









Multi-scale guided attention for medical image segmentation(医学图像分割的多尺度自导向注意)
特征融合策略:金字塔池化,空洞卷积金字塔
尽管这些策略可能有助于在不同尺度上捕获对象,但所有图像区域的上下文依赖都是同构的、非自适应的,忽略了不同类别的局部表示和上下文依赖之间的差异。
这些多上下文表示是手工设计的,缺乏对多上下文表示建模的灵活性。这使得在这些方法中无法充分利用整个图像中的长距离对象关系,这在许多医学图像分割问题中具有至关重要的意义。
Multi-scale attention maps
不依赖于UNet架构,而是依赖于特征提取,然后跟一个引导注意力块

第一部分是从图像中提取特征。为此,我们将输入图像输入到一个预先训练好的ResNet中,提取4个不同层次的特征图![]() 。这很有趣,因为低层次的特征往往出现在网络的开始阶段,而高层次的特性往往出现在网络的结束阶段,所以我们将能够访问到多种尺度的特征。使用bilinear插值将所有的特征图上采样到最大的一个。这给了我们4个相同大小的特征图,它们被连接并送入一个卷积块。这个convolutional block (multi-scale feature map)的输出与4个feature map的每一个都连接在一起,这给出了我们的attention blocks的输入,这个输入比之前的要复杂一些。
。这很有趣,因为低层次的特征往往出现在网络的开始阶段,而高层次的特性往往出现在网络的结束阶段,所以我们将能够访问到多种尺度的特征。使用bilinear插值将所有的特征图上采样到最大的一个。这给了我们4个相同大小的特征图,它们被连接并送入一个卷积块。这个convolutional block (multi-scale feature map)的输出与4个feature map的每一个都连接在一起,这给出了我们的attention blocks的输入,这个输入比之前的要复杂一些。
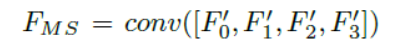
得到的多尺度特征图再分别和
进行concatenate操作,经过卷积后送入到Guided Attention模块中,得到注意力特征图(attention feature maps):A0,A1,A2,A3.
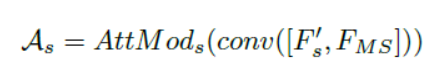
Spatial and Channel self-attention modules
如前所述,传统的深度分割模型中的接受域被简化为局部区域。
这限制了建模更广泛和更丰富的上下文表示的能力。
另一方面,可以将通道映射视为特定于类的响应,其中不同的语义响应相互关联。因此,另一种增强特定语义特征表示的策略是改善通道映射之间的依赖关系。为了解决标准cnn的这些限制,我们使用了中最近提出的位置和通道注意模块,如图2所示。

a).Position attention module(PAM):捕获长距离依赖,解决局部感受野的问题

3个分支,前两个分支B∈![]() C ∈
C ∈ ![]() D∈
D∈![]()
B,C经过reshape维度编程![]() 然后
然后![]() 得到
得到![]() ,得到的输出经过softmax得到S ∈ R ( H ∗ W ) ∗ ( H ∗ W ) 的相应图,其中s j i 表示feature上点j jj对i ii的影响
,得到的输出经过softmax得到S ∈ R ( H ∗ W ) ∗ ( H ∗ W ) 的相应图,其中s j i 表示feature上点j jj对i ii的影响
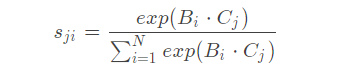
再由位置之间的相关性矩阵指导第三条分支D计算得到空间注意力图,与输入进行加权和
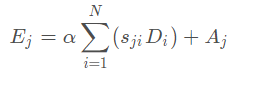
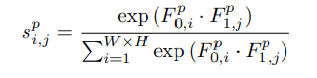
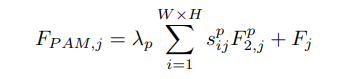
b).Channel Attention Module

CAM模块的操作和PAM非常相似不同之处是操作室基于通道的生成的attention map S 大小为C ∗ C ,最后的加权参数为β也是可学习的,得到的attention map上的点s j i 表示j jj通道对i ii的影响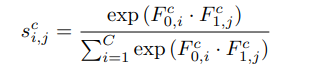
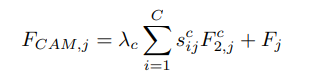
其中,λc控制通道注意图相对于输入特征图F
Guiding attention
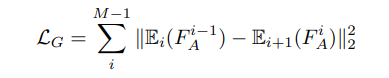
![]() 第i个编码器-解码器网络的编码表示
第i个编码器-解码器网络的编码表示![]() 为第i个双注意模块后产生的注意特征,M为迭代次数.
为第i个双注意模块后产生的注意特征,M为迭代次数.![]() 是语义引导注意模块F输入处的特征。具体而言,将第一个编码器-解码器(n = 0)重构的特征映射与第一个注意模块生成的自注意特征通过矩阵乘法组合生成
是语义引导注意模块F输入处的特征。具体而言,将第一个编码器-解码器(n = 0)重构的特征映射与第一个注意模块生成的自注意特征通过矩阵乘法组合生成![]() 。另外,为了保证重构的特征与位置通道注意模块输入处的特征相对应,强制编码器的输出靠近其输入。
。另外,为了保证重构的特征与位置通道注意模块输入处的特征相对应,强制编码器的输出靠近其输入。
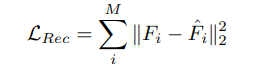
其中![]() 为重构后的特征映射,即第i个编解码网络的
为重构后的特征映射,即第i个编解码网络的![]() 。
。
由于引导注意模块在多个尺度上应用,所有模块的组合引导损失为: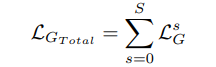
同样,总重建损失为:

其中LRec1和LRec2为引导注意模块第1块和第2块中编码器-解码器架构的重构损失。

Deep supervision

其中第一项是指在原始特征![]() 处的分割结果,第二项评估由注意特征提供的分割结果。在所有情况下,使用网络预测和地面真实标签之间的多类交叉熵作为分割损失。最终要优化的目标函数:
处的分割结果,第二项评估由注意特征提供的分割结果。在所有情况下,使用网络预测和地面真实标签之间的多类交叉熵作为分割损失。最终要优化的目标函数:
![]()
其中α, β和γ控制主损失函数中每一项的重要性















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









