






人工智能 Artificial intelligence AI
通用人工智能 Artificial General Intelligence AGI
早期机器学习发展时间线:感知机模型-》决策树模型-》贝叶斯算法-》集成学习算法-》。。。
感知机模型
分布式知识表达
神经网络反向传播
神经网络
感知机
线性可分问题
根据输入数据学习特征权重的模型 根据输入数据样本特征自动更新特征权重的模型 ——早期感知机模型。解决了神经网络权重需要人工进行设置的问题。
感知机 Perceptron
决策树学习
ID3算法 Iterative Dichotmiser 3 决策树模型的最早期算法形态
C4.5
CART算法 Classification and Regression
贝叶斯算法
深度学习技术
自然语言处理
计算机视觉
朴素贝叶斯算法
贝叶斯定理 现代数学形式的阐述
条件概率
集成学习算法
集成系统 Ensemble system
线性分类器
最近邻居分类器
弱学习器:性能略优于随机猜测的学习器,如KNN、线性回归模型
KNN
线性回归模型
Boosting算法
Bagging算法 Bootstrap Aggregating
Stacking算法 堆叠泛化
早期感知机模型的弊端:只能处理线性可分问题。计算机硬件技术水平无法在计算层面支撑庞大结构神经网络的高性能计算。
ID3算法Iterative Dichotomiser 3 是决策树模型的最早期算法形态。使用信息增益作为树模型递归分类建造的标准,通过递归算法选择呈现最大信息增益的特征来构建一个树模型,用于解决常见的分类问题。
ID3算法的弊端:不能解决回归类问题建模。只能按照特征取到的多种不同值来对样本进行划分,而对分类问题中更常见的二分类问题求解效果不好。无法处理分类任务中样本数据呈现的连续性特征。
随后的改进算法C4.5算法、CART算法等,使决策树模型发展成为早期机器学习范式中性能优良的模型,至今仍有大量应用市场。
条件概率-》贝叶斯公式雏形-〉贝叶斯定理、现代数学形式的阐述-》朴素贝叶斯算法
朴素贝叶斯算法可以通过统计已知文本数据中的特征分布来估计类条件概率,给出新样本类别的概率分布结果。朴素贝叶斯算法假设样本的各个特征彼此之间是相互独立的,这种假设简化了复杂的计算过程。
感知机理论-》决策树-〉贝叶斯-》线性回归-〉逻辑回归-》SVM-〉集成学习模型。。。
早期传统机器学习方法弊端:只能解决小规模的现实问题,而现实需要解决的问题逐渐复杂化,机器学习模型所需数据量增大,受制于机器学习方法模型规模微小,达到性能瓶颈,如早期图像分类任务有一段时间是使用SVM支持向量机实现,而图像分类任务中对图像数据处理很复杂,生成的图像特征相关矩阵维度低、表征能力若,且SVM在图像分类任务上做非线性分类效果不好,且图像识别准确率低。即传统机器学习方法无法求解更复杂的问题规模(算法技术问题);所需求解问题更复杂,模型构建所需数据量级增大,服务器硬件设备价格高CPU、GPU、存储设备,且服务对外提供方式?有限,性能差,无法满足大量数据高性能存储和计算。即半导体芯片制造业技术落后芯片算力不足,AI算力对外提供服务成本高,缺乏大量数据高性能存储与高效计算解决方案(硬件设施设备问题);研究者们期待神经网络技术改善传统机器学习方法构建模型的性能问题。
