






目录
Abstract
问题:
- 大多数聚类分布高度依赖设定的非线性映射得到的中间目标分布
- 聚类结果很容易收到每个簇中错误分配的样本的影响,导致错误。现有的深度聚类方法无法区分这些样本。
提出了一个 “self-supervised clustering framework, which boosts the clustering performance by classification in an unsupervised manner”
用到了模糊理论来给训练时期的每个样本属于簇的概率评分。
根据隶属度选择方法选择最可靠的样本,并进行数据增强。
增强后的数据通过自监督的方式,使用聚类提供的labels来微调现成的深度网络分类器。
原始数据的分类结果作为目标分布来指导深度聚类模型的训练
结果:
- 模型可以优先区分样本异常值,通过强大的分类器生成更好的目标分布
Intro
实际应用中,标记数据可能会很困难或昂贵,或者有些不可见的类别或模式,也缺少监督信息
结论:目前聚类没法从分类中受益
目前深度聚类模型的弊端:
- 用于优化深度聚类模型中的DNN和聚类中心的目标分布高度依赖于人工设计的分布函数;如何自动生成适合特定数据集的目标分布仍然是一个待解决的问题;深度聚类模型以自训练的方式进行训练,这使得自校正成为不可能,限制了能达到的最佳性能。
- 其次,样本的错误分配在聚类中是不可避免的,可能导致聚类朝着错误的方向发展。如何为每个聚类选择置信样本,减少可能的错误分配的影响,以指导聚类到正确的方向是另一个未解决的问题。
“misassignment in each cluster can turn small mistakes in the cluster distribution into big mistakes in the target distribution.”
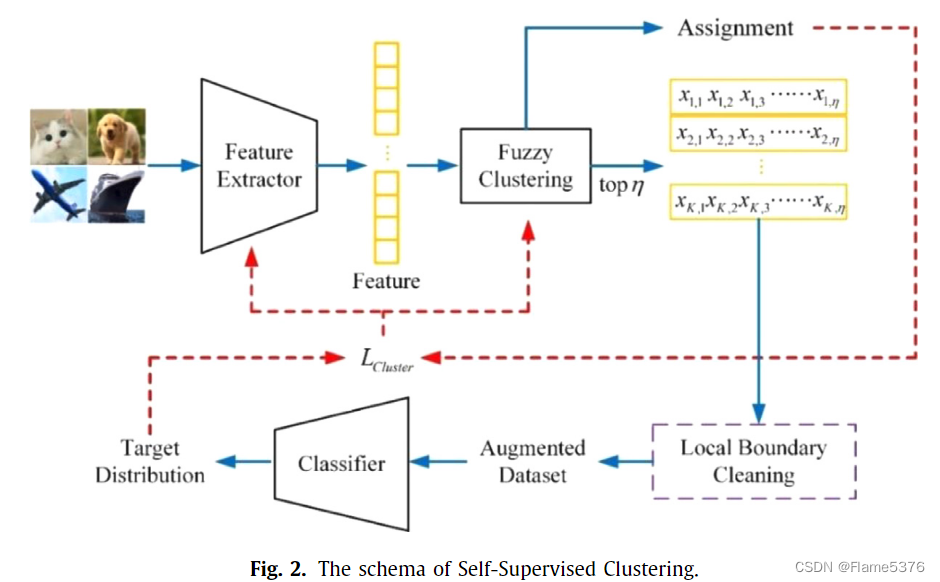
开发了一个自监督聚类(SSC)框架,结合了特征提取器、聚类层、样本选择模块和分类器四个模块
特征提取器
AE或现成的(off-the-shelf)深度模型
聚类层
模糊聚类(Fuzzy Clustering),可以给出样本属于聚类的置信水平
样本选择模块
选择置信样本,发现并排除可能错误分配的样本
对样本尽心随机旋转、裁剪、剪切等增强
分类器
带有伪(pseudo)标签的增强置信数据被送到分类器,使用中间聚类结果训练目标分布生成模型。现成的网络模型被用作分类器,其中不需要外部监督数据的信息进行聚类。分类器由增强数据进行微调,然后用于生成样本的目标分布来聚类。
目标分布生成块是一个可训练神经网络模块,更可靠和自适应,而不是手动定义的。
由此,聚类模型从分类器得到启发,以自监督的方式进化。
自监督聚类
所提出的聚类框架可以以端到端的方式进行训练
- 原始数据
- 征提取器
- 模糊聚类(分配给不同聚类,对样本置信度进行评分)
- 数据增强,被称为模糊选择策略和增强
- 对现有的分类器进行训练
- 局部边界清理只参与初始阶段,由于原始特征提取器聚类不友好,所以模糊选择策略后会在对样本进行一次选择
- 分类器通过中间聚类标签以自我监督的方式进行微调
- 使用分类器自动预测目标分布
模糊选择策略
目标:为后面的分类增强模块选择高置信度样本
特征提取器提取的特征不是聚类友好的,导致簇可能在特征空间有重叠。
样本到聚类中心跃进,越有可能分配正确,因此,样本应该靠近聚类边界的地方。
FCM(Fuzzy c-means)
公式表示第i个样本点对第j个中心的隶属度,m>1 是模糊器(通常选择2),K 是集群的数量:
这个值是个介于0到1的数,所以相当于一个权重,m越大,隶属度差异越小,一个点属于不同聚类的程度越近
这个有点像目标分配,但是是个矩阵

初始化聚类层目标函数,通过更新隶属度矩阵和聚类中心矩阵:
公式衡量了聚类质量,前一项为权重,后面为距离,m越大,聚类的边界越模糊,其实实验中取1.1,1.4,已经很小了,有点像硬聚类了,感觉体现不太出来他这个模糊的作用。

