策层的语义信息应该是要比中间层的语义信息丰富。但是,基于决策层的知识蒸馏的效果却不如基于中间层的。基于这一问题,B.Zhao等人从经典解耦知识蒸馏的公式入手,因为他们分析是经典知识蒸馏的蒸馏损失存在耦合导致其在传递知识时受限。
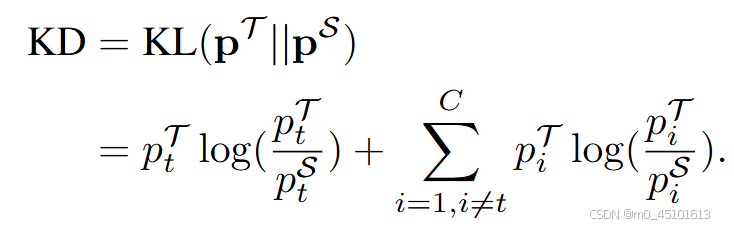
所以他们对这一经典的知识蒸馏公式进行解耦
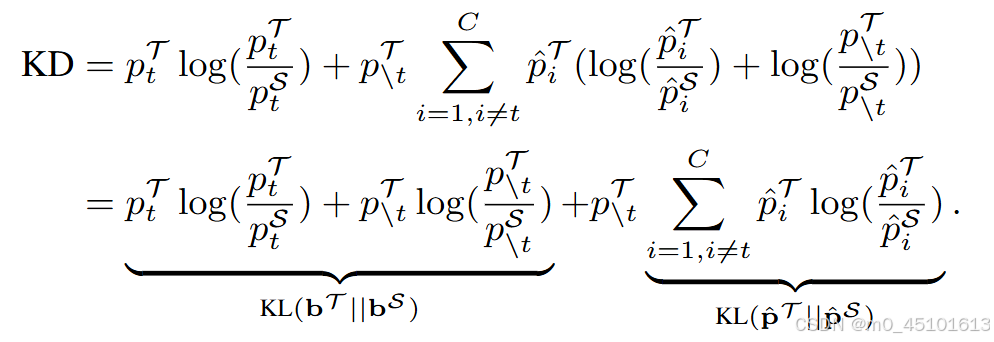
通过这样的方法使得基于决策层的知识蒸馏超越了基于中间层的知识蒸馏。这为知识蒸馏的研究有提供了一个重要的方向。
以上就是对知识蒸馏以及它的相关概念的补充。
在了解知识蒸馏的概念和用法后我们提出了一个问题:为什么需要将知识蒸馏应用于高光谱图像分类?
知识蒸馏可以获得一个模型量小且分类精度良好的学生网络。而分析高光谱图像一般都是在体积小且集成度高的传感器上进行。这时一个小而鲁棒的模型就显得至关重要。
接下来我们的研究方向就是如何将知识蒸馏应用于高光谱图像分类使其得到一个小而鲁棒的模型。
在上一篇我们给出了将解耦知识蒸馏应用于高光谱图像分类的代码。如果你完成了以上代码的复现,你会发现直接将解耦蒸馏蒸馏的方法应用于高光谱图像分类很难得到一个小而鲁棒的模型,即使我们对一些超参数进行了调整。
这将是我们下一篇解决的问题。

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









