






Abstract
通过数据增强替换KL正则化
Intro
对比损失
缺点:
- 没有原则性的方法来选择反例,因此每次选择这些否定有些随意。
- 由于负样本来自其他训练示例,对比损失函数无法对训练示例进行细化分解
非对比方法
优势:
- 消除了对负样本的依赖
方法:
- 通过正则化或约束数据集级别的统计信息来避免显式负例
- 使用minibatch训练近似难以计算的数据集级别的统计信息
缺点:
- 需要大型 minibatch
- 使用批处理级统计信息意味着损失也不可分解
两种方法
都十分重视通过数据增强的方法来结合领域知识
VAE
自动编码
确保单个输入和表示之间存在大致上一对一的映射
这可以防止内部表示崩溃到单个点上,类似于对比学习中批量统计的正则化中的反例。
潜在空间正则化
确保内部表示在语义上排列在紧凑的空间中。
这在对比和非对比方法中执行类似于数据增强的作用,但不同之处在于它与输入域无关。
第三类自监督学习算法
定义:通过数据增强来增强变分自动编码器
AASAE
通过基于特定领域的数据增强去噪准则来代替KL散度
优势:
- 损失函数不依赖于批量级别的统计数据,因此能够使用较小的小批量
- AASAE 不需要任意选择负采样策略。
自监督
代理任务
代理任务旨在预测输入的非平凡但容易适用的转换方式
如:
- 图像旋转来预测旋转角度
- 将图像转换灰度来恢复颜色
总结:虽然很好的解决了原始的代理任务,但是下游任务做不明白
对比学习
总结:好用但需要大量负例
非对比学习
旨在通过依赖数据级别或批次级别的统计数据来学习没有负样本的良好表示
分两类,基于聚类的和基于蒸馏的
AASAE
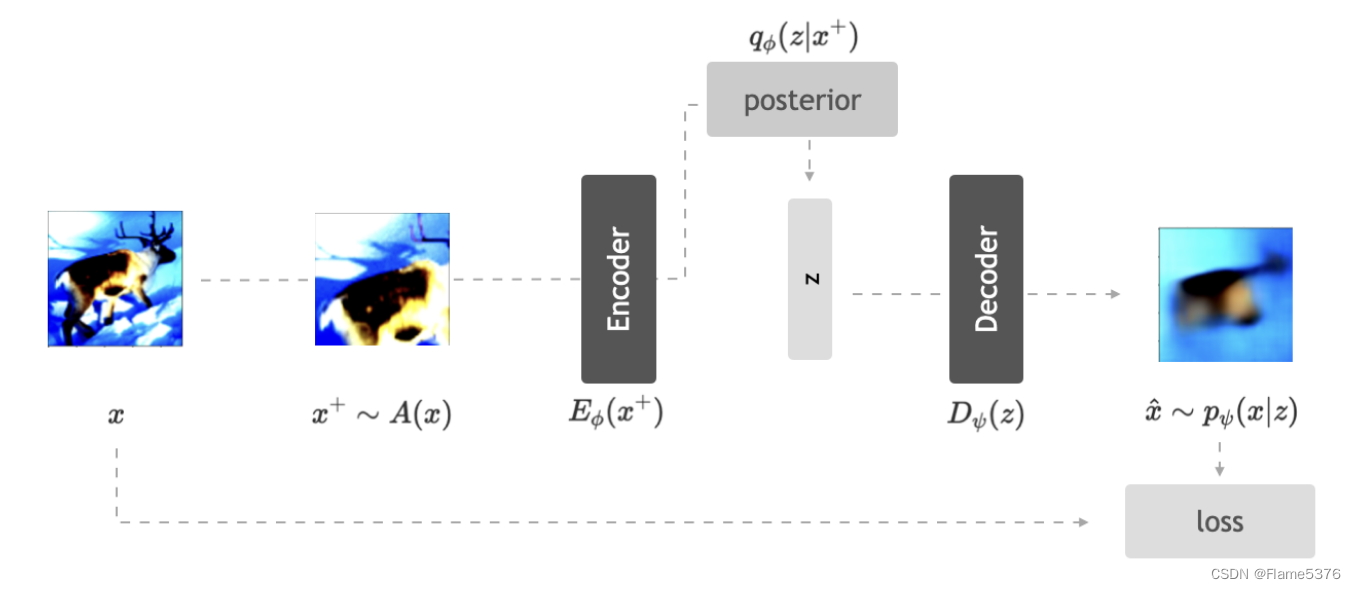
VAE
三种机制:
- 自动编码
- 采样
- 最小化KL
但以上都和域无关(domain-agnostic)
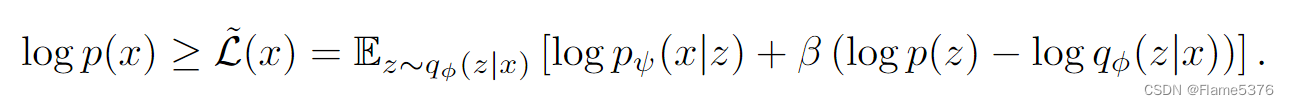
重构有两个目的:
- 最小化了重建误差,这鼓励 VAE 的中间表示对于每个观察或多或少是唯一的。换句话说,它确保输入的内部表示不会相互崩溃。
- 表示为对近似后验的期望,是通过确保对表示的微小扰动不会显着改变解码的观察来使表示空间平滑。
KL目的:
确保数据分布下任何观察的表示很可能在先验分布下。先验分布通常构造为标准正态分布,这意味着概率质量高度集中在原点附近(尽管不一定在原点上)。这确保了来自观察的表示根据它们的语义紧密排列,而不依赖于任何领域知识。
AASAE
- 通过数据增强代替了第一个机制,并由此引入了特定领域的知识
- 删除了第三个机制,认为KL在表示学习中没有嵌入特定领域的信息
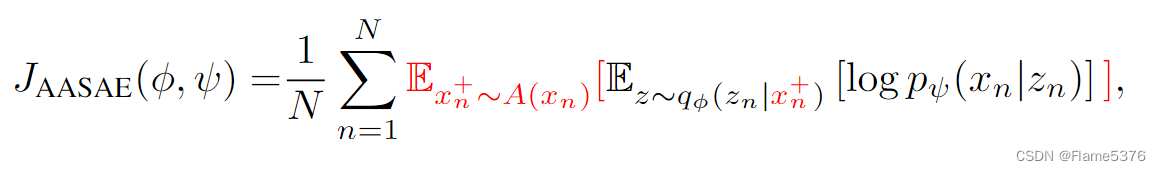
A为随机过程/增强方式
方法:
强制 AASAE 的编码器将每个示例的不同视图的表示彼此靠近
即从全局打包(KL的先验)变成了局部打包,特定领域的转换定义了局部;同时域感知转换可以通过训练填充样例间的差距,间接实现了全局打包的目标
优势:
AASAE的loss在样例级别分解,避免了数据级的统计的逼近和梯度计算;可以知道自己在算什么















 5494
5494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









