







 该文通过三个示例展示了如何使用梯度下降法进行线性回归。首先,计算不同权重w下的均方误差;接着,模拟了单变量线性回归的梯度下降过程;最后,扩展到包括偏置b的情况。所有示例都用Python的numpy和matplotlib库实现。
该文通过三个示例展示了如何使用梯度下降法进行线性回归。首先,计算不同权重w下的均方误差;接着,模拟了单变量线性回归的梯度下降过程;最后,扩展到包括偏置b的情况。所有示例都用Python的numpy和matplotlib库实现。
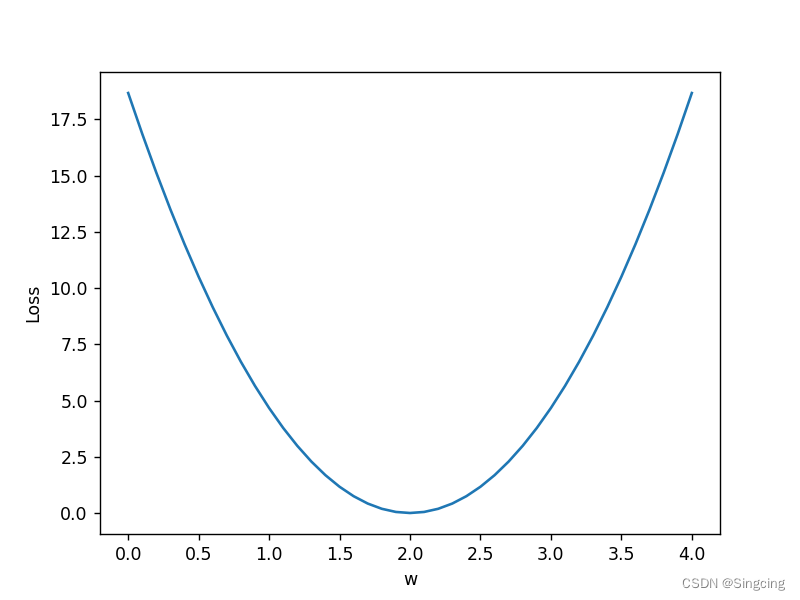
例1:使用不同的w,记录、计算均方误差
模型y=x*w
import numpy as np
import matplotlib.pyplot as plt
import sys
#大致模型为y=x*w
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
def forward(x):
return x*w
def loss(y_pred,y):
return np.power(y_pred-y,2)
w_list=[]
mse_list=[]
length=len(x_data)
for w in np.arange(0.0,4.1,0.1):
print(f"-----------w={w}-------------------------")
loss_sum=0
for x_val,y_val in zip(x_data,y_data):
y_pred=forward(x_val)
loss_val=loss(y_pred,y_val)
loss_sum+=loss_val
print(f'x_val={x_val},y_val={y_val},y_pred={y_pred},loss_val={loss_val}')
print(f"-----------MSE={loss_sum/length}----------")
w_list.append(w)
mse_list.append(loss_sum/length)
plt.plot(w_list,mse_list)
plt.ylabel("Loss")
plt.xlabel('w')
plt.show()
-----------w=0.0-------------------------
x_val=1.0,y_val=2.0,y_pred=0.0,loss_val=4.0
x_val=2.0,y_val=4.0,y_pred=0.0,loss_val=16.0
x_val=3.0,y_val=6.0,y_pred=0.0,loss_val=36.0
-----------MSE=18.666666666666668----------
-----------w=0.1-------------------------
x_val=1.0,y_val=2.0,y_pred=0.1,loss_val=3.61
x_val=2.0,y_val=4.0,y_pred=0.2,loss_val=14.44
x_val=3.0,y_val=6.0,y_pred=0.30000000000000004,loss_val=32.49
-----------MSE=16.846666666666668----------
-----------w=0.2-------------------------
x_val=1.0,y_val=2.0,y_pred=0.2,loss_val=3.24
x_val=2.0,y_val=4.0,y_pred=0.4,loss_val=12.96
x_val=3.0,y_val=6.0,y_pred=0.6000000000000001,loss_val=29.160000000000004
-----------MSE=15.120000000000003----------
.....