SVM
向量机
图像特征的矩阵维度
图像特征的表征能力
图像识别准确率
Computer Vision计算机视觉技术(CV)
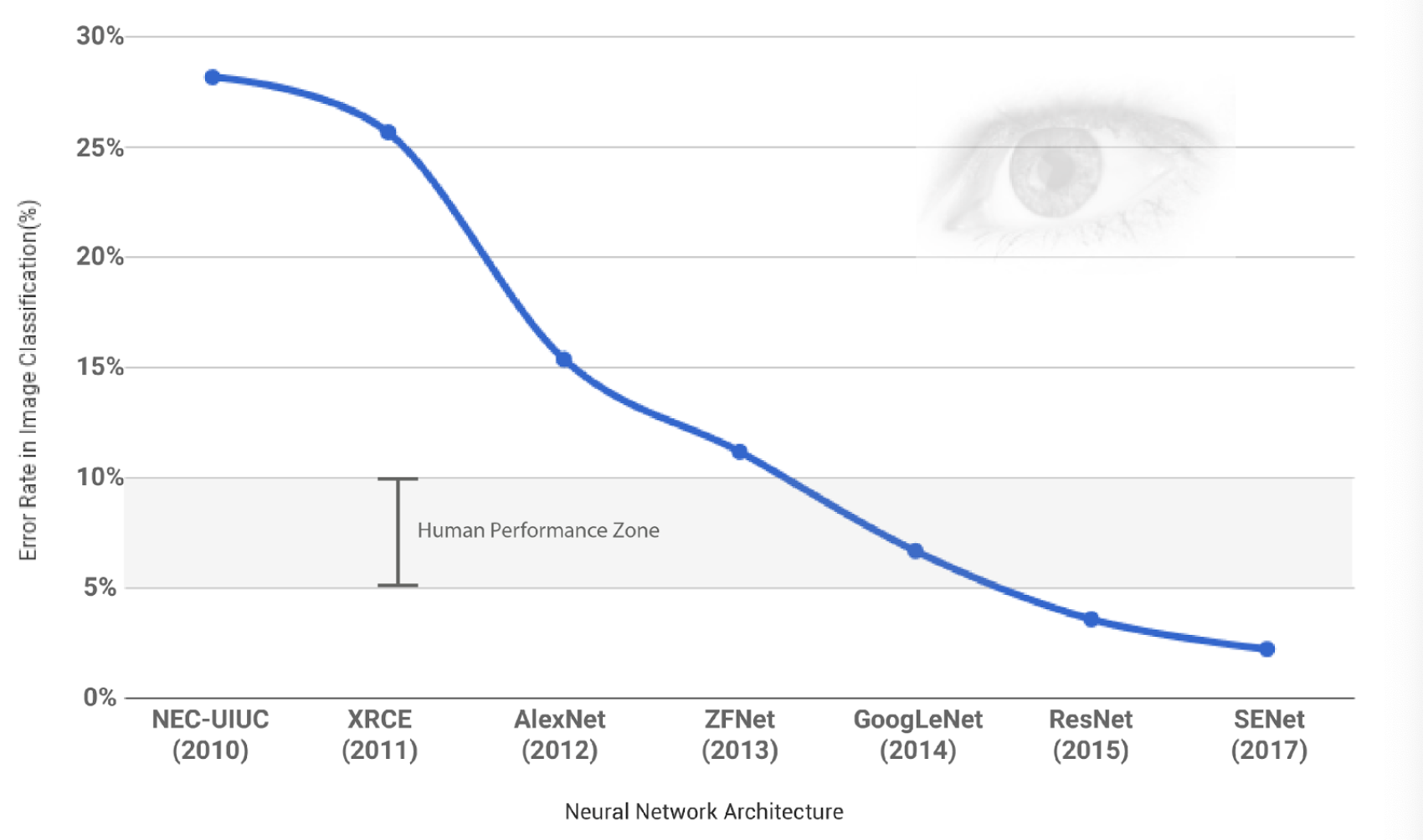
论文:2012年 ImageNet Classification with Deep Convolutional Neural Networks 多伦多大学辛顿实验室 深度卷积神经网络AlexNet 深度8层(5 Conv,3 fc) 在图像分类数据集ImageNet上达到15.3的Top5错误率
Conv
fc
三位联名作者
Geoffrey E. Hinton(辛顿)深度学习之父 2018图灵奖 IJCAI杰出学者终生成就奖 多伦多大学辛顿实验室 提出 深度学习领域的技术:反向传播算法、Dropout正则化、玻尔兹曼机
反向传播算法
Dropout正则化
玻尔兹曼机
Ilya Sutskever(伊尔亚·苏茨克维)
OpenAI 联合创始人之一 辛顿学生
Yann André Le Cun(法国人,杨立昆)
卷积神经网络发明者 辛顿学生 2018年和辛顿一起获得图灵奖
论文提出新的深度卷积神经网络,开创性地提出:双GPU并行训练深度卷积神经网络。提出新的卷积运算方法:分组卷积,是AI大模型领域广泛采用的分布式并行计算的早期理论与实践的雏形。两张显卡GTX580显卡,单卡显存3GB,跑8层深度卷积神经网络AlexNet训练。提出ReLU激活函数,奠定了之后近10年激活函数的基本设计与迭代。提出Dropout正则化技术,一直沿用至今。提出局部相应归一化LRN等技术。
AlexNet不足:增加网络的深度提升视觉模型的性能,但达到一定深度,网络产生退化,即无法利用神经网络解决更复杂的现实问题。
论文:2015年 Deep Residual Learning for Image Recognition 微软亚洲研究院四位中国学者联名发表
何凯明
论文提出神经网络模型ResNet残差神经网络
残差神经网络 2015年ImageNet大规模视觉竞赛ImageNet Large Scale Visual Recognition Challenge ILSVRC 获图像分类和物体识别冠军 Top5错误率3.75% 人类双眼图像识别Top5错误率5%-10% 第一个超越人类视觉生理极限的视觉模型
ResNet开创性地在CNN卷积网络中加入残差块的设计,使网络具有输入记忆的能力,最终ResNet得以设计出很深的深度,彻底解决卷积网络的深度退化问题
孙剑老师
旷视科技首席科学家 西安交通大学人工智能学院第一任院长
CNN卷积网络
ResNet解决了网络加深后的退化问题-》深度异常庞大的CNN网络变体:Inception V3/V4、ResNet-152、VGG、SENet。。。,CV视觉领域目标检测、图像搜索、智能辅助驾驶。。。
