






梯度下降法:该算法是一个一阶最优化算法,通过向函数上当前点对应梯度(或近似梯度)的反方向的规定步长距离点进行迭代搜索找到一个函数的局部极小值。
以一元函数为例说明梯度下降法:
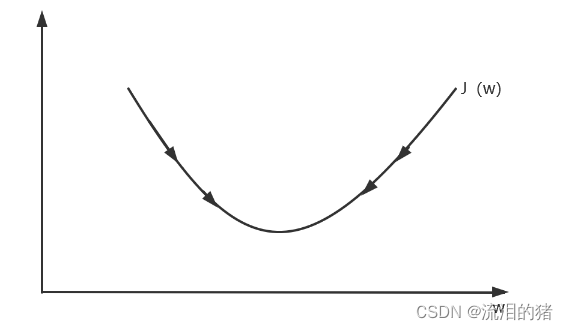
w的更新会朝着成本函数J(w)减小的方向更新,训练w就是不断重复以下过程:
重复{
}
:=表示更新,表示学习率,
是J(w)关于w的导数。
逻辑回归中的梯度下降:
在逻辑回归中,我们需要训练两个参数w和b。关于为什么是w和b,可以看上一篇文章深度学习理解和应用。
对于这两个参数需要重复{
}
表示成本函数J(w,b)对w求偏导。
怎样计算偏导数来实现逻辑回归的梯度下降法?
假设一个样本有两个特征,分别是x1和x2,则逻辑回归有以下步骤:
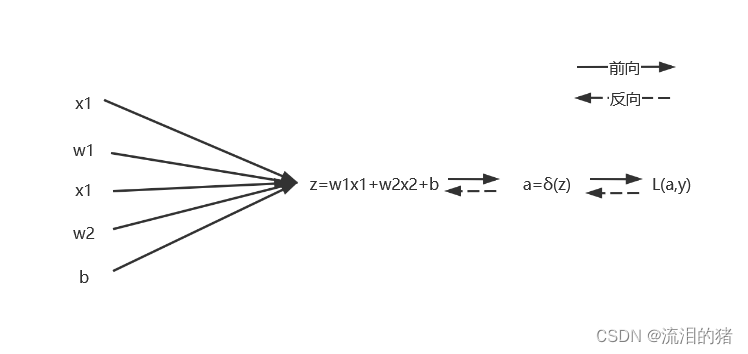
标注: ;
其中y是真实值,a是预测值。
在实现逻辑回归的算法中包括向前求预测值 a,以及利用损失函数L(a,y)反向更新w和b的过程。
更新公式为:
以w1为例更新时主要需要计算。计算公式如下:
注: 是sigmoid函数,对于sigmoid函数
因此
同理
根据以上公式即可计算参数的更新。















 8598
8598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