例2:y=x*w模型,梯度下降模拟线性回归
import numpy as np
import matplotlib.pyplot as plt
x_data=[1.0,2.0,3.0,4.0,5.0]
y_data=[2.0,4.0,6.0,8.0,10,0]
w=1.0
def forward(x):
return x*w
#mean square error
def loss(x_data,y_data):
loss_sum=0
for x,y in zip(x_data,y_data):
y_pred=forward(x)
loss_sum+=(y_pred-y)**2
return loss_sum/len(x_data)
#计算w的梯度,就是代价函数对w求导,这里的w只有一个,因为x只有一个列,x只有一个特征
def gradient(x_data,y_data):
gradient=0
for x,y in zip(x_data,y_data):
gradient+=(x*w-y)*x
return gradient/len(x_data)
mse_list=[]
w_list=[]
print("before training:",6,forward(6))
for epoch in range(100):
loss_val=loss(x_data,y_data)
mse_list.append(loss_val)
grad_val=gradient(x_data,y_data)
#梯度更新
w-=0.01*grad_val
w_list.append(w)
print(f"Epoch={epoch}, w={w},loss={loss_val}")
print("Predict(after training)",6,forward(6))
plt.plot(w_list,mse_list)
plt.ylabel("Loss")
plt.xlabel('w')
plt.show()before training: 6 6.0
Epoch=0, w=1.11,loss=11.0
Epoch=1, w=1.2079,loss=8.713099999999997
Epoch=2, w=1.295031,loss=6.901646510000001
Epoch=3, w=1.3725775900000001,loss=5.466794200571
Epoch=4, w=1.4415940551000002,loss=4.330247686272287
Epoch=5, w=1.5030187090390001,loss=3.429989192296278
....
Predict(after training) 6 11.99994786229447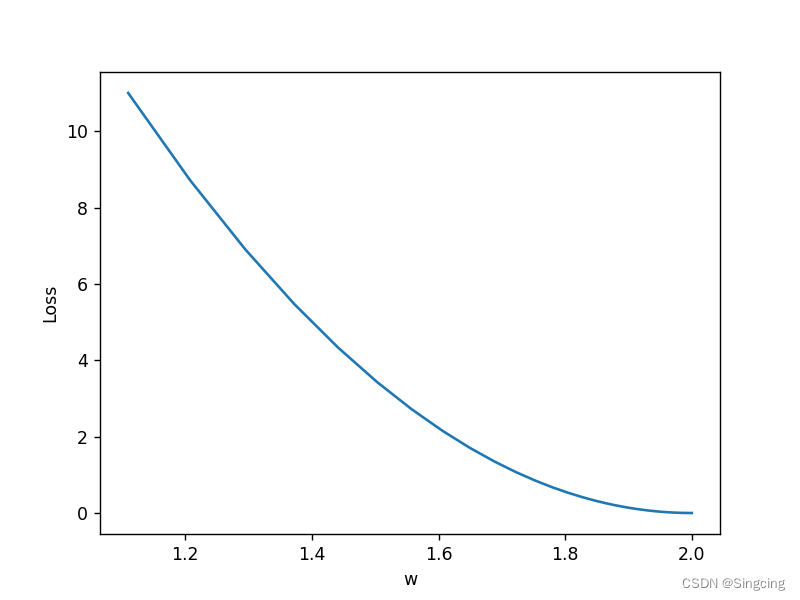
例3,y=x*w+b,梯度下降模拟线性回归
假设有以下X,W,Y,B

得到cost function和对应W的导数
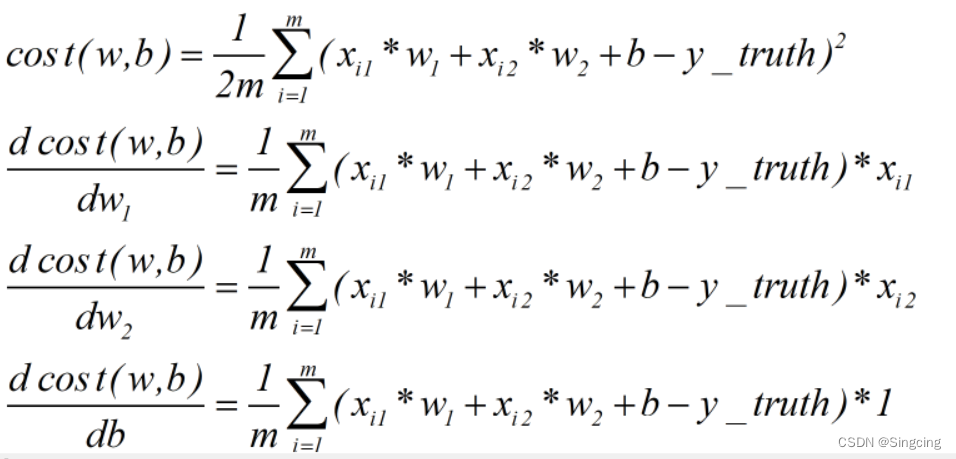
import matplotlib.pyplot as plt
import numpy as np
def reckonCost(X,y,theta):
m=y.shape[0]
inner=np.power( ( (X@theta)-y.T ) , 2)
return np.sum(inner) / (2*m)
# 定义梯度下降函数
def gradient_descent(X, y, theta, alpha, num_iters):