传统的CV视觉模型弊端:功能垂直化、单一化,无法应对复杂的视觉任务。AI技术领域进入多模态发展阶段,而CV视觉模型仅能处理图像仅能图生图的无法满足当下需求。
Natural Language Processing 自然语言处理技术NLP
1950 艾伦·图灵 图灵测试 测试计算机能否通过对话进行自然语言理解
1954 IBM IBM机器翻译系统 早期NLP的重要里程碑
1970 知识驱动方法 使用知识库和语义网络处理自然语言 基于规则的方法不太行了 算力有限 NLP进入低谷
1986 Michael I. Jordan Recurrent概念 构建Jordan Network
1990 Jeffrey L. Elman 简化Jordan Network 全连接RNN模型:Elman Network 使用反向传播算法 Back-Propagation BP训练 RNN:专门处理序列数据的网络结构 还未用于自然语言处理技术实现
RNN 循环神经网络,Recurrent Neural Network 是一种专门用于处理序列数据的神经网络架构。它的核心特点是具有**“记忆”能力**,能够通过内部的循环连接保留之前输入的信息,从而对序列中的时序依赖关系进行建模。
1991 Sepp Hochreiter RNN处理长序列时存在长期依赖问题 梯度消失gradient vanishing 梯度爆炸gradient explosion RNN在长序列数据表现受限
1997 Jurgen Schmidhuber 长短期记忆网络Long Short -Term Memory networks LSTM 门控制机制 遗忘门 输入门 输出门 缓解RNN长期依赖问题
1997 Mike Schuster 双向RNN Bidirectional RNN Bi-RNN 体统RNN对序列数据的处理能力
1998 Williams和Zipser 随时间反向传播Backpropagation Through Time BPTT沿时间梯度反向传播算法 允许RNN按时间序列展开 通过反向传播算法更新权重 实现对RNN的有效训练
后10年RNN及变体LSTM、GRU在自然语言处理NLP、语音识别、时间序列预测,,广泛应用 深度学习技术领域对NLP技术影响深远
2013 Google Word2Vec模型 奖单词映射到低维向量空间 捕捉单词间语义关系
2014 编码器-解码器Encoder-Decoder解决机器翻译问题 深度学习模型框架
2015 2016 基于RNN算子的NLP技术高速发展
不满足于机器翻译单一垂直模型 想文生文 文生图 智能问答 文生视频
Generative Models 生成式模型技术
过去隐马尔可夫模型HMMs 高斯混合模型GMMs 最早用于生成序列数据的生成式模型语音时间序列
2013 变分自编码器VAEs 基于概率生成模型的生成方法 学习数据的潜在分布式生成新样本 图像生成 有着强大的生成能力
