







机器学习概念总结
前言
记录机器学习中常见及常用到的概念,便于后续章节学习理解
一、机器学习是什么?
机器学习是人工智能的一个分支,基于历史数据进行的学习,预测相关问题的输出。
二、机器学习分类
1.有监督学习
有监督学习:用已知某种或某些特性的样本作为训练集,以建立一个数学模型,再用已建立的模型来预测未知样本,此种方法被称为有监督学习,是最常用的一种机器学习方法。是从标签化训练数据集中推断出模型的机器学习任务。
1.1判别式模型(Discriminative Model):
直接对条件概率p(y|x)进行建模,常见判别模型有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
1.2生成式模型(Generative Model):
对联合分布概率p(x,y)进行建模,常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
1.3不同
生成式模型更普适;判别式模型更直接,目标性更强 生成式模型关注数据是如何产生的,寻找的是数据分布模型;判别式模型关注的数据的 差异性,寻找的是分类面 由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型
2.无监督学习
无监督学习:与监督学习相比,无监督学习的训练集中没有人为的标注的结果,在非监督的学习过程中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的 特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出 必要的标签信息。
3.半监督学习(SSL)
半监督学习:考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,是有监督学习和无监督学习的结合。
主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。
SSL的成立依赖于模型假设,主要分为三大类:平滑假设、聚类假设、流行假设;其中流行假设更具有普遍性。
SSL类型的算法主要分为四大类:半监督分类、半监督回归、半监督聚类、半监督降维。
缺点:抗干扰能力弱,仅适合于实验室环境,其现实意义还没有体现出来;未来的发展主要是聚焦于新模型假设的产生
4.其他分类
分类:通过分类模型,将样本数据集中的样本映射到某个给定的类别中
聚类:通过聚类模型,将样本数据集中的样本分为几个类别,属于同一类别的样本相似性比较大
回归:反映了样本数据集中样本的属性值的特性,通过函数表达样本映射的关系来发现属性值之间的依赖关系
关联规则:获取隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现频率
三、机器学习开发流程
数据收集
数据预处理
特征提取
模型构建
模型测试评估
投入使用(模型部署与整合)
迭代优化
四、常见概念
错误率:分类错误的样本占总样本的比例;
精度:分类正确的样本占总样本的比例;
误差:实际预测输出与样本的真实输出之间的差异;
训练误差(经验误差):在训练集上的误差;
泛化误差:在新样本上的误差;
过拟合:在训练集上表现很好,测试集表现一般,泛化性能下降;
欠拟合:在训练集和测试集上表现都一般;
鲁棒性:也就是健壮性,稳健性,强健性,是系统的健壮性;当存在异常数据的时候,算法也会你和数据。
数据集划分(训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程中引入额外的偏差而对最终结果产生影响)
留出法:直接将数据D划分为两个互斥的集合,其中一个作为训练集S,另一个作为测试集T。
(训练集和测试集的大小:大约2/3~4/5的数据集用于训练,剩余样本用于测试)
分层抽样:以类别比例的方式采样;
交叉验证法:将数据集划分K个大小相似的互斥子集,每个子集尽可能保持数据分布的一致性(分层抽样),然后分别以k1,k2……作为测试集,剩余K-1个子集作为训练集对模型进行训练,然后输出K个测试结果的均值。(K常见取值5,10,20)
留一法(Leave-One-Out简称LOO):交叉验证法的一个特例,即数据集D中包含m个样本,令K=m。留一法结果往往比较准确(因为训练集的大小与初始数据集相似,只差一个样本),但数据集比较大时,开销较大(需要训练m个模型)。
自助法:(减少训练样本规模不同造成的影响)给定包含m个样本的数据集D,对它进行采样(自助采样)产生数据集D‘。每次随机从D中挑选一个样本,将其拷贝放入D’,然后再将该样本放回初始数据集D中。这个过程重复执行m次,就得到了包含m个样本的数据集D‘,将D’用作3训练集,D\D’用作测试集。(在数据集较小,难以有效划分训练/测试集时很有用;自助法产生的数据集改变了初始数据集的分布,会引入估计偏差;在初始数据集量足够时,留出法和交叉验证法更常用一些)
验证集:模型评估与选择中用于评估测试的数据集称为验证集(一般用测试集上的判别效果估计模型在实际使用时的泛化能力,训练集数据另外划分为训练集和验证集,基于验证集上的性能进行模型选择和调参)。
性能度量 (衡量模型泛化能力的评估标准)
均方误差:样本学习器预测结果f(x)与真实值y差值的平方的均值(回归任务中最常用的性能度量)
错误率:分类错误的样本数占样本总数的比例;
精度:分类正确的样本数占样本总数的比列;
(错误率与精度分类任务中最常用的性能度量)
查准率:在预测结果为正例的样本中预测正确的比列。P=TP/(TP+FP)
查全率:在真实为正例的样本中预测为正例的比例。R=TP/(TP+FN)
F1:F1=(2*P*R)/(P+R)=(2*TP)/(样例总数+TP-TN)
混淆矩阵