# m = len(y) # 样本数量
m=y.shape[0]
cost = np.zeros(num_iters)
for i in range(num_iters):
h = np.dot(X, theta) # 计算预测值
loss = h - y.T # 计算误差
# gradient = np.dot(X.T, loss) / m # 计算梯度
gradient =( X.T@loss ) / m
theta = theta - alpha * gradient # 更新参数
# cost[i]=reckonCost(X,y,theta)
return theta
# 定义线性回归函数
def linear_regression(x, y):
theta = np.zeros((2, 1)) # 初始化参数矩阵
alpha = 0.01 # 学习率
num_iters = 2000 # 迭代次数
# print(x.T)
# print(np.ones((len(y), 1)))
# print(theta)np.ones((len(y), 1)
m=y.shape[1]
ones=np.ones((m,1))
#X的维度:m*2
X = np.hstack( (ones, x.T) ) # 将x矩阵和全1矩阵按行拼接
print(X)
theta=gradient_descent(X, y, theta, alpha, num_iters)
return theta
def draw1(x,y,theta):
# fig, ax = plt.subplots(1,2)
fig,ax=plt.subplots(figsize=(12,8))
f=theta[1]*x+theta[0]
print("f",f)
ax.plot(x[0,:],f[0,:],label="predictoin",color="green")
# ax.scatter(x[0,:],y[0,:],label="Traiining Data")
ax.set_xlabel("xxx")
ax.set_ylabel("yyy")
ax.set_title("predicted y VS real y")
ax.scatter(x[0,:], y[0,:],color="blue")
# ax.plot(len(cost),cost,color="red")
plt.show()
def draw2(cost):
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(len(cost),cost,color="red")
plt.show()
if __name__=="__main__":
# 这里的x和y都是1*m的二维矩阵
x = np.array([[1, 2, 3, 4, 5]]) # 自变量
# y = np.array([[2, 4, 5, 4, 5]]) # 因变量
y=np.array([[4.5,7.5,8.5,11.5,12.5]])
theta = linear_regression(x, y) # 计算回归系数
print("回归系数theta:", theta)
# print("cost",cost)
# print(len(cost))
draw1(x,y,theta)
# draw3(x,y,theta,cost)
运行结果:
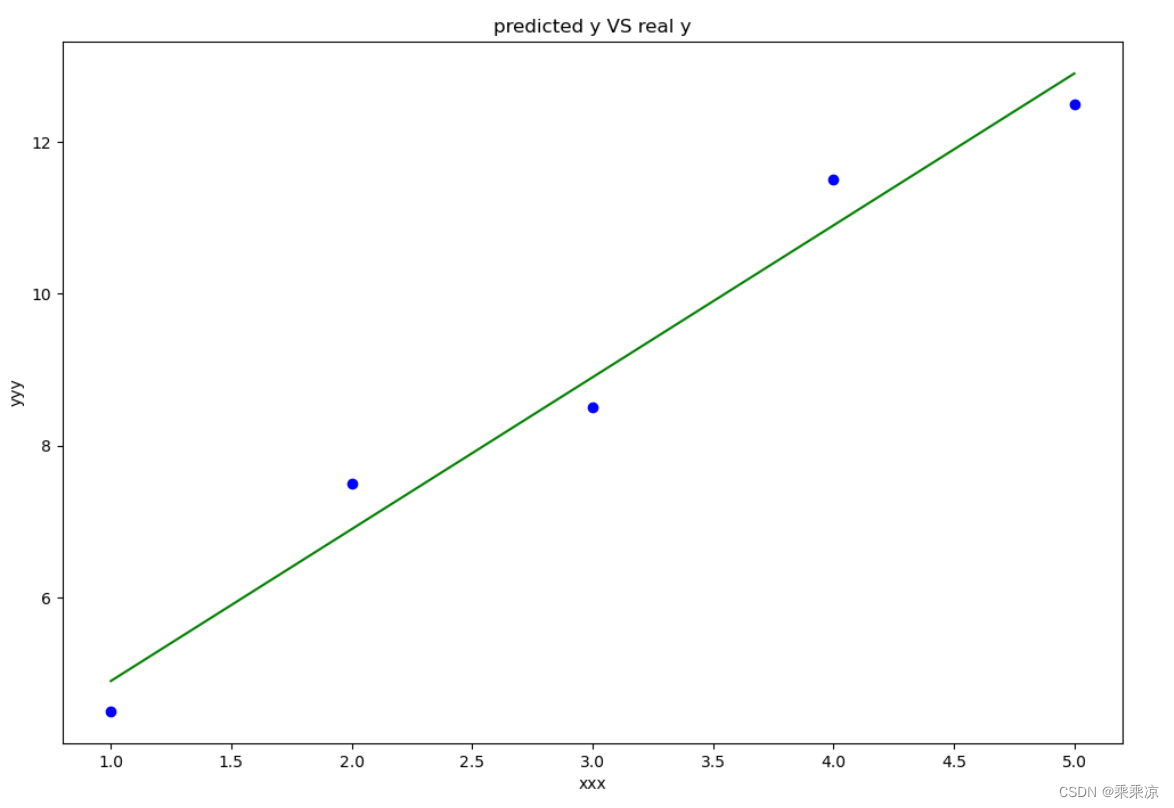















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