2014 生成对抗网络GANs 生成器和判别器对抗性训练 生成高度逼真的图像音视频。。生成式模型技术重大突破
换脸应用
可图生图 文生文
想文生图 CV、NLP、生成式模型融合实现?
机器学习新范式技术:半监督学习、自监督学习、强化学习、迁移学习
机器学习范式:有监督学习、无监督学习、半监督学习、自监督学习、强化学习、迁移学习
有监督学习:有监督分类、有监督回归
无监督学习:无监督聚类、无监督降维
半监督学习:生成式方法、一致性正则化方法、基于图方法、伪标签方法、混合方法
自监督学习:对比学习、生成学习
强化学习:基于值的强化学习算法、基于策略的强化学习算法
迁移学习:基于样本、基于特征、基于模型、基于关系
深度学习:有监督分类、有监督回归、无监督聚类、无监督降维、生成式方法、一致性正则化方法、基于图方法、伪标签方法、混合方法、对比学习、生成学习、基于值的强化学习算法、基于策略的强化学习算法、基于样本、基于特征、基于模型、基于关系
有监督学习范式:根据给定样本特征,通过算法模型,从样本特征中学习表征,得到某些指定的预测结果(标签)
无监督学习范式:数据集无需包含标签,直接对样本数据操作
半监督学习范式:先标注小部分数据,机器学习表征,在剩余大部分数据自动标注或任务建模
自监督学习范式:特殊的无监督学习范式,直接利用数据本身宗纬监督信号训练模型,通过设计辅助任务pretext task挖掘数据自身表征,提升模型特征提取能力
强化学习:Reinforcement Learning RL再励学习、评价学习、增强学习,智能体agent与环境交互过程中通过学习策略达成回报最大化或实现特定目标
迁移学习:Transter Learning,利用学到的知识加速或改进另一个相关任务或领域的学习过程
深度学习与机器学习:深度学习属于机器学习的一个分支技术领域,是指基于深度神经网络模型开展各个机器学习方法
DNN、CNN、RNN 可用于有监督分类模型构建
GANs、VAEs 可用于无监督范式下的生成式模型 可用于半监督范式下的模型构建
迁移学习是在一些完成预训练的神经网络上进行迁移,让模型拥有学习其他特征域的能力
人类反馈强化学习 大模型RLHF流程是大模型微调精准匹配下游任务需求的关键性技术
大模型是各种小模型作为工具辅助完成的大模型训推
few-shot 少样本学习
zero-shot 零样本学习
海量浮点数运算过程-》高性能计算芯片-〉分布式集群算力-》大数据技术-〉数据的存储管理 分布式并行计算-》云计算虚拟化技术-〉智能无损以太网技术-》分布式存储-〉高速内存
半导体芯片制造 云计算虚拟化技术 大数据平台构建 分布式存储技术 智能计算技术 高带宽无损网络通信技术
AI算力技术 Nvidia 昇腾全栈AI软硬件平台
Atlas人工智能计算平台:集群、服务器、加速卡、智能小站、IA加速模块、开发者套件 昇腾推理AI处理器 昇腾训练AI处理器
目前国内AI大模型软件技术栈主要是开源深度学习框架PyTorch Tensorflow DeepSpeed FlashAttention,AI大模型硬件算力主要是Nvidia系列专用GPU
