







初次尝试训练CIFAR-100:【图像分类】CIFAR-100图像分类任务-CSDN博客
1.训练模型(MyModel.py)
import torch
import torch.nn as nn
class BasicRes(nn.Module):
def __init__(self, in_cha, out_cha, stride=1, res=True):
super(BasicRes, self).__init__()
self.layer01 = nn.Sequential(
nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(out_cha),
nn.ReLU(),
)
self.layer02 = nn.Sequential(
nn.Conv2d(in_channels=out_cha, out_channels=out_cha, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_cha),
)
if res:
self.res = res
if in_cha != out_cha or stride != 1: # 若x和f(x)维度不匹配:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_cha),
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
residual = x
x = self.layer01(x)
x = self.layer02(x)
if self.res:
x += self.shortcut(residual)
return x
# 2.训练模型
class cifar100(nn.Module):
def __init__(self):
super(cifar100, self).__init__()
# 初始维度3*32*32
self.Stem = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=1, padding=2), # (32-5+2*2)/1+1=32
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer01 = BasicRes(in_cha=64, out_cha=64)
self.layer02 = BasicRes(in_cha=64, out_cha=64)
self.layer11 = BasicRes(in_cha=64, out_cha=128)
self.layer12 = BasicRes(in_cha=128, out_cha=128)
self.layer21 = BasicRes(in_cha=128, out_cha=256)
self.layer22 = BasicRes(in_cha=256, out_cha=256)
self.layer31 = BasicRes(in_cha=256, out_cha=512)
self.layer32 = BasicRes(in_cha=512, out_cha=512)
self.pool_max01 = nn.MaxPool2d(1, 1)
self.pool_max02 = nn.MaxPool2d(2)
self.pool_avg = nn.AdaptiveAvgPool2d((1, 1)) # b*c*1*1
self.fc = nn.Sequential(
nn.Dropout(0.4),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 100),
)
def forward(self, x):
x = self.Stem(x)
x = self.pool_max01(x)
x = self.layer01(x)
x = self.layer02(x)
x = self.pool_max02(x)
x = self.layer11(x)
x = self.layer12(x)
x = self.pool_max02(x)
x = self.layer21(x)
x = self.layer22(x)
x = self.pool_max02(x)
x = self.layer31(x)
x = self.layer32(x)
x = self.pool_max02(x)
x = self.pool_avg(x).view(x.size()[0], -1)