更新聚类中心:
新的聚类中心是所有数据点的加权平均值,权重是其隶属度的m次幂。这意味着对聚类中心贡献更大的数据点是那些具有更高隶属度的数据点。
分子是数据点根据对该聚类中心的隶属度的和,对该点隶属度高的,会对该中心影响大
分母是确保聚类中心是隶属度加权后的均值位置

模糊选择策略
对于非凸目标函数,模糊聚类层的初始化是不稳定的,因此构造了模糊选择策略(FSS)。
非凸函数可能有多个局部最小值,算法可能会收敛到其中之一。
在基于相同输入和模糊器值的 M 次重复试验之后,得到 M 个成员矩阵。每个样本的对应标签是隶属度最大的聚类中心。将第一次试验的结果作为基线,以acc为基准将其与剩余的 M-1 预测进行比较。选择最频繁的结果作为聚类中心 μmax 的最稳定初始化。然而,当样本量较大时,FCM的优化难度较大,每次试验的结果(acc)不相同。但acc结果之间的差异并不大,因此设置一个容忍度ψ来合并相似的聚类效果,如下公式,是一个指示函数:
ComAcci是第i个比较精度,即基线和试验i的结果之间的精度差异。如果两次试验的指标为 1,将两次试验视为相同的试验:

聚类层最稳定的初始化可以通过投票得到为(具有最多相似的实验)

局部边界清理和增强
尽管模糊选择策略选择的样本应该具有很高的置信度,但在特征提取器和更新聚类层之前,所选样本中可能存在一些错误分配的样本,并且该现象严重(即初始阶段)。所以需要对高置信度样本做一次重新筛选(清理),限制错误分配的负面影响
经过tsne观察错误聚类

需要将高置信度样本聚类再K1中
LBC(Local Boundary Cleaning):
- 为了避免“岛”的问题(K2),引入密度聚类(DBSCAN),检测在二维tsne映射是否有两个或更多类簇,若有则删除小的簇,其余数据表示为Oi(K0∪K1)
- 修理K0区域,即椭圆边界,以消除可能错误的聚类。椭圆的长轴和短轴向量VL和VS满足:
其中 λL 和 λS 是样本协方差矩阵的相应特征值。

虚线椭圆K0长轴、短轴为

在此基础上,可以得到K1椭圆长轴和短轴的长度(即实线)为κRL和κRS,其中κ是控制K1面积大小的标量参数。相应地,K1椭圆的函数可以表示为:
t ∈ [0, 2π],vL,1 vL,2是VL两个轴的分量

在第一个训练时期之后,LBC 不再参与样本选择,剩余 epoch 的选择策略只是top η 选择策略。
数据增强
论文中提到的都是图像的增强方式:随机旋转,剪切等,增加可靠样本
自监督分类器
用的是原数据+(fcm+选取+局部清理+数据增强)得到的label,输入到现成的分类器进行训练
分类器被引入来实时预测目标分布。上面获得的增强数据集用中间(intermediate)聚类结果作为标签。这些标签被用来作为监督信息来微调分类器。
即分类器以自监督的方式进行训练,不需要外部监督,其实也算一种无监督的方案。
分类器的输入数据是包含比用于目标分布生成的嵌入特征更多的信息的原始图像。原始图像输入使得目标分布的生成不依赖于聚类友好特征提取器。
特征嵌入过程中的信息丢失可能会扭曲特征空间中的样本分布,这可能会影响获得的目标分布。解决方案是通过学习目标分布生成的最佳特征来避免此类问题。

P是one-hot的label矩阵,通过编码,属于同一类的样本分布会更加紧凑。
聚类目标函数为:

U是隶属度的矩阵,P是分类器结果label。最小化聚类损失,可以优化特征提取器fFE和模糊聚类层fFC的参数
优化
优化过程分为两部分
- 模糊选择后,选定的高置信度样本输入到分类器,此时选择的样本具有伪标签(可能是错误的)。用KL散度作为分类损失来训练分类器:

第一项为伪标签向量,从ground truth取;第二项为预测结果,对应的参数更新:

αC 是学习率
n′C 是批量大小
ωC 表示网络的参数
在训练期间,因为一些错误分配可能会在选定样本中混合,会影响梯度下降训练,因此没必要追求很高的精确度acc或非常小的分类器损失,防止过拟合,因此分类器训练需要相对较少的epoch。
有两种可能导致错误分配的情况:
(1) 特征提取器不是聚类友好的,使得特征空间出现重叠
(2)若聚类曾无法检测所有模式,则可能存在一个或多个无效的聚类,其中个包含的样本都被错误聚类。
聚类层和特征提取层会一起优化,且共享学习率和batch size,参数优化如下


其中 ωFC是特征聚类参数,ωFE是特征提取器参数,α是学习率,n′是训练批次内的样本数。
如果训练整体 SCC 的两个成功迭代之间的预测分类器标签的变化小于小阈值 δ,则停止 SCC 训练过程。停止标准定义为

其中Pt和Pt-1是迭代t和t-1中的两个连续预测目标分布,N 是来自训练的样本总数。在停止迭代得到的Pt=stop作为目标分布,生成最终的聚类结果。
考虑到样本选择策略,最大迭代次数Nmax可表示为

算法:

参数设置
MNIST、USPS、STL10 和 CIFAR10 的模糊器值分别设置为 1.4、1.4、1.1 和 1.1。
AE:d-500-500-2000-10
停止标准阈值设置为 δ=0.01%
初始样本选择率 η0 为 40%















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