大模型基于涌现能力之上,可以仅通过优质的提示功能即可实现接近于Few-shot的学习能力
涌现能力
提示工程
大模型Large Models是指拥有超大规模参数(通常在十亿个以上)、更复杂结构的机器学习模型,能够处理海量数据,完成各种复杂任务,如自然语言处理、图像识别等
大模型参数量大、网络模型结构大、基座预训练微调训练所需数据量大、所需算力大
大模型分类
2017 Transformer
2018 Google Bert
2018 OpenAI GPT1
2019 OpenAI GPT2
2020 OpenAI GPT3
2022 OpenAI ChatGPT
LLAMA、ChatGLM、盘古、星火
大模型分类维度
技术架构层面:Transformer系统架构、MoE架构
多模态能力层面:图像生成大模型、视频生成大模型、文本生成大模型、语音生成大模型
功能实现层面:LLMs大语言模型、视觉语言模型
行业应用场景层面:基础大模型(大模型基座)、行业垂直大模型、场景大模型
大语言模型LLM
2017.6.12 Google 机器翻译团队 《Attention is All You need》 注意力机制Attention Transformer架构:基于多组编码器Encoder、解码器Decoder构成的大型语言模型基座
仅使用编码器Encoder的预训练模型 如Bert家族
尝试“无监督预训练”方式获得大规模自然语言数据。无监督即Masked屏蔽的Language Model(MLM),通过Mask掉句子中的部分单词,让模型学习使用上下文预测被Mask掉的单词的能力。在情感分析、命名实体等自然语言处理常见任务中刷到SOTA。主要代表:谷歌的Bert、ALBert,百度的ERNIE,Meta的RoBERTa、微软的DeBERTa...但Bert未能突破Scale Law模型性能上限。
仅使用解码器Decoder的预训练模型 如GPT家族
扩大语言模型可以显著提高零样本zero-shot与小样本few-shot学习的能力
GPT家族基于给定前面单词序列预测下一个单词来进行训练,最初仅作为文本生成模型出现,GPT-3转折点,超越文本生成,是自回归语言模型。其后ChatGPT、GPT-4、PaLM、LLaMA。
自回归语言模型:Autoregressive Language Model AR LM是一类基于概率链式法则的生成模型,核心思想是按顺序逐次或逐token预测文本,每一步的预测都依赖于之前已生成的文本。
【Paper】Harnessing the Power of LLMs in Practice:A Survey on ChatGPT and Beyong
梳理了近些年陆续发布的各个大模型基座及其开、闭源大模型产品,用一棵树展示大模型发展历程
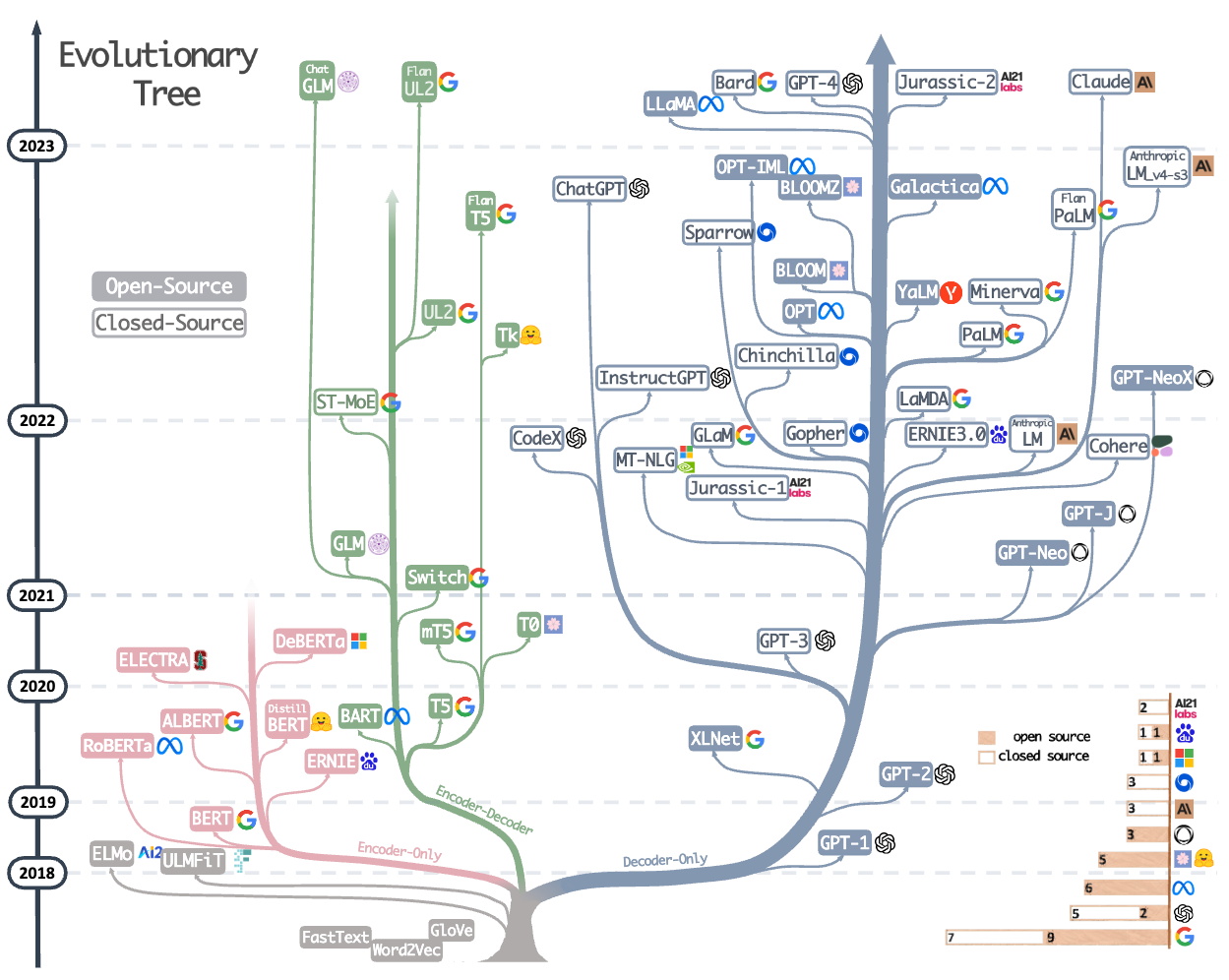
Summary of Large Language Models
1、大模型基座架构
Encoder-Decoder or Encoder-only(BERT-style)