x = self.fc(x)
return x
由于CIFAR-100图像维度为(3,32,32),适当修改了ResNet-18的设计框架加以应用。
2.正式训练
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import time
from MyModel import BasicRes, cifar100
total_start = time.time()
# 正式训练函数
def train_val(train_loader, val_loader, device, model, loss, optimizer, epochs, save_path): # 正式训练函数
model = model.to(device)
plt_train_loss = [] # 训练过程loss值,存储每轮训练的均值
plt_train_acc = [] # 训练过程acc值
plt_val_loss = [] # 验证过程
plt_val_acc = []
max_acc = 0 # 以最大准确率来确定训练过程的最优模型
for epoch in range(epochs): # 开始训练
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
start_time = time.time()
model.train()
for index, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad() # 梯度置0
pred = model(images)
bat_loss = loss(pred, labels) # CrossEntropyLoss会对输入进行一次softmax
bat_loss.backward() # 回传梯度
optimizer.step() # 更新模型参数
train_loss += bat_loss.item()
# 注意此时的pred结果为64*10的张量
pred = pred.argmax(dim=1)
train_acc += (pred == labels).sum().item()
print("当前为第{}轮训练,批次为{}/{},该批次总loss:{} | 正确acc数量:{}"
.format(epoch+1, index+1, len(train_data)//config["batch_size"],
bat_loss.item(), (pred == labels).sum().item()))
# 计算当前Epoch的训练损失和准确率,并存储到对应列表中:
plt_train_loss.append(train_loss / train_loader.dataset.__len__())
plt_train_acc.append(train_acc / train_loader.dataset.__len__())
model.eval() # 模型调为验证模式
with torch.no_grad(): # 验证过程不需要梯度回传,无需追踪grad
for index, (images, labels) in enumerate(val_loader):
images, labels = images.cuda(), labels.cuda()
pred = model(images)
bat_loss = loss(pred, labels) # 算交叉熵loss
val_loss += bat_loss.item()
pred = pred.argmax(dim=1)
val_acc += (pred == labels).sum().item()
print("当前为第{}轮验证,批次为{}/{},该批次总loss:{} | 正确acc数量:{}"
.format(epoch+1, index+1, len(val_data)//config["batch_size"],
bat_loss.item(), (pred == labels).sum().item()))
val_acc = val_acc / val_loader.dataset.__len__()
if val_acc > max_acc:
max_acc = val_acc
torch.save(model, save_path)
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc)
