






VAE模型
公式推导与实现
想要计算
p
(
z
∣
x
)
p(z|x)
p(z∣x) 即需要计算
p
(
x
)
p(x)
p(x),
p
(
x
)
=
∫
p
(
x
∣
z
)
p
(
z
)
p(x)=\int {p(x|z)p(z)}
p(x)=∫p(x∣z)p(z),计算相当困难。
变分推断:
通过一个简单的分布
q
(
z
∣
x
)
q(z|x)
q(z∣x)对
p
(
z
∣
x
)
p(z|x)
p(z∣x)进行近似,求q的参数,通过q进行计算。
KL散度:


最小化p和q的KL散度,推理后即最大化 ELBO(证据下界)目标函数(没推出来):
E
q
(
z
∣
x
)
l
o
g
p
(
x
∣
z
)
−
K
L
(
q
(
z
∣
x
)
∣
∣
p
(
z
)
)
E_{q(z|x)}logp(x|z)-KL(q(z|x)||p(z))
Eq(z∣x)logp(x∣z)−KL(q(z∣x)∣∣p(z))
第一项为重建的likelyhood,它衡量了样本 x 的重构质量,即通过解码器从潜在变量 z 生成 x 的能力。第二项为q和先验分布p的KL散度,衡量了潜在变量的后验分布与先验分布之间的接近程度。
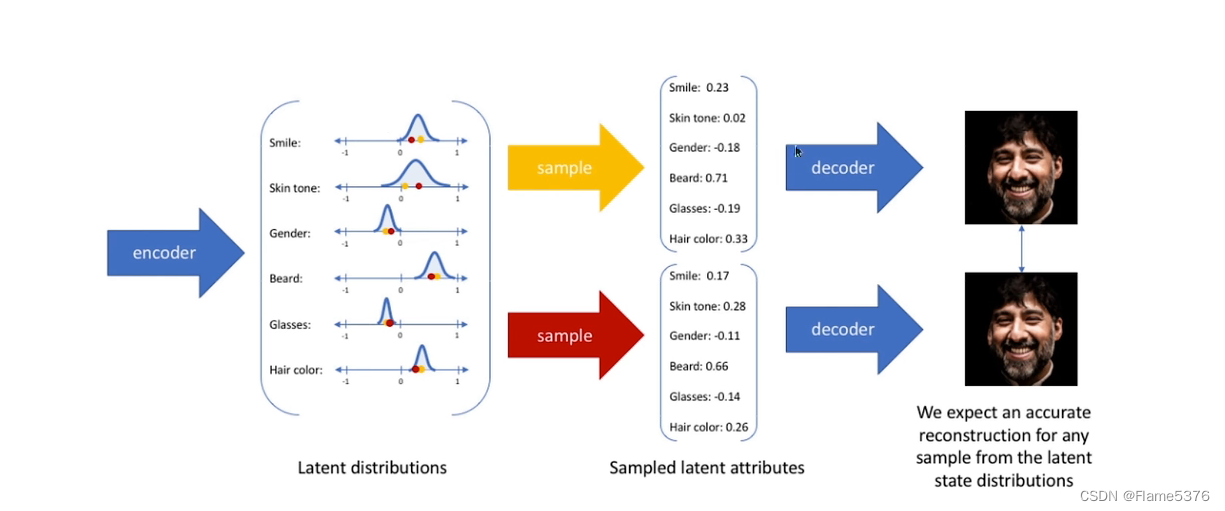
- 假设先验p(z)服从正态分布,输出两个向量来描述隐状态分布的均值和方差
- 解码器将通过从这些定义的分布中抽样来生成一个隐向量,并开始重建原始输入。
但是,在训练模型时,随机抽样操作不可微分,导致反向传播无法对模型进行更新。 - 解决方法:从单位高斯(均值为0、标准差为1)随机抽样ε,然后将随机抽样的ε乘以隐分布的均值μ,并用隐分布的方差σ对其进行缩放。

反向优化:
模型
输出为码m(均值)+方差σ(取exp为标准差,为正数),构成一个分布,从标准差中采样一个值(e,相当于噪声),生成一个新的带噪声的码c
c
=
m
+
e
x
p
(
σ
)
∗
e
c=m+exp(σ)*e
c=m+exp(σ)∗e

 loss约束:
loss约束:
除了重构损失外,还需要满足

e
x
p
(
σ
i
)
−
(
1
+
σ
i
)
exp(σi)-(1+σi)
exp(σi)−(1+σi)图像如下方绿色曲线,使其最小化,即σi趋近于0

为什么VAE
AE无法泛化生成能力,从码空间随机采样一个点生成一个值。

VAE与AE
在于自编码器(确定性)和可变自编码器(概率性)的区别。在普通的AE中,编码器将输入 x 转换为潜在变量 z,解码器将 z 转换为重构的输出。而在VAE中,编码器将 x 转换为潜在变量 p ( z ∣ x ) p (z∣x) p(z∣x)的概率分布,然后对潜在变量 z 随机采样,再由解码器解码成重构输出。
高斯混合模型(更新中)


参考文献和视频
根据论文内容进行的公式推导讲解:
[论文简析]VAE: Auto-encoding Variational Bayes[1312.6114]
详细的VAE理论推导和实现细节:
【干货】深入理解变分自编码器















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