编码器-解码器架构 或 仅编码器架构 BERT风格
Characteristic
Training:Masked Language Models 训练:屏蔽语言模型
Model type:Discriminative 模型类别:判别式
Pretrain task:Predict masked words 预训练任务:预测屏蔽词
LLMs
ELMo [80],BERT [28],RoBERTa [65], DistilBERT [90],BioBERT [57],XLM [54], XInet [119],ALBERT [55],ELECTRA [24], T5[84,GLM[123],XLM-E[20],ST-MoE[133], AlexaTM [95]
2、大模型基座架构
Decoder-only(GPT-style)
仅解码器 GPT风格
Training:Autoregressive Language Models 训练:自回归语言模型
Model type:Generative 模型类别:生成式
Pretrain task:Predict next word 预训练任务:预测下一个词
LLMs
GPT-3[16],OPT[126].PaLM[22], BLOOM [92],MT-NLG [93], GLaM [32],Gopher [83],chinchilla [41], LaMDA [102],GPT-J [107],LLaMA [103], GPT-4 [76],BloombergGPT [117]
仅解码器Decoder-only逐渐主导LLMs开发
2021 GPT-3 LLMs转折点
2022.11 OpenAI发布GPT-3.5大模型基座,发布ChatGPT3.5大模型产品
2023.3 OpenAI发布GPT-4大模型基座,发布ChatGPT4大模型产品
2024.5.14 01:00 OpenAI发布最新GPT4o全模态大模型,后续GPT4o大模型产品
2024.7.24 MetaAI(Facebook)发布开源LLM:LLaMa 3.1 405B
2024.5 中国巨头幻方量化旗下的杭州深度求索公司(届时成立一年,发布DeepSeek v2 236B模型,当时全球最大的开源MoE架构大语言模型,创新引入DeepSeek自研的开源DeepSeek MoE架构,以更细粒度的MoE专家分割与共享专家隔离技术领跑整个开源MoE架构大语言模型技术。
MoE架构:MixTure of Experts混合专家模型。通过动态组合多个子模型(专家)来处理不同输入数据的神经网络架构。核心思想是:分而治之,每个输入仅由部分专家处理,从而显著提升模型容量和计算效率。
2024.12.26 深度求索发布DeepSeek V3基座模型 自研的全新MoE架构语言模型 参数达671B 每个token激活37B参数
2025.1 DeepSeek发布DeepSeek R1,基于V3 Base经过RL训练深度推理模型。创新的RL强化学习训练技术