print('该轮训练结束,训练结果如下[%03d/%03d] %2.2fsec(s) TrainAcc:%3.6f TrainLoss:%3.6f | valAcc:%3.6f valLoss:%3.6f \n\n'
% (epoch+1, epochs, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1]))
print(f'训练结束,最佳模型的准确率为{max_acc}')
plt.plot(plt_train_loss) # 画图
plt.plot(plt_val_loss)
plt.title('loss')
plt.legend(['train', 'val'])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
# plt.savefig('./acc.png')
plt.show()
# 1.数据预处理
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力
transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
ori_data = dataset.CIFAR100(
root="./Data_CIFAR100",
train=True,
transform=transform,
download=True
)
print(f"各标签的真实含义:{ori_data.class_to_idx}\n")
# print(len(ori_data))
# # 查看某一样本数据
# image, label = ori_data[0]
# print(f"Image shape: {image.shape}, Label: {label}")
# image = image.permute(1, 2, 0).numpy()
# plt.imshow(image)
# plt.title(f'Label: {label}')
# plt.show()
config = {
"train_size_perc": 0.8,
"batch_size": 64,
"learning_rate": 0.001,
"epochs": 50,
"save_path": "model_save/Res_cifar100_model.pth"
}
# 设置训练集和验证集的比例
train_size = int(config["train_size_perc"] * len(ori_data)) # 80%用于训练
val_size = len(ori_data) - train_size # 20%用于验证
train_data, val_data = random_split(ori_data, [train_size, val_size])
# print(len(train_data))
# print(len(val_data))
train_loader = DataLoader(dataset=train_data, batch_size=config["batch_size"], shuffle=True)
val_loader = DataLoader(dataset=val_data, batch_size=config["batch_size"], shuffle=False)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")
model = cifar100()
# model = torch.load(config["save_path"]).to(device)
print(f"我的模型框架如下:\n{model}")
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=config["learning_rate"], weight_decay=1e-4) # L2正则化
# optimizer = torch.optim.Adam(model.parameters(), lr=config["learning_rate"]) # 优化器
train_val(train_loader, val_loader, device, model, loss, optimizer, config["epochs"], config["save_path"])
print(f"\n本次训练总耗时为:{(time.time()-total_start) / 60 }min")
3.测试文件
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import time
