






在远程Linux服务器部署darknet
编译
首先通过putty或者其他工具登录到远程服务器
使用git下载源码
git clone https://github.com/pjreddie/darknet.git
再进入darknet文件夹
cd darknet
修改Makefile,根据服务器的配置进行相应的设置
vim Mkaefile
按下i进入编辑模式
其中
GPU=0
CUDNN=0
OPENCV=0
OPENMP=0
DEBUG=0
0表示不开启,1表示开始
若开启对应的对象,则需要在Makefile以下部分添加对应的路径
CC=gcc
CPP=g++
#下面的路径修改为自己对应的路径
NVCC=/usr/local/cuda11/bin/nvcc
GPU=1
其中nvidia的路径,若不清楚可通过find / -type d -iname "file_name"查找
ifep ($(GPU)),1)
# -I后面的路径修改为自己对应的路径
COMMON+= -DGPU -I/usr/local/cuda11/include/
CFLAGS+= -DGPU
# 修改为自己对应的路径
LDFLAGS+= -L/usr/local/cuda11/lib64/ -L/usr/lib64/nvidia -lcuda -lcudart -lcublas -lcurand
编辑完成后按下esc键退出编辑模式
再键入:wq保存后退出
进行编译
make
编译过程中若遇到
unsupported gpu architecture ‘compute_30’
或者
unsupported gpu architecture ‘sm_30’
的问题,可通过这篇博客解决
编译成功后输入./darknet应能得到输出usage:./darknet<function>
测试
首先在官网下载模型的权重文件
wget https://pjreddie.com/media/files/yolov3.weights
下载完成后确认该文件在darknet文件夹下

然后先vim cfg/yolov3.cfg进入该配置文件修改以下内容
#Testing
batch=1
subdivisions=1
#根据测试还是训练的模式决定注释的部分
#Training
#batch=64
#subdivisions=16
我们先进行测试,所以注释掉training的部分,否则直接执行测试命令会显示CUDA out of memory的错误
在darknet目录下执行
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
其中
./darknet表示当前目录
test表示检测的测试,不是训练
cfg/coco.data为配置文件,其中包含物体类别的数量,训练和测试文件的路径信息,生成的权重文件保存的路径等信息
cfg/yolov3.cfg为训练和测试过程的配置文件,即是上一步修改的文件
yolov3.weights就是下载的权重文件
data/dog.jpg表示进行测试的图片,data文件夹下有多张图片,可通过ls data/查看选择
执行命令后,显示以下信息即表示成功运行
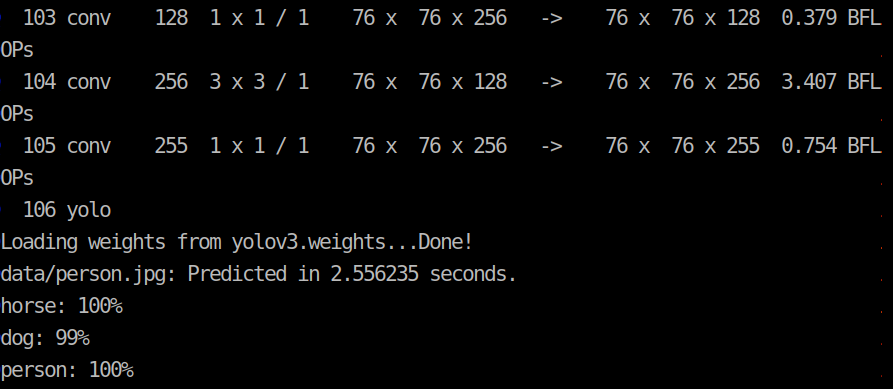
通过ls命令可看到darknet文件夹下有预测生成的predictions.jpg文件
再在本地终端使用scp命令下载到本地查看即可
在本地终端命令窗口输入
scp -P xxxx root@xxx.xxx.xxx.xxx:/home/usr/darknet/predictions.jpg /home/Downloads/
-P表示远程服务器的端口(port)号
root修改为自己的账户名称
@后修改为服务器对应的IP
:紧跟的路径为远程服务器端的文件路径
最后的文件路径为本地终端存储文件的路径
输入远程服务器密码,下载成功后即可查看输出图片

到此完毕。















 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