RL训练:Reinforcement Learning强化学习
国产:DeepSeek 智谱AI 前文大模型 文心一言 腾讯混元 华为盘古
视觉生成大模型
视觉生成大模型:Vision Generative Models,基于深度学习的大规模参数化模型,能根据输入条件如文本、图像、草图等生成高质量、多样化视觉内容如图像、视频、3D模型等。应用领域如图像合成、视频生成、跨模态理解。。。
2024.3 OpenAI以外泄漏全新视频生成大模型Sora,促使OpenAI在github开源Sora大模型源码,开源项目:open sora
https://github.com/hpcaitech/Open-Sora
open sora开源模型的推理部署,使用云端算力RunPod,博客
多模态/全模态大模型
2024.6.21 华为发布 盘古5.0 万亿参数全模态大模型
盘古5.0重点升级:全系列、多模态、强思维
全系列:盘古大模型5.0包含不同参数规格的模型,以适配不同的行业场景。十亿级参数的Pangu E系列可支撑手机、PC等端侧的智能应用;百亿级参数的Pangu P系列,适用于低时延、高效率的推理场景;千亿级参数的Pangu U系列使用与处理复杂任务;万亿级参数的Pangu S系列超级大模型能够帮助企业处理更为复杂的跨领域多任务。
多模态:pangu大模型5.0能更好更精准地理解物理世界,包括文本、图片、视频、雷达?、红外?、遥感?等更多模态。在图片和视频识别方面,可支持10K超高清分辨率;在内容生成方面,采用业界首创的Spatio Temportal Controllable Generation STCG 可控时空生成技术,聚焦自动驾驶、工业制造、建筑等多个行业场景,可生成更加符合物理规律的多模态内容。
强思维:复杂逻辑推理是大模型称为行业助手的关键。盘古大模型5.0将思维链技术与策略搜索深度结合,极大地提升了数学能力、复杂任务规划能力以及工具调用能力。
盘古大模型L0基础大模型
自然语言大模型、多模态大模型、视觉大模型、预测大模型、科学计算大模型
盘古大模型L1行业大模型
矿山大模型、政务大模型、气象大模型、汽车大模型、医学大模型、数学人大模型、研发大模型。。。
盘古大模型L2场景模型
传送带义务检测、政务热线、台风路径预测、自动驾驶研发、报告解读、数字人直播、智能测试、重介选煤洗送、城市事件处理、降水预测、车辆辅助设计、辅助医疗、智能问答、智能运维。。。
大模型行业开发套件
国内外大模型产业闭源化趋势
ChatGPT4付费开通plus
Google Gemini 以开放API形式对外提供使用
Anthropic Claude
讯飞星火、百度文心一言、阿里通义千问
之后开源趋势
DeepSeek、OpenAI GPT-o3-mini、GPT-4o、文心一言
大模型领域闭源优势:直接将大模型基座作为大模型产业的核心价值,基于大模型基座之上向API开放进行转型,促使更多的大中小型组织更方便的介入大模型生态,基于闭源大模型基座通过垂直定制私有化场景大模型研发大模型产品,可降低各型组织介入大模型生态的维度,可简化大模型产业的研发难度,将大模型产品开发“有规则的程序化”,更有助于推动大模型产业更快速发展。