P-R曲线:以查准率为纵轴,查全率为横轴作图,就得到了查准率-查全率曲线。
ROC:ROC曲线的纵轴是“真正例率”(TPR),横轴是“假正例率”(FPR)。
TPR=TP/(TP+FN), FPR=FP/(TN+FP);
AUC:ROC曲线下的面积即为AUC(用于评估学习器性能的好坏)
代价曲线:代价曲线图的横轴是取值为[0,1]的正例概率代价,纵轴是取值为[0,1]的归一化代价。(在非均等代价下,ROC曲线不能直接反映出学习器的期望总体代价,代价曲线可以)
代价曲线的绘制很简单:ROC曲线上每一点对应了代价平面上的一条线段,设ROC曲线上点的坐标为(TPR,FPR),则可相应计算出FNR,然后在代价平面上绘制一条从(O,FPR)到(1,FNR)的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC曲线上的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价。
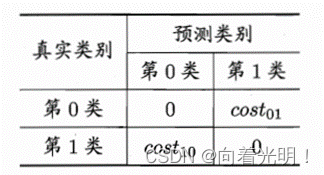
代价矩阵
二分类代价矩阵 (表示将第i类样本预测为第j类样本的代价)
偏差:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声:表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
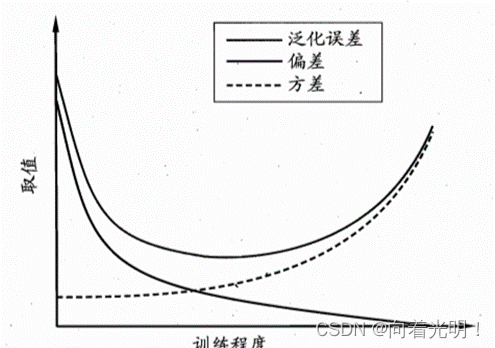
泛化误差可分解为偏差,方差与噪声之和。
偏差-方差分解说明,泛化性能是由学习算法的能力,数据的充分性以及学习任务本身的难度所共同决定的。
偏差-方差窘境:
五、模型评估常用指标
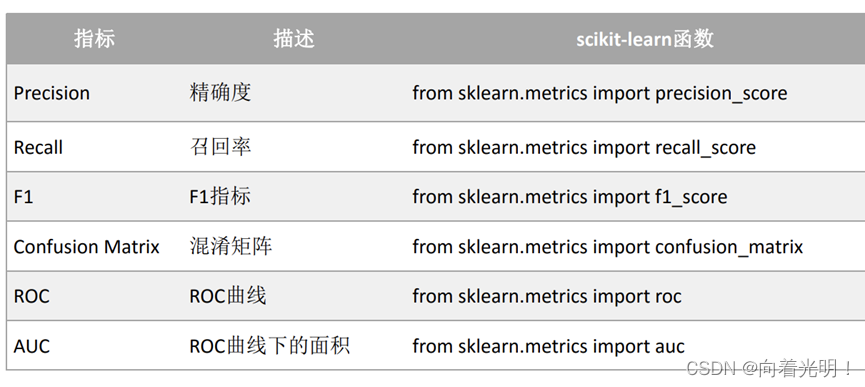
模型评估_分类算法评估方式:
模型评估_回归算法评估方式:
总结
并没有包含所有的概念,后面遇到了会继续补充,今天就先到这里
主要参考西瓜书和北风网的课件。















 3218
3218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