from MyModel import BasicRes, cifar100
total_start = time.time()
# 测试函数
def test(save_path, test_loader, device, loss): # 测试函数
best_model = torch.load(save_path).to(device)
test_loss = 0.0
test_acc = 0.0
start_time = time.time()
with torch.no_grad():
for index, (images, labels) in enumerate(test_loader):
images, labels = images.cuda(), labels.cuda()
pred = best_model(images)
bat_loss = loss(pred, labels) # 算交叉熵loss
test_loss += bat_loss.item()
pred = pred.argmax(dim=1)
test_acc += (pred == labels).sum().item()
print("正在最终测试:批次为{}/{},该批次总loss:{} | 正确acc数量:{}"
.format(index + 1, len(test_data) // config["batch_size"],
bat_loss.item(), (pred == labels).sum().item()))
print('最终测试结束,测试结果如下:%2.2fsec(s) TestAcc:%.2f%% TestLoss:%.2f \n\n'
% (time.time() - start_time, test_acc/test_loader.dataset.__len__()*100, test_loss/test_loader.dataset.__len__()))
# 1.数据预处理
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力
transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
test_data = dataset.CIFAR100(
root="./Data_CIFAR100",
train=False,
transform=transform,
download=True
)
# print(len(test_data)) # torch.Size([3, 32, 32])
config = {
"batch_size": 64,
"save_path": "model_save/Res_cifar100_model.pth"
}
test_loader = DataLoader(dataset=test_data, batch_size=config["batch_size"], shuffle=True)
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")
test(config["save_path"], test_loader, device, loss)
print(f"\n本次训练总耗时为:{time.time()-total_start}sec(s)")4.训练结果
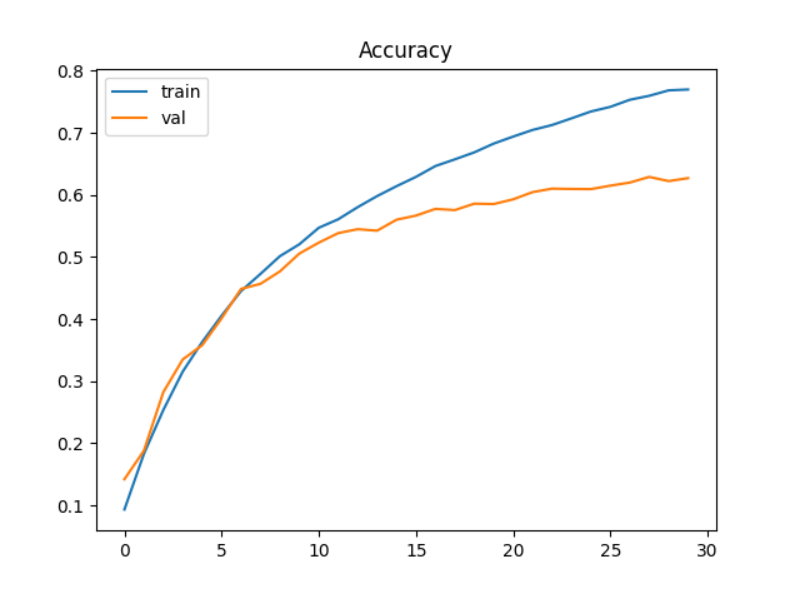
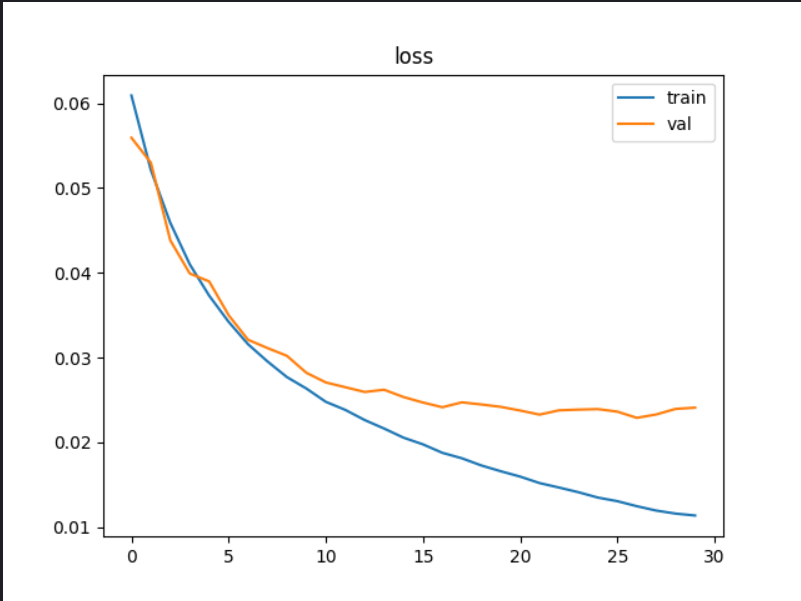

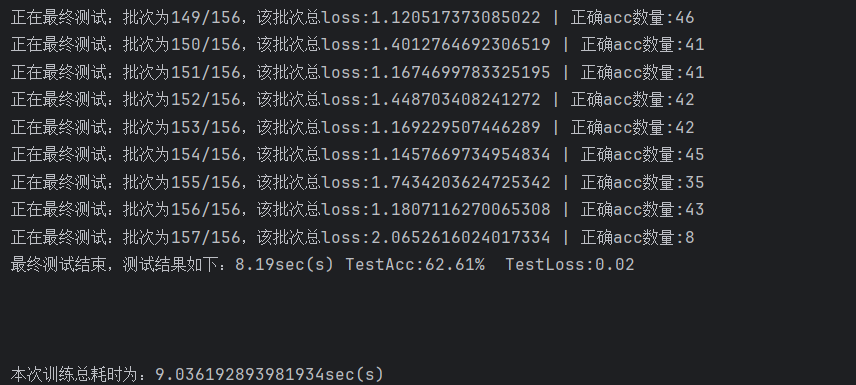
设计learning rate=0.001先训练了30轮,模型在测试集上的准确率已经来到了62.61%;
后续引入学习率衰减策略对同一网络进行再次训练,初始lr=0.001,衰减系数0.2,每20轮衰减一次,训练60轮,结果如下:
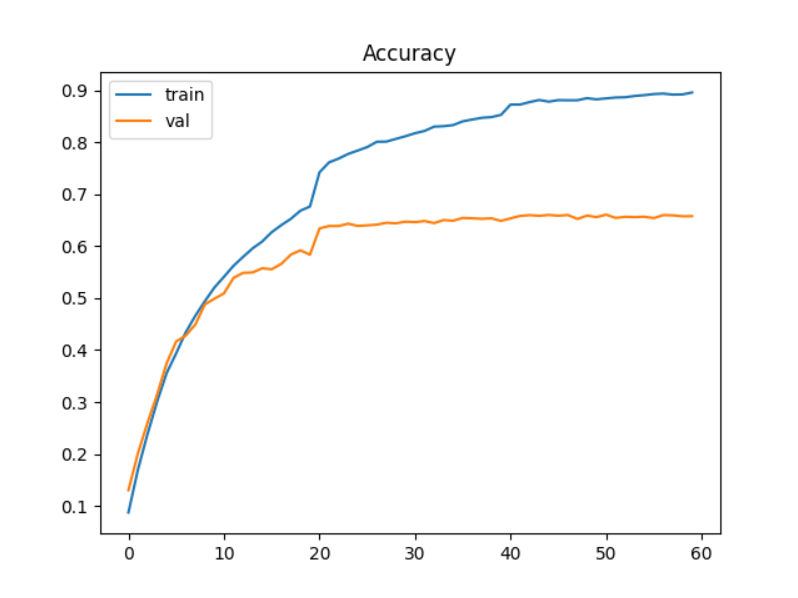
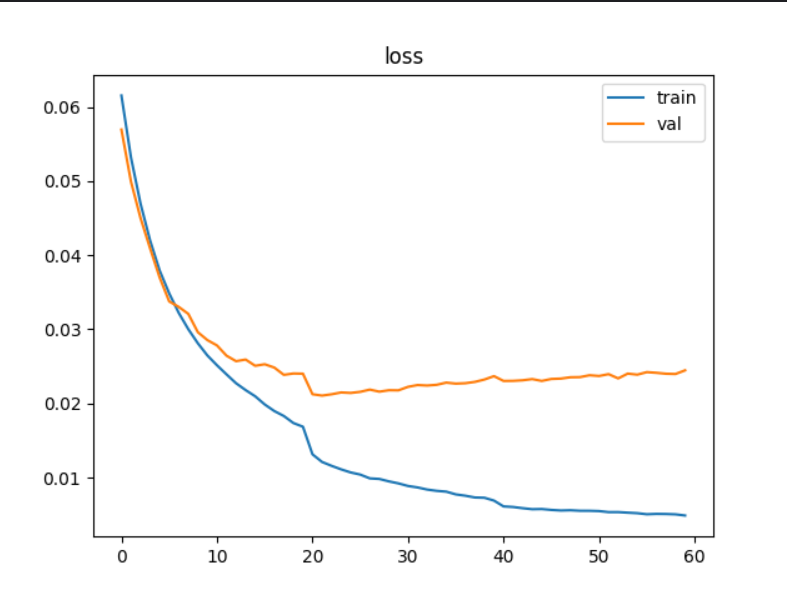
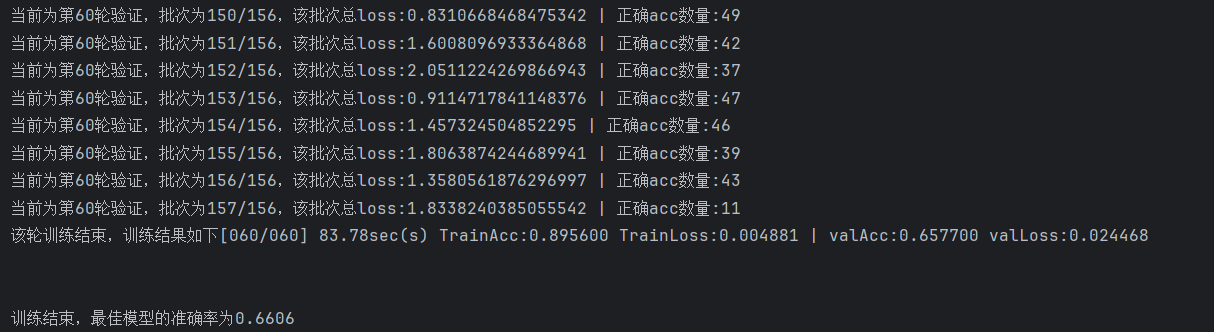
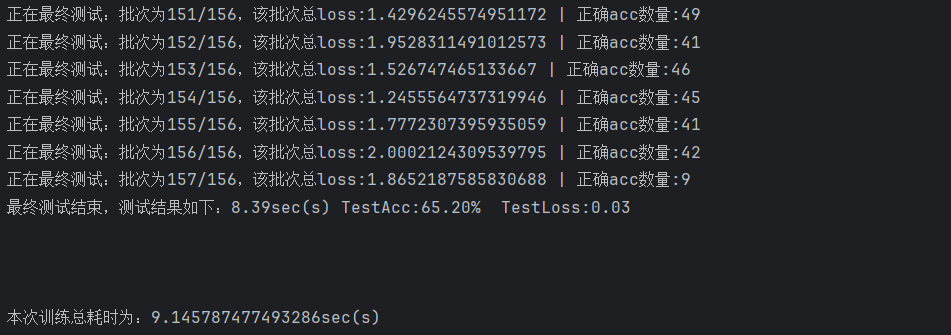
最终训练模型在测试集上的准确率 达到了65.20%

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