开源亦有优势,DeepSeek自R1发布即开源,全球各AI相关科研机构、公司迅速接入R1,各种R1能力开始对外提供。硅基流动、阿里云百炼、火山引擎等国内大模型能力服务产品迅速部署R1满血版,并正式提供R1模型API接入能力,每百万token16元使用R1深度推理。华为云2025.2.10发布全新Modelarts Studio大模型即服务平台,完成DeepSeek v3/R1向昇腾的适配,提供昇腾适配满血版R1深度推理服务。Monica等三方智能体开发平台接入R1开放能力。
AI Solution Architect技术栈
入门
传统机器学习算法
神经网络单层感知机Base Model:逻辑回归模型
深度学习与深度神经网络基础
深度神经网络基础算子模型:视觉模型基础算子:CNN卷积神经网络、序列模型基础算子:RNN循环神经网络
独立于传统有/无监督学习范式的第三类机器学习范式:生成式模型、半监督学习范式、强化学习范式、自监督学习范式
数字图像处理技术与计算机视觉Computer Vision:图像识别任务、目标检测任务、图像搜索任务、图像生成任务
文本处理技术与自然语言处理Natural Language Processing:机器翻译任务、文本生成任务、情感分析任务
预训练
Encoder-Decoder模型
注意力机制Attention:注意力机制算法基本原理、多头注意力机制、注意力机制多种变体
Transformer架构
核心
大模型数据功能
大模型算法架构核心原理
大模型基座预训练:基于国外开源大模型基座LLaMA低参版本实现完整大模型基座预训练复现、基于国内开源大模型基座GLM低参版本实现完整大模型基座预训练复现
基于大模型基座FM的大模型产品开发:提示工程、检索增强模型RAG、大模型主流开发框架、大模型微调实战、大模型推理与部署
非昇腾AI开闭源大模型训推加速解决方案:大模型训练加速方案、大模型推理加速方案、大模型压缩及量化方案
昇腾大模型全栈解决方案:昇腾AI Agent智能体发展规划方案、昇腾AI异构计算架构CANN解决方案、昇腾AI深度学习组建Mindx DL、GPU+cuda系大模型向NPU+CANN系昇腾AI的模型迁移实战、昇腾AI大模型训推加速解决方案:MindSpeed、昇腾AI大模型使能全流程开发套件:MindFormers、昇腾AI大模型推理框架:MindIE、昇腾AI大模型压缩加速工具:ModelSlim、华为智算中心解决方案介绍。
大模型安全治理
大模型产品、运营与商业模式闭环
基础技能知识储备:Python、高数、现代、概率统计、凸优化理论、机器学习算法(决策树、逻辑回归、SVM、集成学习算法)
————————————
仅用于本人学习
来源:网络

















 6282
6282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









